如何在java中使用elasticsearch进行分组
本篇文章给大家分享的是有关如何在java中使用elasticsearch进行分组,小编觉得挺实用的,因此分享给大家学习,希望大家阅读完这篇文章后可以有所收获,话不多说,跟着小编一起来看看吧。
公司主营业务:成都网站制作、成都做网站、移动网站开发等业务。帮助企业客户真正实现互联网宣传,提高企业的竞争能力。成都创新互联是一支青春激扬、勤奋敬业、活力青春激扬、勤奋敬业、活力澎湃、和谐高效的团队。公司秉承以“开放、自由、严谨、自律”为核心的企业文化,感谢他们对我们的高要求,感谢他们从不同领域给我们带来的挑战,让我们激情的团队有机会用头脑与智慧不断的给客户带来惊喜。成都创新互联推出孟津免费做网站回馈大家。
java连接elasticsearch 进行聚合查询进行相应操作
一:对单个字段进行分组求和
1、表结构图片:
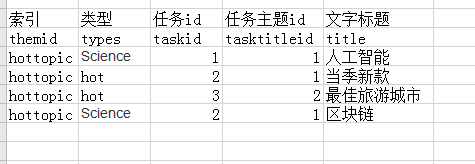
根据任务id分组,分别统计出每个任务id下有多少个文字标题
1.SQL:select id, count(*) as sum from task group by taskid;
java ES连接工具类
public class ESClientConnectionUtil {
public static TransportClient client=null;
public final static String HOST = "192.168.200.211"; //服务器部署
public final static Integer PORT = 9301; //端口
public static TransportClient getESClient(){
System.setProperty("es.set.netty.runtime.available.processors", "false");
if (client == null) {
synchronized (ESClientConnectionUtil.class) {
try {
//设置集群名称
Settings settings = Settings.builder().put("cluster.name", "es5").put("client.transport.sniff", true).build();
//创建client
client = new PreBuiltTransportClient(settings).addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName(HOST), PORT));
} catch (Exception ex) {
ex.printStackTrace();
System.out.println(ex.getMessage());
}
}
}
return client;
}
public static TransportClient getESClientConnection(){
if (client == null) {
System.setProperty("es.set.netty.runtime.available.processors", "false");
try {
//设置集群名称
Settings settings = Settings.builder().put("cluster.name", "es5").put("client.transport.sniff", true).build();
//创建client
client = new PreBuiltTransportClient(settings).addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName(HOST), PORT));
} catch (Exception ex) {
ex.printStackTrace();
System.out.println(ex.getMessage());
}
}
return client;
}
//判断索引是否存在
public static boolean judgeIndex(String index){
client= getESClientConnection();
IndicesAdminClient adminClient;
//查询索引是否存在
adminClient= client.admin().indices();
IndicesExistsRequest request = new IndicesExistsRequest(index);
IndicesExistsResponse responses = adminClient.exists(request).actionGet();
if (responses.isExists()) {
return true;
}
return false;
}
}java ES语句(根据单列进行分组求和)
//根据 任务id分组进行求和
SearchRequestBuilder sbuilder = client.prepareSearch("hottopic").setTypes("hot");
//根据taskid进行分组统计,统计出的列别名叫sum
TermsAggregationBuilder termsBuilder = AggregationBuilders.terms("sum").field("taskid");
sbuilder.addAggregation(termsBuilder);
SearchResponse responses= sbuilder.execute().actionGet();
//得到这个分组的数据集合
Terms terms = responses.getAggregations().get("sum");
List<BsKnowledgeInfoDTO> lists = new ArrayList<>();
for(int i=0;i<terms.getBuckets().size();i++){
//statistics
String id =terms.getBuckets().get(i).getKey().toString();//id
Long sum =terms.getBuckets().get(i).getDocCount();//数量
