在LevelDB数据库中如何实现磁盘多路归并排序-创新互联
这篇文章将为大家详细讲解有关在LevelDB数据库中如何实现磁盘多路归并排序,小编觉得挺实用的,因此分享给大家做个参考,希望大家阅读完这篇文章后可以有所收获。

在 LevelDB 数据库中高层数据下沉到低层时需要经历一次 Major Compaction,将高层文件的有序键值对和低层文件的多个有序键值对进行归并排序。磁盘多路归并排序算法的输入是来自多个磁盘文件的有序键值对,在内存中将这些文件的键值对进行排序,然后输出到一到多个新的磁盘文件中。
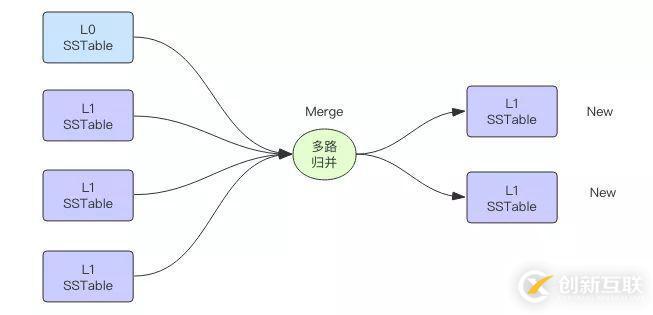
多路归并排序在大数据领域也是常用的算法,常用于海量数据排序。当数据量特别大时,这些数据无法被单个机器内存容纳,它需要被切分位多个集合分别由不同的机器进行内存排序(map 过程),然后再进行多路归并算法将来自多个不同机器的数据进行排序(reduce 过程),这是流式多路归并排序,为什么说是流式排序呢,因为数据源来源于网络套接字。
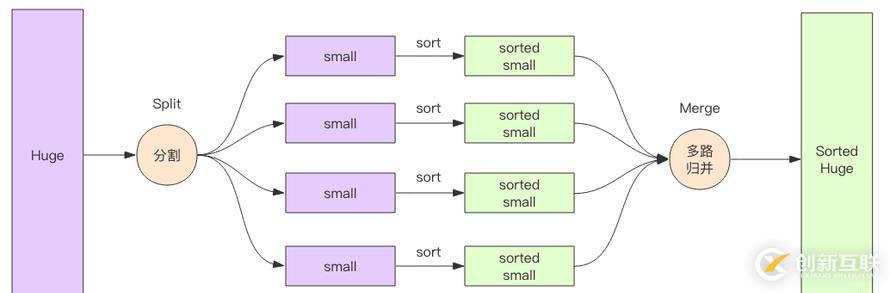
多路归并排序的优势在于内存消耗极低,它的内存占用和输入文件的数量成正比,和数据总量无关,数据总量只会线性正比影响排序的时间。
下面我们来亲自实现一下磁盘多路归并算法,为什么是磁盘,因为它的输入来自磁盘文件。
算法思路
我们需要在内存里维护一个有序数组。每个输入文件当前最小的元素作为一个元素放在数组里。数组按照元素的大小保持排序状态。
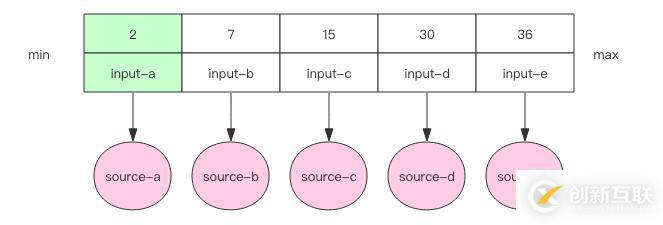
接下来我们开始进入循环,循环的逻辑总是从最小的元素下手,在其所在的文件取出下一个元素,和当前数组中的元素进行比较。根据比较结果进行不同的处理,这里我们使用二分查找算法进行快速比较。注意每个输入文件里面的元素都是有序的。
1. 如果取出来的元素和当前数组中的最小元素相等,那么就可以直接将这个元素输出。再继续下一轮循环。不可能取出比当前数组最小元素还要小的元素,因为输入文件本身也是有序的。
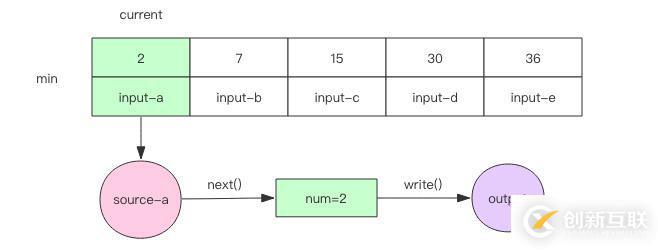
2. 否则就需要将元素插入到当前的数组中的指定位置,继续保持数组有序。然后将数组中当前最小的元素输出并移除。再进行下一轮循环。
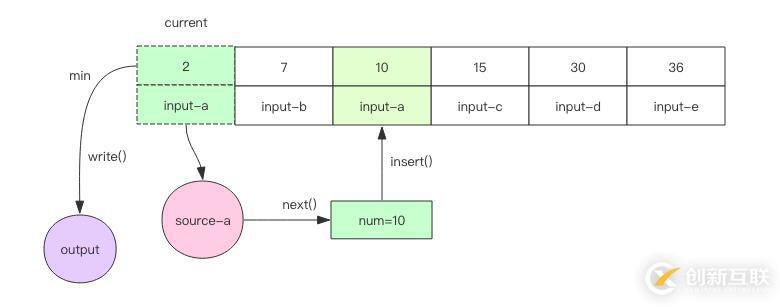
3. 如果遇到文件结尾,那就无法继续调用 next() 方法了,这时可以直接将数组中的最小元素输出并移除,数组也跟着变小了。再进行下一轮循环。当数组空了,说明所有的文件都处理完了,算法就可以结束了。
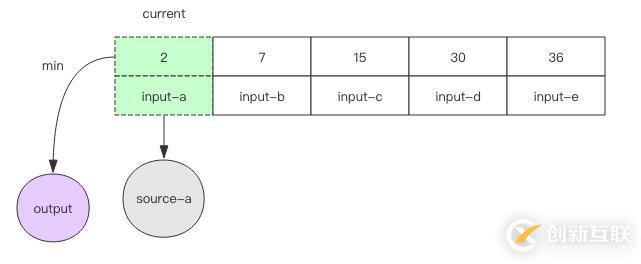
值得注意的是,数组中永远不会存在同一个文件的两个元素,如此才保证了数组的长度不会超过输入文件的数量,同时它也不会把没有结尾的文件挤出数组导致漏排序的问题。
二分查找
需要特别注意的是Java 内置了二分查找算法在使用上比较精巧。
public class Collections {
...
public static <T> int binarySearch(List<T> list, T key) {
...
if (found) {
return index;
} else {
return -(insertIndex+1);
}
}
...
}
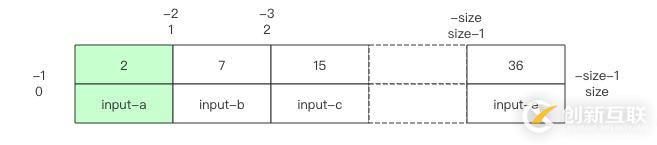
如果 key 可以在 list 中找到,那就直接返回相应的位置。如果找不到,它会返回负数,还不是简单的 -1,这个负数指明了插入的位置,也就是说在这个位置插入 key,数组将可以继续保持有序。
比如 binarySearch 返回了 index=-1,那么 insertIndex 就是 -(index+1),也就是 0,插入点在数组开头。如果返回了 index=-size-1,那么 insertIndex 就是 size,是数组末尾。其它负数会插入数组中间。
输入文件类
对于每一个输入文件都会创建一个 MergeSource 对象,它提供了 hasNext() 和 next() 方法用于判断和获取下一个元素。注意输入文件是有序的,下一个元素就是当前输入文件最小的元素。
hasNext() 方法负责读取下一行并缓存在 cachedLine 变量中,调用 next() 方法将 cachedLine 变量转换成整数并返回。
class MergeSource implements Closeable {
private BufferedReader reader;
private String cachedLine;
private String filename;
public MergeSource(String filename) {
this.filename = filename;
try {
FileReader fr = new FileReader(filename);
this.reader = new BufferedReader(fr);
} catch (FileNotFoundException e) {
}
}
public boolean hasNext() {
String line;
try {
line = this.reader.readLine();
if (line == null || line.isEmpty()) {
return false;
}
this.cachedLine = line.trim();
return true;
} catch (IOException e) {
}
return false;
