PostgreSQLSQLHINT的使用说明
本文来自: http://www.023DNS.com/Database_mssql/5974.html
海晏网站建设公司创新互联,海晏网站设计制作,有大型网站制作公司丰富经验。已为海晏成百上千提供企业网站建设服务。企业网站搭建\成都外贸网站建设公司要多少钱,请找那个售后服务好的海晏做网站的公司定做!
PostgreSQL优化器是基于成本的 (CBO) , (当然, 如果开启了GEQO的话, 在关联表数量超过一定阈值后, 会采用GEQO, 这主要是由于在关联表太多的情况下, 穷举法可能带来巨大的PLAN开销, 所以GEQO输出的执行计划不一定是最优的)
本文要谈的和GEQO没什么关系, 主要是与CBO相关.
当PostgreSQL使用CBO时, 就一定能每次都输出最优的执行计划吗?
1. 首选我们看看CBO考察了哪些因素, 它是如何计算成本的?
成本和扫描方式, 关联方式, 操作符, 成本因子, 数据集等都有关, 具体的计算方法可参考如下代码:
src/backend/optimizer/path/costsize.c
我们这里简单的列举一下, 哪些因素会影响成本计算的结果, 具体算法见costsize.c :
-- 表有多少条记录, 影响全表扫描的 CPU处理记录的COST.
-- 表有多少个数据块, 影响扫描数据块的成本; 例如全表扫描, 索引扫描, 都需要扫描数据块.
-- 成本因子, 影响成本的计算结果; 例如连续或随机扫描单个数据块的成本因子, CPU从HEAP块处理一条记录的成本因子, 从INDEX块处理一条索引记录的成本因子, 执行一个操作符或函数的成本因子.
-- 数据存储物理顺序和索引顺序的离散度, 影响索引扫描的计算成本.
-- 内存大小, 影响索引扫描的计算成本.
-- 列统计信息(列宽, 空值比例, 唯一值比例, 高频值及其比例, bucket, 物理顺序和索引顺序的离散度, 数组的话还有数组的统计信息, 等), 影响选择性, 即结果集行数, 最终影响索引扫描的计算成本.
-- 创建函数或操作符时设置的成本.
2. 然后我们看看哪些因素CBO没有考虑进去, 还有哪些因素CBO考虑进去了, 但是可能会随时发生变化的.
PostgreSQL是否能动态的跟上这些变化?
2.1 PostgreSQL开启自动analyze, 可以适时更新的因素如下 :
-- 表有多少数据块, 记录数, 更新pg_class.relpages, pg_class.reltuples
-- 列统计信息, 数据存储物理顺序和索引顺序的离散度, 更新pg_statistic
2.2 静态配置因素 :
-- 实际可用作缓存的内存, 因为数据库所在的操作系统中可能还运行了其他程序, 可用作缓存的内存可能会发生变化. 即使没有运行其他程序, 当数据库会话中有大量使用了work_mem时, 也会造成可用做缓存的内存发生变化.
-- 创建函数或操作符时设置的成本, 当函数因为内部SQL或处理逻辑等变化, 可能导致函数本身的处理时间发生变化.
2.3 未考虑的因素 :
-- 块设备的的预读, 一般情况下一次读取时, 会预读128KB的数据.
# blockdev --getra /dev/sda
256
这又有什么影响呢? 如果你要读取的数据在连续的128KB数据块中, 那么只需要一次块设备的IO. 对于数据库来说, 扫描数据时扫多少个数据块可不管这个, 都会计算成本, 因此对于不同的块设备预读配置, 或者对于不同的块设备(如机械盘和SSD), 扫描成本可能不一样. PostgreSQL块设备的性能反映在成本计算方面, 就是seq_page_cost, random_page_cost.
这两个参数可以针对表空间设置, 也就是说, 对于不同的表空间, 可以设置不同的值, 比如我们有在SSD建立的表空间, 也有在普通机械盘上创建的表空间, 当然需要设置不同的seq_page_cost, random_page_cost值.
但是对于预读来说, 如果发生了变更, 对实际的性能会有细微的影响, 一般应该不会一天到晚变更块设备的read ahead吧.
2.4 generic plan cache, 即执行计划缓存.
