如何浅析CPU高速缓存和JVM内存模型
本篇文章为大家展示了如何浅析CPU高速缓存和JVM内存模型,内容简明扼要并且容易理解,绝对能使你眼前一亮,通过这篇文章的详细介绍希望你能有所收获。
公司主营业务:网站制作、成都网站制作、移动网站开发等业务。帮助企业客户真正实现互联网宣传,提高企业的竞争能力。创新互联是一支青春激扬、勤奋敬业、活力青春激扬、勤奋敬业、活力澎湃、和谐高效的团队。公司秉承以“开放、自由、严谨、自律”为核心的企业文化,感谢他们对我们的高要求,感谢他们从不同领域给我们带来的挑战,让我们激情的团队有机会用头脑与智慧不断的给客户带来惊喜。创新互联推出杭锦免费做网站回馈大家。
在java学习过程中,JVM的内存模型是非常重要的,今天,我们通过学习计算机的内存模型来帮助我们理解JVM内存。
一、计算机存储介质:
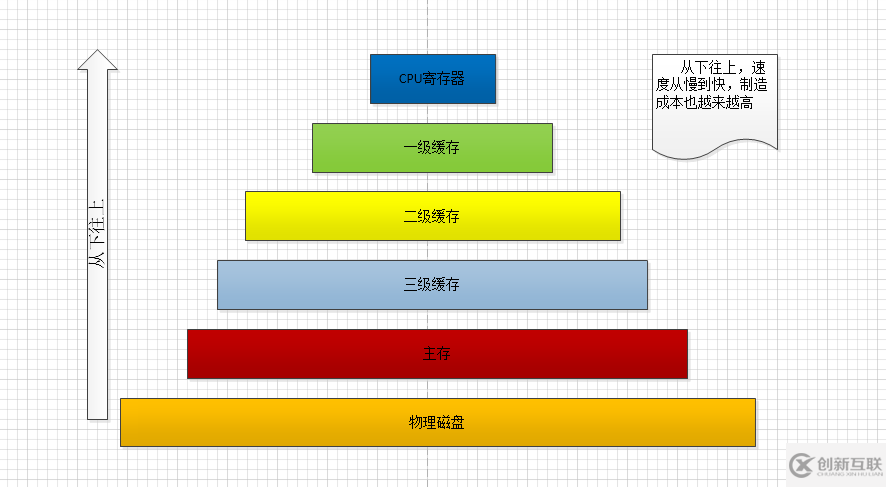
图一:计算机的简化存储介质
(1)、计算机中几种存储介质分类:
a.从下往上,硬盘、内存、缓存、寄存器;
b.高速缓存的访问读取速度大概为:1~X ns,
c.主存的读取速度:100ns
d.硬盘的读取速度:Xms
e.一般情况下高速缓存的访问速度是主存的 10~100 倍,而主存的访问速度则是硬盘的 1~10W 倍;
(2)、机械硬的读取访问时间分析:
a.寻道时间: 是指将读写磁头移动至正确的磁道上所需要的时间。平均寻道时间大致为 3-15ms。
b.旋转延迟时间: 盘片旋转将请求数据所在扇区移至读写磁头下方所需要的时间。旋转延迟取决于磁盘转速,通常使用磁盘旋转一周所需时间的 1/2 表示。比如,7200 rpm 的磁盘平均旋转延迟大约为 60 * 1000 / 7200 / 2 = 4.17ms,而转速为 15000 rpm 的磁盘其平均旋转延迟为 2ms。
c.数据传输时间: 完成传输所请求的数据所需要的时间,它取决于数据传输率,其值等于数据大小除以数据传输率。目前 IDE/ATA 能达到 133MB/s,SATA II 可达到 300MB/s 的接口数据传输率。数据传输时间通常远小于前两部分消耗时间。简单计算时可忽略。
(3)、扩展了解:顺序读取和随机读取
