Java程序员面试必备——kafka的专业术语-创新互联

主题 + 客户端
发布订阅的对象是主题(Topic)
向主题发布消息的客户端应用程序称为生产者(Producer),生产者可以持续不断地向多个主题发送消息
订阅这些主题消息的客户端应用程序称为消费者(Consumer),消费者能够同时订阅多个主题的消息
- 生产者和消费者统称为客户端
服务端
Kafka的服务端由被称为Broker的服务进程构成,一个Kafka集群由多个Broker组成
Broker负责接收和处理客户端发送过来的请求,以及对消息进行持久化
- 多个Broker进程能够运行在同一台机器上,但更常见的做法是将不同的Broker分散运行在不同的机器上
- 这样如果集群中某一台机器宕机了,即使在它上面运行的所有Broker进程都挂掉了
- 其他机器上的Broker也依然能够对外提供服务,这是Kafka提供高可用的手段之一
备份
实现高可用的另一个手段是备份机制(Replication)
备份:把相同的数据拷贝到多台机器上,这些相同的数据拷贝在Kafka中被称为副本(Replica)
- 副本的数量是可以配置的,Kafka定义了两类副本:领导者副本(Leader Replica)和追随者副本(Follower Replica)
- 领导者副本:对外提供服务,对外指的是与客户端程序进行交互
- 生产者总是向领导者副本写消息
- 消费者总是从领导者副本读消息
- 追随者副本:被动地追随领导者副本,不能与外界交互
- 向领导者副本发送请求,请求领导者副本把最新生产的消息发给它,进而与领导者副本保持同步
- MySQL的从库是可以处理读请求的
- Master-Slave => Leader-Follower
- 副本机制可以保证数据的持久化或者消息不丢失,但没有解决伸缩性(Scalability)的问题
- 如果领导者副本积累了太多的数据以至于单台Broker机器无法容纳,该如何处理?
- 可以把数据分割成多份,然后保存在不同的Broker上,这种机制就是分区(Partitioning)
- MongoDB、Elasticsearch – Sharding
- HBase – Region
分区
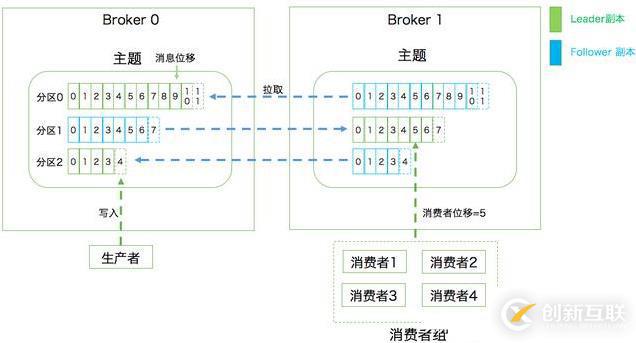
Kafka中的分区机制是将每个主题划分成多个分区(Partition),每个分区是一组有序的消息日志
生产者生产的每条消息只会被发送到一个分区中,Kafka的分区编号是从0开始的
副本是在分区这个层级定义的,每个分区下可以配置N个副本,只能有1个领导者副本和N-1个追随者副本
生产者向分区(分区的领导者副本)写入消息,每条消息在分区中的位置由位移(Offset)来表征,而分区位移总是从0开始
- 三层消息架构
- 第一层是主题层,每个主题可以配置M个分区,而每个分区又可以配置N个副本
- 第二层是分区层
- 每个分区的N个副本中只能有1个领导者副本,对外提供服务
- 其他N-1个副本是追随者副本,只能提供数据冗余
- 第三层是消息层,分区中包含若干条消息,每条消息的位移从0开始,依次递增
- 最后,客户端程序只能与分区的领导者副本进行交互
持久化
- Kafka使用消息日志(Log)来保存数据,一个日志是磁盘上一个只能追加写(Append-Only)消息的物理文件
- 只能追加写入,避免了缓慢的随机IO操作,改为性能较好的顺序IO操作,这是实现Kafka高吞吐量的一个重要手段
- Kafka需要定期删除消息以回收磁盘空间,可以通过日志片段(Log Segment)机制来实现
- 在Kafka底层,一个日志又被细分成多个日志段,消息被追加到当前最新的日志段中
- 当写满一个日志段后,Kafka会自动切分出一个新的日志段,并将老的日志段封存起来
- Kafka在后台有定时任务定期地检查这些老的日志段是否能够被删除,从而实现回收磁盘空间的目的
消费者
点对点模型(Peer to Peer,P2P):同一条消息只能被下游的一个消费者消费,其他消费者不能染指