PostgreSQL 通过choose_custom_plan选择重新规划执行计划还是使用缓存的执行计划, 当cached plan成本大于custom的平均成本时, 会选择custom plan , 所以当统计信息正确的情况下, 可以及时发现缓存执行计划的问题并及时规划新的执行计划.
详情请见 : src/backend/utils/cache/plancache.c
2.5 采样精度参数default_statistics_target , 影响bucket个数, 采样的精度.
经过一番分析, PostgreSQL使用了CBO, 就一定能"每次"都输出最优的执行计划吗?
1. 首选要确保人为设置成本因子准确, 另外还需要打开自动analyze(适时更新 列统计信息, 块, 离散度等),
2. 影响成本的因素还有一些是静态配置的 : 比如可用作BUFFER的内存, 函数的成本.
3. 还有没考虑的: 预读 (甚微).
在大多数情况下, 如果我们设置了合理的配置,那么 很少需要使用hint的. 除了以上2,3提到的两点.
同时hint也存在比较严重的弊端, 如果将hint写在程序代码中, 一旦需要变更执行计划, 还需要改程序代码, 不灵活.
当然, 我们不排除另一种用HINT的出发点, 比如调试. 我就想看看不同执行计划下执行效率是否和想象的一样.
(我们也可以使用开关来控制执行计划, 但是有HINT不是更直接一点嘛)
从长远来看, 如果仅仅从性能角度来说, 不断地改进数据库本身的优化器是比较靠谱的. 但是对于例如调试这样的需求, 有HINT更方便也是对的.
进入主题, 大多数Oracle用户在接触到PostgreSQL后, 会问PG有没有SQL hint?
为了让数据库按照用户的想法输出执行计划, 一般来说PostgreSQL提供了一些开关, 比如关闭全表扫描, 让它去走索引.
关闭索引扫描, 让它去走bitmap或全表扫描, 关闭嵌套循环, 让他去走hash join或merge join等.
但是仅仅有这些开关, 还不是非常的好用, 那么到底有没有直接点的HINT呢?
有一个插件可以解决你的问题,:pg_hint_plan.
pg_hint_plan利用PostgreSQL 开放的hook接口, 所以不需要改PG代码就实现了注入HINT的功能.
/*
* Module load callbacks
*/
void
_PG_init(void)
{
...
}
由于不同PostgreSQL 版本, plan部分的代码可能会不一致, 所以pg_hint_plan也是分版本发布的源码.
比如我要在PostgreSQL 9.4.1中测试一下这个工具.
接下来测试一下 :
安装
# wget http://iij.dl.sourceforge.jp/pghintplan/62456/pg_hint_plan94-1.1.3.tar.gz
# tar -zxvf pg_hint_plan94-1.1.3.tar.gz
# cd pg_hint_plan94-1.1.3
[root@db-172-16-3-150 pg_hint_plan94-1.1.3]# export PATH=/opt/pgsql/bin:$PATH
[root@db-172-16-3-150 pg_hint_plan94-1.1.3]# which psql
/opt/pgsql/bin/psql
[root@db-172-16-3-150 pg_hint_plan94-1.1.3]# psql -V
psql (PostgreSQL) 9.4.1
# gmake clean
# gmake
# gmake install
[root@db-172-16-3-150 pg_hint_plan94-1.1.3]# ll -rt /opt/pgsql/lib|tail -n 1
-rwxr-xr-x 1 root root 78K Feb 18 09:31 pg_hint_plan.so
[root@db-172-16-3-150 pg_hint_plan94-1.1.3]# su - postgres
$ vi $PGDATA/postgresql.conf
shared_preload_libraries = 'pg_hint_plan'
pg_hint_plan.enable_hint = on
pg_hint_plan.debug_print = on
pg_hint_plan.message_level = log
$ pg_ctl restart -m fast
postgres@db-172-16-3-150-> psql
psql (9.4.1)
Type "help" for help.