}
public int next() {
if (this.cachedLine == null) {
if (!hasNext()) {
throw new IllegalStateException("no content");
}
}
int num = Integer.parseInt(this.cachedLine);
this.cachedLine = null;
return num;
}
@Override
public void close() throws IOException {
this.reader.close();
}
}
内存有序数组元素类
在排序前先把这个数组准备好,将每个输入文件的最小元素放入数组,并排序。
class Bin implements Comparable<Bin> {
int num;
MergeSource source;
Bin(MergeSource source, int num) {
this.source = source;
this.num = num;
}
@Override
public int compareTo(Bin o) {
return this.num - o.num;
}
}
List<Bin> prepare() {
List<Bin> bins = new ArrayList<>();
for (MergeSource source : sources) {
Bin newBin = new Bin(source, source.next());
bins.add(newBin);
}
Collections.sort(bins);
return bins;
}
输出文件类
关闭输出文件时注意要先 flush(),避免丢失 PrintWriter 中缓冲的内容。
class MergeOut implements Closeable {
private PrintWriter writer;
public MergeOut(String filename) {
try {
FileOutputStream out = new FileOutputStream(filename);
this.writer = new PrintWriter(out);
} catch (FileNotFoundException e) {
}
}
public void write(Bin bin) {
writer.println(bin.num);
}
@Override
public void close() throws IOException {
writer.flush();
writer.close();
}
}
准备输入文件的内容
下面我们来生成一系列输入文件,每个输入文件中包含一堆随机整数。一共生成 n 个文件,每个文件的整数数量在 minEntries 到 minEntries 之间。返回所有输入文件的文件名列表。
List<String> generateFiles(int n, int minEntries, int maxEntries) {
List<String> files = new ArrayList<>();
for (int i = 0; i < n; i++) {
String filename = "input-" + i + ".txt";
PrintWriter writer;
try {
writer = new PrintWriter(new FileOutputStream(filename));
ThreadLocalRandom rand = ThreadLocalRandom.current();
int entries = rand.nextInt(minEntries, maxEntries);
List<Integer> nums = new ArrayList<>();
for (int k = 0; k < entries; k++) {
int num = rand.nextInt(10000000);
nums.add(num);
}
Collections.sort(nums);
for (int num : nums) {
writer.println(num);
}
writer.flush();
writer.close();
} catch (FileNotFoundException e) {
}
files.add(filename);
}
return files;
}
排序算法
万事俱备,只欠东风。将上面的类都准备好之后,排序算法很简单,代码量非常少。对照上面算法思路来理解下面的算法就很容易了。
public void sort() {
List<Bin> bins = prepare();
while (true) {
// 取数组中最小的元素
MergeSource current = bins.get(0).source;
if (current.hasNext()) {
// 从输入文件中取出下一个元素
Bin newBin = new Bin(current, current.next());
// 二分查找,也就是和数组中已有元素进行比较
int index = Collections.binarySearch(bins, newBin);
if (index == 0) {
// 算法思路情况1
this.out.write(newBin);
} else {
// 算法思路情况2
if (index < 0) {
index = -(index+1);
}
bins.add(index, newBin);
Bin minBin = bins.remove(0);
