链表和C语言-创新互联
概念:链表是一种物理存储结构上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的 。
成都创新互联公司主要从事成都做网站、成都网站建设、网页设计、企业做网站、公司建网站等业务。立足成都服务蒙山,10余年网站建设经验,价格优惠、服务专业,欢迎来电咨询建站服务:028-86922220这与我们之前所了解的数组不同,数组在内存中开辟一块连续的空间,根据一个元素的位置就可以轻易地找到数组中其余元素的地址,而链表不同,链表每一个节点(链表的基本组成单位,可以理解为数组的一个元素)的地址并不是连续的,为了找到可以访问链表的每一个节点,我们需要在每个节点存储下一个节点的地址,也就是用一个指针来指向下一个节点。下图可以帮助我们理解链表的结构:

链表的每个节点可以理解为由两部分组成:节点存储的数据(data)和指向下一个节点地址的指针(next)。其中,链表的最后一个节点(尾节点)的指针(next)为NULL。
二、链表的分类实际中链表的结构非常多样,以下情况组合起来就有8种链表结构:
1.根据链表的指向可以分为:单向链表和双向链表
单向链表就是我们最开始介绍的,每个节点由data和next组成。而双向链表每个节点由data、next和prev(指向上一个节点的指针);双向链表的解决了链表插入删除节点时无法保存上一个节点地址的麻烦。(这在第三部分用C语言实现链表可以感受到)
2.根据链表是否带头可以分为:带头链表和不带头链表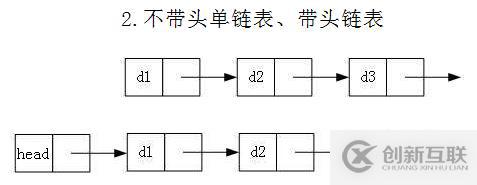
不带头链表就是我们最开始介绍的,第一个节点(头节点)存贮有效数据。而带头节点的头节点是一个不存储有效数据的节点,在有的教材上称为带哨兵位的头。
3.根据链表尾节点next的指向可以分为:单链表和循环单链表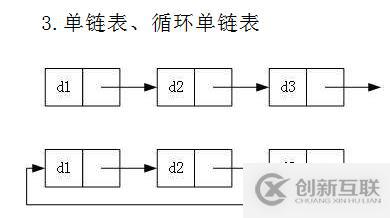
循环链表的特点是尾节点的next指向第一个节点,而不是NULL。
4.最常用的两种链表1. 无头单向非循环链表:结构简单,一般不会单独用来存数据。实际中更多是作为其他数据结构的子结构,如哈希桶、图的邻接表等等。另外这种结构在笔试面试中出现很多。
2.带头双向循环链表:结构最复杂,一般用在单独存储数据。实际中使用的链表数据结构,都是带头双向循环链表。另外这个结构虽然结构复杂,但是使用代码实现以后会发现结构会带来很多优势,实现反而简单了,后面我们代码实现了就知道了。