postgres=# create extension pg_hint_plan;
CREATE EXTENSION
用法举例说明 :
postgres=# create table a(id int primary key, info text, crt_time timestamp);
CREATE TABLE
postgres=# create table b(id int primary key, info text, crt_time timestamp);
CREATE TABLE
postgres=# insert into a select generate_series(1,100000), 'a_'||md5(random()::text), clock_timestamp();
INSERT 0 100000
postgres=# insert into b select generate_series(1,100000), 'b_'||md5(random()::text), clock_timestamp();
INSERT 0 100000
postgres=# analyze a;
ANALYZE
postgres=# analyze b;
ANALYZE
postgres=# explain select a.*,b.* from a,b where a.id=b.id and a.id<10;< p="">
QUERY PLAN
-----------------------------------------------------------------------
Nested Loop (cost=0.58..83.35 rows=9 width=94)
-> Index Scan using a_pkey on a (cost=0.29..8.45 rows=9 width=47)
Index Cond: (id < 10)
-> Index Scan using b_pkey on b (cost=0.29..8.31 rows=1 width=47)
Index Cond: (id = a.id)
(5 rows)
在没有pg_hint_plan时, 我们需要使用开关来改变PostgreSQL的执行计划
postgres=# set enable_nestloop=off;
SET
postgres=# explain select a.*,b.* from a,b where a.id=b.id and a.id<10;< p="">
QUERY PLAN
-----------------------------------------------------------------------------
Hash Join (cost=8.56..1616.65 rows=9 width=94)
Hash Cond: (b.id = a.id)
-> Seq Scan on b (cost=0.00..1233.00 rows=100000 width=47)
-> Hash (cost=8.45..8.45 rows=9 width=47)
-> Index Scan using a_pkey on a (cost=0.29..8.45 rows=9 width=47)
Index Cond: (id < 10)
(6 rows)
postgres=# set enable_nestloop=on;
SET
postgres=# explain select a.*,b.* from a,b where a.id=b.id and a.id<10;< p="">
QUERY PLAN
-----------------------------------------------------------------------
Nested Loop (cost=0.58..83.35 rows=9 width=94)
-> Index Scan using a_pkey on a (cost=0.29..8.45 rows=9 width=47)
Index Cond: (id < 10)
-> Index Scan using b_pkey on b (cost=0.29..8.31 rows=1 width=47)
Index Cond: (id = a.id)
(5 rows)
使用pg_hint_plan来改变PostgreSQL的执行计划,如下所示 :
postgres=# /*+
HashJoin(a b)
SeqScan(b)
*/ explain select a.*,b.* from a,b where a.id=b.id and a.id<10;< p="">
QUERY PLAN
-----------------------------------------------------------------------------
Hash Join (cost=8.56..1616.65 rows=9 width=94)
Hash Cond: (b.id = a.id)
-> Seq Scan on b (cost=0.00..1233.00 rows=100000 width=47)
-> Hash (cost=8.45..8.45 rows=9 width=47)
-> Index Scan using a_pkey on a (cost=0.29..8.45 rows=9 width=47)
Index Cond: (id < 10)
(6 rows)
postgres=# /*+ SeqScan(a) */ explain select * from a where id<10;< p="">
QUERY PLAN
------------------------------------------------------
Seq Scan on a (cost=0.00..1483.00 rows=10 width=47)
Filter: (id < 10)
(2 rows)
postgres=# /*+ BitmapScan(a) */ explain select * from a where id<10;< p="">
QUERY PLAN
---------------------------------------------------------------------
Bitmap Heap Scan on a (cost=4.36..35.17 rows=9 width=47)
Recheck Cond: (id < 10)
-> Bitmap Index Scan on a_pkey (cost=0.00..4.36 rows=9 width=0)
Index Cond: (id < 10)
(4 rows)
目前pg_hint_plan支持的HINT
http://pghintplan.sourceforge.jp/hint_list.html
The available hints are listed below.