机械硬盘的磁头移动至正确的磁道上需要时间,随机读写时,磁头不停的移动,时间都花在了磁头寻道上,导致的就是性能不高。所以,对于机械硬盘来说,连续读写性很好,但随机读写性能很差。
(4)、局部性原理与磁盘预读
由于存储介质的特性,硬盘本身存取就比主存慢很多,再加上机械运动耗费,硬盘的存取速度往往是主存的几百分分之一,因此为了提高效率,要尽量减少磁盘 I/O。由于磁盘顺序读取的效率很高(不需要寻道时间,只需很少的旋转时间),因此对于具有局部性的程序来说,预读可以提高 I/O 效率。磁盘往往也不是严格按需读取,而是每次都会预读,即使只需要一个字节,磁盘也会从这个位置开始,顺序向后读取一定长度的数据放入内存。这样做的理论依据是计算机科学中著名的局部性原理:当一个数据被用到时,其附近的数据也通常会马上被使用。
备注:扩展知识其实是和高性能MySQL的读写效率有关,大家可以扩展研究一下。
二、CPU高速缓存
(1)、关于高速缓存的几个问题
a.什么是CPU高速缓存:CPU与内存之间的临时存储器
b.为什么需要CPU高速缓存:
1、它的容量比内存小的多但是交换速度却比内存要快得多。
2、高速缓存的出现主要是为了解决CPU运算速度与内存读写速度不匹配的矛盾,因为CPU运算速度要比内存读写速度快很多,这样会使CPU花费很长时间等待数据到来或把数据写入内存。在缓存中的数据是内存中的一小部分,但这一小部分是短时间内CPU即将访问的,当CPU调用大量数据时,就可先缓存中调用,从而加快读取速度。
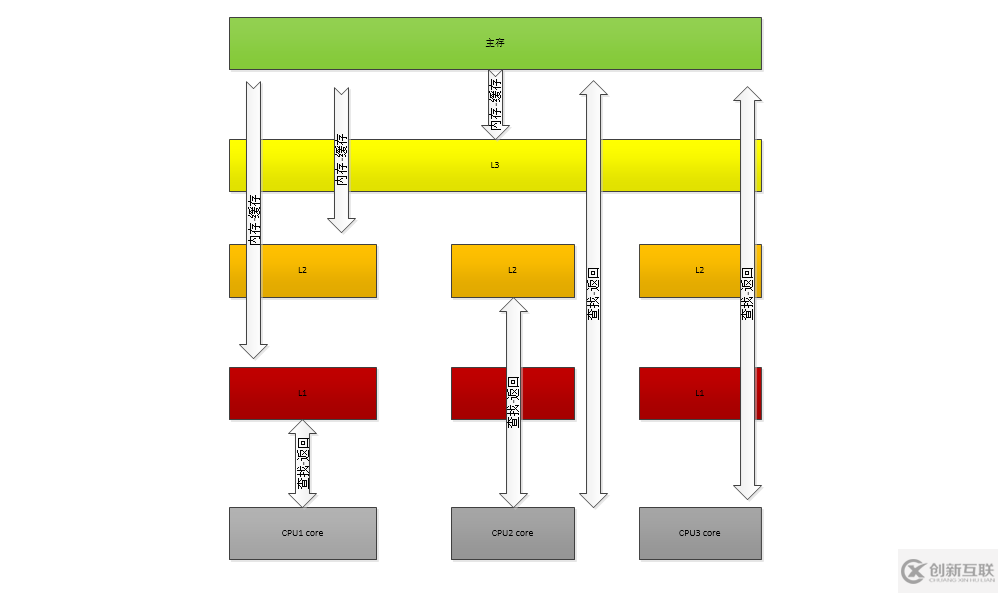
c.高速缓存模型
cpu缓存行->一级缓存->二级缓存->三级缓存->主存;
d.多线程下的缓存一致性问题:
缓存一致性协议。最出名的就是Intel 的MESI协议,MESI协议保证了每个缓存中使用的共享变量的副本是一致的。它核心的思想是:当CPU写数据时,如果发现操作的变量是共享变量,即在其他CPU中也存在该变量的副本,会发出信号通知其他CPU将该变量的缓存行置为无效状态,因此当其他CPU需要读取这个变量时,发现自己缓存中缓存该变量的缓存行是无效的,那么它就会从内存重新读取。
(2)、多CPU缓存与多线程缓存读写
1.每个cpu有自己单独的高速缓存区
2.访问跨cpu缓存数据很慢,当跨cup1访问另一个cpu2数据时,会把cpu2中的数据copy到cpu2中保留一个副本.