接下来我们用C语言来实现无头单项非循环链表。
1.链表的创建根据链表对结构的介绍,我们知道链表的最基本单位是节点,每个节点由两个变量(data和next)组成,因此,节点对应的类型应该是结构体,结构体成员分别是data和next。
#define SLTDataType int
typedef struct SinglyListNode
{
SLTDataType data;
struct SinglyListNode* next;
}SLTNode;
从图中我们发现,尾插进行的操作其实是三步:创建新节点(newnode),找到原链表的尾节点(tail),将newnode插入到tail之后。
由于在之后我们要经常用到创建新节点,所以我们将这个步骤封装成一个函数:BuyListNode
//x是插入节点的data值
SLTNode* BuyListNode(SLTDataType x)
{
SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));
newnode->data = x;
newnode->next = NULL;
return newnode;
}接下来,我们要寻找原链表的尾节点,定义一个tail从链表的第一个节点开始,逐步向后移动,直到最后一个节点,即tail->next==NULL时,tail即为尾节点。然后,将newnode插入到tail之后,也就是tail->next = newnode。
当然,我们对tail进行了访问,就要考虑tail会不会为NULL,也就是链表为空的情况,这时候,只要直接将newnode赋给链表就行。
//为什么是SLTNode** 这个二级结构体指针呢?
void SinglyListPushBack(SLTNode** pphead, SLTDataType x)
{
SLTNode* newnode = BuyListNode(x);
//if SinglyList is null
if (*pphead == NULL)
{
*pphead = newnode;
}
else
{
//step 1:find tail node
SLTNode* tail = *pphead;
while (tail->next != NULL)
{
tail = tail->next;
}
//step 2:add new node
tail->next = newnode;
}
}要注意,我们调用这个函数的方式应该如下:
void TestSinglyList1()
{
SLTNode* plist = NULL;
SinglyListPushBack(&plist, 1);
SinglyListPushBack(&plist, 2);
}我们传入的是一个结构体指针plist,想要改变plist,不能直接在SinglyListPushBack内部使用一个一级的结构体指针,因为这时,函数里的参数是形参,形参的改变不影响实参plist。想到用swap函数交换两个整形a、b的值时,我们传入a、b的地址:swap(&a,&b)。同样的,我们要传入plist的地址(&plist),一个一级指针的地址是一个二级指针,所以SinglyListPushBack调用的参数为SLTNode** pphead。
(2)在链表的头部插入数据--SinglyListPushFront
头插比起尾插更简单,只需将newnode放在原链表第一个节点之前:newnode->next = *pphead,然后将链表的头节点更改为newnode,*pphead = newnode。
void SinglyListPushFront(SLTNode** pphead, SLTDataType x)
{
SLTNode* newnode = BuyListNode(x);
newnode->next = *pphead;
*pphead = newnode;
}
尾删需要通过和尾插一样的方式找到尾节点tail,然后将倒数第二个节点作为新的尾节点。但是我们只根据tail是无法找到上一个节点的,因此我们要额外定义一个prev来记录上一个节点。最后,将倒数第二个节点作为新的尾节点:prev->next = NULL。
同样的,我们要注意prev和tail会不会为NULL的情况,当tail为NULL,链表为空;当prev为NULL,链表只有一个节点,对这两种情况单独讨论即可。
void SinglyListPopBack(SLTNode** pphead)
{
//链表为空
if (*pphead == NULL)
return;
//链表只有一个节点
if ((*pphead)->next == NULL)
{
free(*pphead);
*pphead = NULL;
}
//链表有两个及以上节点
else
{
SLTNode* tail = *pphead;
SLTNode* prev = NULL;
while (tail->next != NULL)
{
prev = tail;
tail = tail->next;
}
free(tail);
tail = NULL;
prev->next = NULL;
}
}
头删要进行的操作与头插类似,都是改变plist的指向,只需要让plist指向第二个节点即可。当然还是要注意考虑当*pphead为NULL,也就是链表为空时,就不用删除了。
为了更方便地释放第一个节点,我们额外定义一个next来记录第二个节点,next = (*pphead)->next,接着释放*pphead,最后将next赋给*pphead。(注意顺序,不要提前释放头节点,否则找不到第二个节点)
void SinglyListPopFront(SLTNode** pphead)
{
if (*pphead==NULL)
return;
SLTNode* next = (*pphead)->next;
free(*pphead);
*pphead = next;
}因为链表不适合二分查找、排序等操作,所以只要简单地从第一个节点开始遍历到尾节点,如果找到了指定数据,就返回该节点,如果没有指定数据,则返回NULL。
SLTNode* SinglyListFind(SLTNode* phead, SLTDataType key)
{
SLTNode* cur = phead;
while (cur)
{
if (cur->data == key)
return cur;
cur = cur->next;
}
return NULL;
}在删除某个节点时,记要删除的节点为pos,pos有SinglyListFind确定,先给定一个值key,由SinglyListFind找到值为key的节点后返回给pos,然后删除该节点。

删除这一步将pos的前一个节点(prev)连接到pos后一个节点上:prev->next = pos->next。由于我们无法直接由pos得到prev,所以每一次都要记录下来pos前的一个节点。并且,当pos为头节点时prev为NULL,我们只需要将进行之前头删的操作:*pphead = (*pphead)->next。
void SinglyListErase(SLTNode** pphead, SLTNode* pos)
{
if (*pphead != pos)
{
SLTNode* tmp = *pphead;
while (tmp->next != pos)
{
tmp = tmp->next;
}
tmp->next = pos->next;
}
else
*pphead = (*pphead)->next;
free(pos);
pos = NULL;
}由于在某个节点(pos)之前插入存在一个节点需要记录之前的节点,时间复杂度较高,我们只考虑在某个节点之后插入一个节点的情况,这里的pos和前面的删除一样,都来源于SinglyListFind。

在往尾部插入节点时,不用考虑插入的位置,只要将pos的next指向newnode,再将newnode的next指向原链表中pos的下一个节点。
void SinglyListInsert(SLTNode* pos, SLTDataType x)
{
SLTNode* newnode = BuyListNode(x);
newnode->next = pos->next;
pos->next = newnode;
}void SinglyListPrint(SLTNode* phead)
{
SLTNode* cur = phead;
while (cur != NULL)
{
printf("%d->", cur->data);
cur = cur->next;
}
printf("NULL");
}你是否还在寻找稳定的海外服务器提供商?创新互联www.cdcxhl.cn海外机房具备T级流量清洗系统配攻击溯源,准确流量调度确保服务器高可用性,企业级服务器适合批量采购,新人活动首月15元起,快前往官网查看详情吧
标题名称:链表和C语言-创新互联
标题URL:https://www.cdcxhl.com/article34/dhhhpe.html
成都网站建设公司_创新互联,为您提供电子商务、云服务器、网站导航、静态网站、用户体验、品牌网站制作
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- GOOGLE浏览器Chrome有红色页面提示要访问的网站包含恶意软件解决方案 2014-06-11
- 企业如何在Google推广上投放关键字? 2016-06-24
- Google优化内容质量和平台规则哪个重要? 2015-01-12
- Google AMP庆祝其成立三周年,如何开启。 2019-10-25
- Google关键词排名优化的6个技巧 2016-02-28
- google网站优化中熊猫算法的研究 2013-06-18
- 【SEO优化公司】google网站SEO优化入门技巧 2016-11-14
- 江苏网站建设谷歌代理商告诉你通过 Google AdMob 展示相关广告,从数以百万计的广告主那里获 2016-03-24
- google优化怎样做才能取得好的排名? 2016-03-10
- 大数据告诉你:Google排名高的是什么样的页面 ? 2023-05-05
- 新版Google Fonts,多种字体供网站建设者免费使用 2019-09-26
- SEO与广告结合可以得到更好的google推广效果 2016-03-18