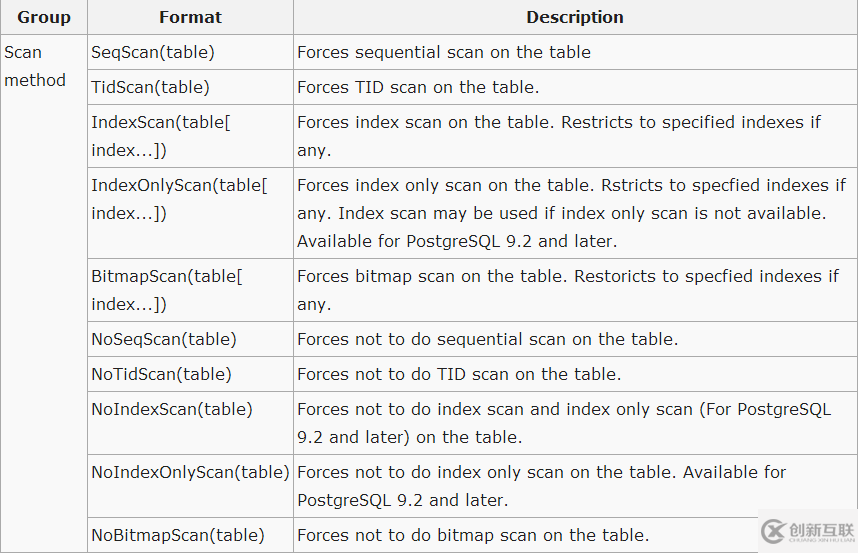

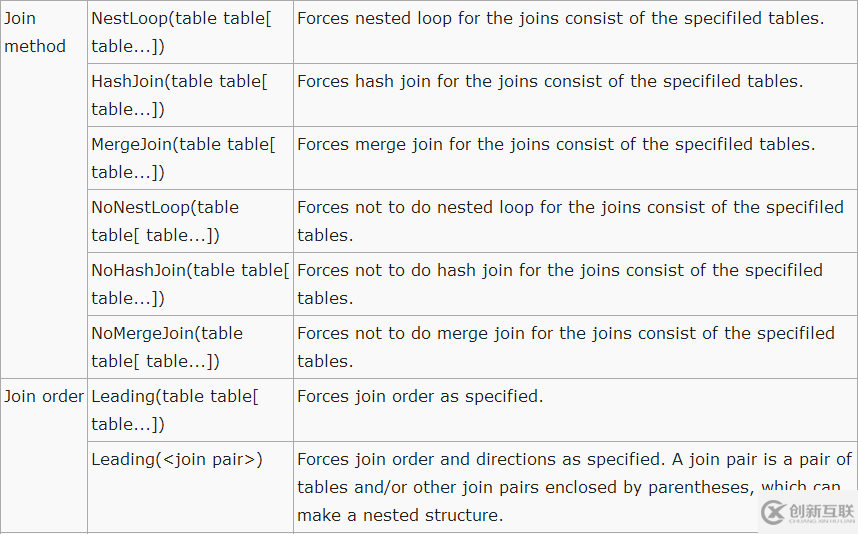

[参考]
1. http://pghintplan.sourceforge.jp/pg_hint_plan-en.html
2. http://pghintplan.sourceforge.jp/pg_hint_plan.html
3. http://pghintplan.sourceforge.jp/hint_list.html
4. http://pghintplan.sourceforge.jp/
5. src/backend/optimizer/path/costsize.c
6. src/backend/utils/cache/plancache.c
本文标题:PostgreSQLSQLHINT的使用说明
标题网址:https://www.cdcxhl.com/article34/jiedpe.html
成都网站建设公司_创新互联,为您提供小程序开发、标签优化、电子商务、面包屑导航、用户体验、营销型网站建设
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 网站内链怎么优化 2023-04-07
- 成都网站建设浅析网站内链优化,细节决定网站排名好于不好 2016-10-01
- 网站内链优化需要注意哪些问题? 2023-04-19
- 朝阳网络推广公司浅析网站内链结构SEO优化 2015-10-26
- SEO优化网站内链优化技巧站的好处 2015-03-16
- 成都网站建设提醒您,网站内链的功能不容小觑 2017-01-13
- 网站内链建设注意事项以及网站外链建设注意事项 2022-05-02
- 网站优化为什么要内链?网站内链优化如何做? 2014-08-25
- SEO技能篇-网站内链的形式及优化原则 2021-02-20
- 做网站内链需要注意哪些细节 2021-12-16
- 「文本布局方法」网站内链锚文本布局方法 2016-08-02
- 网站内链的重要性 2016-09-16