3.多个cpu缓存内可能包含相同的数据缓存行
4.cpu如果修改缓存行数据,将发出一个RFO(Request For Owner)请求, 获取这行数据的权限,对次行数据进行标识,其它cpu线程无法对此行数据进行操作
5.如果cpu数据变量副本引用的值发生变化,计算机会强制刷新引用此数据的各个cpu对应的缓存行,保证缓存行数据统一
6.缓存行数据更新不是以包含变量为最小单位,是以缓存行为最小单位。若缓存行包含了n个数据,其中一个的值被改变,那么整个缓存的其它n-1个值得都要重新加载
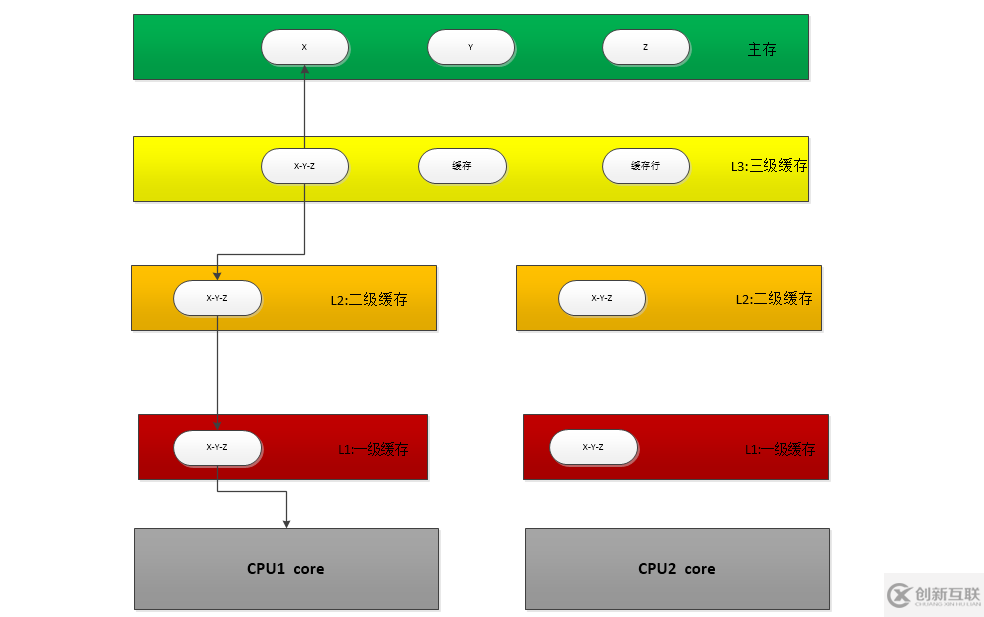
图二:多CPU缓存读写
(3)、多CPU读取过程:
1.缓存行变量数据 x,y,而且在其它cup缓存保存副本(cpu1,cpu2...)
2.cpu1修改x,cpu2修改y
3.cpu1首先获得执行权,修改x值成功
4.x值刷新会主内存
5.cpu2 x,y对应缓存行置为无效
6.cpu2..... 缓存行从内存获取最新x,y值
7.cpu2获得执行权,修改y成功
8.cpu1 缓存行重复4-6
三、了解JVM的内存模型:
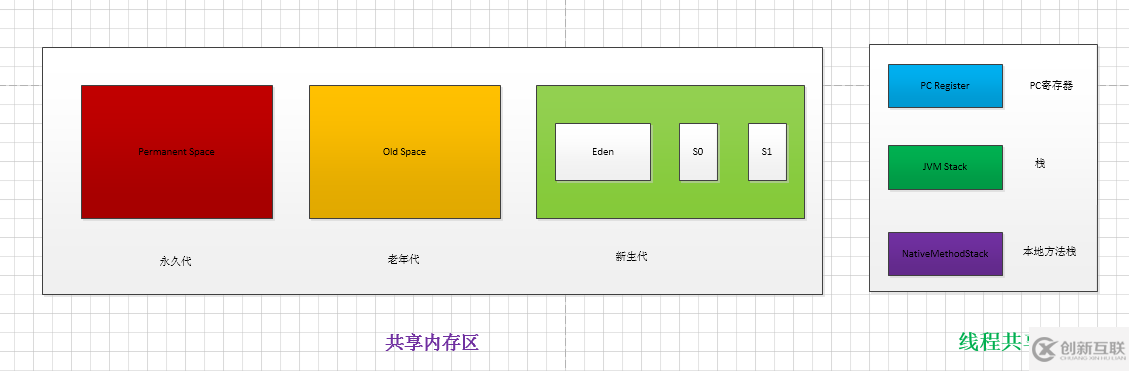
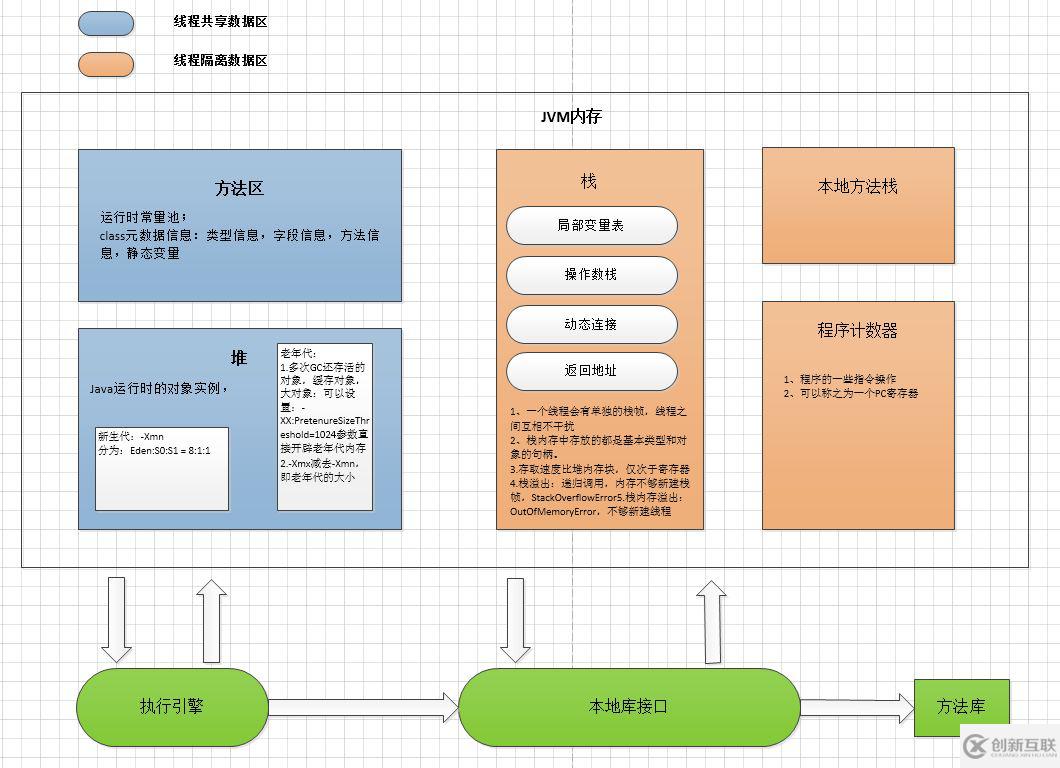
图三:JVM内存模型
根据计算机的内存模型,可以简单的想象一下JVM的内存模型设计,是不是同样需要一个主存,一个高速缓存,和一个CPU处理器。
JVM运行时的数据区的内存模型
<1>.线程数据共享区:方法区和堆
<2>.线程数据隔离区:每个线程都有一个独立的内存:栈,程序计数器(PC寄存器),本地方法栈;
(a).堆:存放的是运行时new出来的对象,数组,以及实例变量。堆中的内存分配还可以更加细化,由于jvm的垃圾回收分代收集算法,又将堆内存分为年轻代,老年代和永久代内存区;
年轻代:分为Eden和两个Serivious 区:可以通过参数配置来分配新生代的大小-Xmn
老年代:是多次YoungGC 还存活的对象,会被移动到老年代;
永久代:一些大对象,无法被GC的,会存放到永久代;
所以堆对应上的就相当于计算机的主存,所有的对象信息都会存储到这里。