System.out.println("=="+terms.getBuckets().get(i).getDocCount()+"------"+terms.getBuckets().get(i).getKey());
}
//分别打印出统计的数量和id值根据多列进行分组求和
//根据 任务id分组进行求和
SearchRequestBuilder sbuilder = client.prepareSearch("hottopic").setTypes("hot");
//根据taskid进行分组统计,统计出的列别名叫sum
TermsAggregationBuilder termsBuilder = AggregationBuilders.terms("sum").field("taskid");
//根据第二个字段进行分组
TermsAggregationBuilder aAggregationBuilder2 = AggregationBuilders.terms("region_count").field("birthplace");
//如果存在第三个,以此类推;
sbuilder.addAggregation(termsBuilder.subAggregation(aAggregationBuilder2));
SearchResponse responses= sbuilder.execute().actionGet();
//得到这个分组的数据集合
Terms terms = responses.getAggregations().get("sum");
List<BsKnowledgeInfoDTO> lists = new ArrayList<>();
for(int i=0;i<terms.getBuckets().size();i++){
//statistics
String id =terms.getBuckets().get(i).getKey().toString();//id
Long sum =terms.getBuckets().get(i).getDocCount();//数量
System.out.println("=="+terms.getBuckets().get(i).getDocCount()+"------"+terms.getBuckets().get(i).getKey());
}
//分别打印出统计的数量和id值对多个field求max/min/sum/avg
SearchRequestBuilder requestBuilder = client.prepareSearch("hottopic").setTypes("hot");
//根据taskid进行分组统计,统计别名为sum
TermsAggregationBuilder aggregationBuilder1 = AggregationBuilders.terms("sum").field("taskid")
//根据tasktatileid进行升序排列
.order(Order.aggregation("tasktatileid", true));
// 求tasktitleid 进行求平均数 别名为avg_title
AggregationBuilder aggregationBuilder2 = AggregationBuilders.avg("avg_title").field("tasktitleid");
//
AggregationBuilder aggregationBuilder3 = AggregationBuilders.sum("sum_taskid").field("taskid");
requestBuilder.addAggregation(aggregationBuilder1.subAggregation(aggregationBuilder2).subAggregation(aggregationBuilder3));
SearchResponse response = requestBuilder.execute().actionGet();
Terms aggregation = response.getAggregations().get("sum");
Avg terms2 = null;
Sum term3 = null;
for (Terms.Bucket bucket : aggregation.getBuckets()) {
terms2 = bucket.getAggregations().get("avg_title"); // org.elasticsearch.search.aggregations.metrics.avg.InternalAvg
term3 = bucket.getAggregations().get("sum_taskid"); // org.elasticsearch.search.aggregations.metrics.sum.InternalSum
System.out.println("编号=" + bucket.getKey() + ";平均=" + terms2.getValue() + ";总=" + term3.getValue());
}以上就是如何在java中使用elasticsearch进行分组,小编相信有部分知识点可能是我们日常工作会见到或用到的。希望你能通过这篇文章学到更多知识。更多详情敬请关注创新互联行业资讯频道。
标题名称:如何在java中使用elasticsearch进行分组
文章地址:https://www.cdcxhl.com/article34/ggoise.html
成都网站建设公司_创新互联,为您提供品牌网站制作、软件开发、App设计、网站导航、响应式网站、外贸建站
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 域名注册注意事项 2022-06-14
- 注册域名和备案所需资料摘要 2016-12-21
- 域名注册如何选择域名服务商 2022-08-02
- 企业网站建设没有域名 选择域名注册时多考虑这些小心机 2022-05-21
- 网站建设之域名注册 2016-10-03
- .SITE域名注册量突破100万 2021-02-14
- 注册域名认证需要多长时间?域名注册认证需要什么? 2021-03-03
- 注册域名这种常见问题要了解 2016-11-14
- 嘉定网站制作开发-注册域名注意事项 2020-11-23
- 域名注册多少钱一个? 2021-03-18
- 关于域名注册和选择的几点建议技巧 2021-08-03
- 成都域名注册如何挑选网站域名? 2016-10-26