this.out.write(minBin);
}
} else {
// 算法思路情况3:遇到文件尾
Bin minBin = bins.remove(0);
this.out.write(minBin);
if (bins.isEmpty()) {
break;
}
}
}
}
全部代码
读者可以直接将下面的代码拷贝粘贴到 IDE 中运行。
package leetcode;
import java.io.BufferedReader;
import java.io.Closeable;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.FileReader;
import java.io.IOException;
import java.io.PrintWriter;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import java.util.concurrent.ThreadLocalRandom;
public class DiskMergeSort implements Closeable {
public static List<String> generateFiles(int n, int minEntries, int maxEntries) {
List<String> files = new ArrayList<>();
for (int i = 0; i < n; i++) {
String filename = "input-" + i + ".txt";
PrintWriter writer;
try {
writer = new PrintWriter(new FileOutputStream(filename));
int entries = ThreadLocalRandom.current().nextInt(minEntries, maxEntries);
List<Integer> nums = new ArrayList<>();
for (int k = 0; k < entries; k++) {
int num = ThreadLocalRandom.current().nextInt(10000000);
nums.add(num);
}
Collections.sort(nums);
for (int num : nums) {
writer.println(num);
}
writer.close();
} catch (FileNotFoundException e) {
}
files.add(filename);
}
return files;
}
private List<MergeSource> sources;
private MergeOut out;
public DiskMergeSort(List<String> files, String outFilename) {
this.sources = new ArrayList<>();
for (String filename : files) {
this.sources.add(new MergeSource(filename));
}
this.out = new MergeOut(outFilename);
}
static class MergeOut implements Closeable {
private PrintWriter writer;
public MergeOut(String filename) {
try {
this.writer = new PrintWriter(new FileOutputStream(filename));
} catch (FileNotFoundException e) {
}
}
public void write(Bin bin) {
writer.println(bin.num);
}
@Override
public void close() throws IOException {
writer.flush();
writer.close();
}
}
static class MergeSource implements Closeable {
private BufferedReader reader;
private String cachedLine;
public MergeSource(String filename) {
try {
FileReader fr = new FileReader(filename);
this.reader = new BufferedReader(fr);
} catch (FileNotFoundException e) {
}
}
public boolean hasNext() {
String line;
try {
line = this.reader.readLine();
if (line == null || line.isEmpty()) {
return false;
}
this.cachedLine = line.trim();
return true;
} catch (IOException e) {
}
return false;
}
public int next() {
if (this.cachedLine == null) {
if (!hasNext()) {
throw new IllegalStateException("no content");
}
}
int num = Integer.parseInt(this.cachedLine);