(b).方法区:存放的是java类的元信息,数据结构,类的信息,和初始化的静态变量。方法区可以看作一个计算机三级缓存,程序的执行都会依赖获取类信息
(c).本地方法栈:本地方法的调用信息,相当于一个CUP的三级缓存
(d).栈内存:每个线程运行都会有独立的栈内存空间,主要存储的是程序运行时的对象引用和一些基本类型的变量信息,还有一个地址信息。所以栈内存相当于高速缓存中的一级缓存;
1、一个线程会有单独的栈帧,线程之间互相不干扰
2、栈内存中存放的都是基本类型和对象的句柄。
3、存取速度比堆内存块,仅次于寄存器
4、栈溢出:递归调用,内存不够新建栈帧,StackOverflowError
5.栈内存溢出:OutOfMemoryError,不够新建线程
(e).程序计数器:一些JVM的操作指令信息。相当于CPU处理器
不对的地方,烦请指正
图四、JVM内存模型
上述内容就是如何浅析CPU高速缓存和JVM内存模型,你们学到知识或技能了吗?如果还想学到更多技能或者丰富自己的知识储备,欢迎关注创新互联行业资讯频道。
网站名称:如何浅析CPU高速缓存和JVM内存模型
网站链接:https://www.cdcxhl.com/article34/ijhjse.html
成都网站建设公司_创新互联,为您提供网站设计、App开发、企业网站制作、动态网站、云服务器、响应式网站
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 响应式网站建设有哪些优点? 2020-11-28
- 从3个方面说明企业响应式网站建设的重要性 2014-12-20
- 关于响应式网站建设的四大要求 2023-03-13
- html5响应式网站拥有什么样的优势与特点 2018-03-15
- 为什么新建设的网站大量采用响应式网站? 2018-04-10
- 制作一个好的响应式网站需要什么要求? 2022-12-15
- 响应式网站建设需要考虑到哪些层面呢 2021-10-07
- 企业网站是否需要构建一个智能化响应式网站呢 2021-09-28
- 太仓响应式网站制作为什么比较贵 2022-12-02
- 成都企业网站建设为什么要做手机站,响应式网站有什么优势? 2015-01-21
- 响应式网站到底有哪些优势又存在哪些的缺点呢? 2022-06-03
- 响应式网站建站存在哪些问题? 2016-08-03