- Kafka通过消费者组(Consumer Group)来实现P2P模型
- 消费者组:多个消费者实例共同组成一个组来消费一组主题
- 这组主题中的每个分区都只会被组内的一个消费者实例消费,其他消费者实例不能消费它
- 即消费者对分区有所有权
引入消费者组的目的:提高消费者端的吞吐量(TPS)
消费者实例(Consumer Instance):即可以是运行消费者应用的进程,也可以是一个线程
- 重平衡(Rebalance)
- 若组内的某个实例挂了,Kafka能够自动检测到,然后把这个挂掉的实例之前负责的分区转移给组内其他存活的消费者
- 重平衡引发的消费者问题很多,目前很多重平衡的Bug社区都无力解决
- 消费者位移(Consumer Offset):记录消费者当前消费到了分区的哪个位置,随时变化
- 分区位移:表征的是消息在分区内的位置,一旦消息被成功写入到一个分区上,消息的分区位移就固定了
小结
消息(Record):消息是Kafka处理的主要对象
主题(Topic):主题是承载消息的逻辑容器,实际使用中多用来区分具体的业务
分区(Partition):一个有序不变的消息序列,每个主题下有多个分区
消息位移(Offset):也叫分区位移,表示一条消息在分区中的位置,是一个单调递增且不变的值
- 副本(Replica)
- Kafka中同一条消息能够被拷贝到多个地方以提供数据冗余
- 副本分为领导者副本和追随者副本,副本在分区的层级下,每个分区可配置多个副本实现高可用
生产者(Producer):向主题发布消息的应用程序
消费者(Consumer):从主题订阅消息的应用程序
消费者位移(Consumer Offset):表征消费者的消费进度,每个消费者都有自己的消费者位移
消费者组(Consumer Group):多个消费者实例共同组成一个组,同时消费多个分区以实现高吞吐
- 重平衡(Rebalance)
- 消费者组内某个消费者实例挂掉后,其他消费者实例自动重新分配订阅分区的过程
- 重平衡是Kafka消费者端实现高可用的重要手段
写在最后
- 第一:看完点赞,感谢您的认可;
- ...
- 第二:随手转发,分享知识,让更多人学习到;
- ...
- 第三:记得点关注,每天更新的!!!
- ...

另外有需要云服务器可以了解下创新互联scvps.cn,海内外云服务器15元起步,三天无理由+7*72小时售后在线,公司持有idc许可证,提供“云服务器、裸金属服务器、高防服务器、香港服务器、美国服务器、虚拟主机、免备案服务器”等云主机租用服务以及企业上云的综合解决方案,具有“安全稳定、简单易用、服务可用性高、性价比高”等特点与优势,专为企业上云打造定制,能够满足用户丰富、多元化的应用场景需求。
新闻名称:Java程序员面试必备——kafka的专业术语-创新互联
URL链接:https://www.cdcxhl.com/article34/cosipe.html
成都网站建设公司_创新互联,为您提供微信公众号、网站导航、网站制作、网站内链、小程序开发、外贸建站
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- META标签优化如何做 2023-04-09
- 页面标签优化细水长流的SEO优化策略 2016-02-07
- 网站Tags标签优化的几大技巧 2022-06-08
- 谈谈网站Tags标签优化方法 2022-06-06
- 浅析网站tags标签优化的重要性 2022-07-27
- SEO优化之代码优化与标签优化 2015-02-08
- 搜索引擎推广怎样巧妙地运用标签优化网站? 2023-04-24
- 网站内页标签优化方法有哪些? 2023-04-30
- 深圳做网站其他标签优化 2022-06-06
- 网站seo中title标签优化技巧 2021-06-14
- 做好TAG标签优化,让更多长尾关键词获取排名! 2016-11-07
- 网站标签优化-关于H标签的优化策略 2016-11-10