this.cachedLine = null;
return num;
}
@Override
public void close() throws IOException {
this.reader.close();
}
}
static class Bin implements Comparable<Bin> {
int num;
MergeSource source;
Bin(MergeSource source, int num) {
this.source = source;
this.num = num;
}
@Override
public int compareTo(Bin o) {
return this.num - o.num;
}
}
public List<Bin> prepare() {
List<Bin> bins = new ArrayList<>();
for (MergeSource source : sources) {
Bin newBin = new Bin(source, source.next());
bins.add(newBin);
}
Collections.sort(bins);
return bins;
}
public void sort() {
List<Bin> bins = prepare();
while (true) {
MergeSource current = bins.get(0).source;
if (current.hasNext()) {
Bin newBin = new Bin(current, current.next());
int index = Collections.binarySearch(bins, newBin);
if (index == 0 || index == -1) {
this.out.write(newBin);
if (index == -1) {
throw new IllegalStateException("impossible");
}
} else {
if (index < 0) {
index = -index - 1;
}
bins.add(index, newBin);
Bin minBin = bins.remove(0);
this.out.write(minBin);
}
} else {
Bin minBin = bins.remove(0);
this.out.write(minBin);
if (bins.isEmpty()) {
break;
}
}
}
}
@Override
public void close() throws IOException {
for (MergeSource source : sources) {
source.close();
}
this.out.close();
}
public static void main(String[] args) throws IOException {
List<String> inputs = DiskMergeSort.generateFiles(100, 10000, 20000);
// 运行多次看算法耗时
for (int i = 0; i < 20; i++) {
DiskMergeSort sorter = new DiskMergeSort(inputs, "output.txt");
long start = System.currentTimeMillis();
sorter.sort();
long duration = System.currentTimeMillis() - start;
System.out.printf("%dms\n", duration);
sorter.close();
}
}
}
本算法还有一个小缺陷,那就是如果输入文件数量非常多,那么内存中的数组就会特别大,对数组的插入删除操作肯定会很耗时,这时可以考虑使用 TreeSet 来代替数组,读者们可以自行尝试一下。
关于“在LevelDB数据库中如何实现磁盘多路归并排序”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,使各位可以学到更多知识,如果觉得文章不错,请把它分享出去让更多的人看到。
网页题目:在LevelDB数据库中如何实现磁盘多路归并排序-创新互联
文章路径:https://www.cdcxhl.com/article34/dggjpe.html
成都网站建设公司_创新互联,为您提供网站改版、App开发、面包屑导航、网站制作、搜索引擎优化、企业网站制作
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 企业站使用静态网页还是使用动态网页分析 2016-08-08
- 网站生成全静态好吗? 2016-08-12
- 谈谈网站建设静态网站与动态网站的区别-网站建设创新互联科技 2021-09-27
- 谈谈网站建设:静态网站与动态网站各有特点 2022-07-07
- 企业网站制作怎样区分静态和动态网页呢? 2013-05-16
- 网站制作中动态与静态有什么区别 2017-06-08
- 为什么SEO网站优化必须使用静态页面 2013-04-22
- 成都网站建设-伪静态有什么用 2014-09-20
- 网站生成静态页面是不是会更好? 2016-03-07
- 网站建设时静态网页与动态网页的优缺点分析 2016-08-20
- 静态页面对seo优化的好处是什么? 2016-02-06
- 网站是否真的需要生成静态或伪静态? 2016-08-06