HadoopHA双namenode搭建-创新互联
机器分布
创新互联建站是一家专业提供肥乡企业网站建设,专注与成都网站设计、做网站、H5响应式网站、小程序制作等业务。10年已为肥乡众多企业、政府机构等服务。创新互联专业网站制作公司优惠进行中。hadoop1 192.168.56121
hadoop2 192.168.56122
hadoop3 192.168.56123
准备安装包
jdk-7u71-linux-x64.tar.gz
zookeeper-3.4.9.tar.gz
hadoop-2.9.2.tar.gz
把安装包上传到三台机器的/usr/local目录下并解压
配置hosts
echo "192.168.56.121 hadoop1" >> /etc/hosts echo "192.168.56.122 hadoop2" >> /etc/hosts echo "192.168.56.123 hadoop3" >> /etc/hosts
配置环境变量
/etc/profile
export HADOOP_PREFIX=/usr/local/hadoop-2.9.2 export JAVA_HOME=/usr/local/jdk1.7.0_71
部署zookeeper
创建zoo用户
useradd zoo passwd zoo
修改zookeeper目录的属主为zoo
chown zoo:zoo -R /usr/local/zookeeper-3.4.9
修改zookeeper配置文件
到/usr/local/zookeeper-3.4.9/conf目录
cp zoo_sample.cfg zoo.cfg vi zoo.cfg tickTime=2000 initLimit=10 syncLimit=5 dataDir=/usr/local/zookeeper-3.4.9 clientPort=2181 server.1=hadoop1:2888:3888 server.2=hadoop2:2888:3888 server.3=hadoop3:2888:3888
创建myid文件放在/usr/local/zookeeper-3.4.9目录下,myid文件中只保存1-255的数字,与zoo.cfg中server.id行中的id相同。
hadoop1中myid为1
hadoop2中myid为2
hadoop3中myid为3
在三台机器启动zookeeper服务
[zoo@hadoop1 zookeeper-3.4.9]$ bin/zkServer.sh start
验证zookeeper
[zoo@hadoop1 zookeeper-3.4.9]$ bin/zkServer.sh status ZooKeeper JMX enabled by default Using config: /usr/local/zookeeper-3.4.9/bin/../conf/zoo.cfg Mode: follower
配置Hadoop
创建用户
useradd hadoop passwd hadoop
修改hadoop目录属主为hadoop
chmod hadoop:hadoop -R /usr/local/hadoop-2.9.2
创建目录
mkdir /hadoop1 /hadoop2 /hadoop3 chown hadoop:hadoop /hadoop1 chown hadoop:hadoop /hadoop2 chown hadoop:hadoop /hadoop3
配置互信
ssh-keygen ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop@hadoop1 ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop@hadoop2 ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop@hadoop3 #使用如下命令测试互信 ssh hadoop1 date ssh hadoop2 date ssh hadoop3 date
配置环境变量
/home/hadoop/.bash_profile
export PATH=$JAVA_HOME/bin:$HADOOP_PREFIX/bin:$HADOOP_PREFIX/sbin:$PATH
配置参数
etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/local/jdk1.7.0_71
etc/hadoop/core-site.xml
<!-- 指定hdfs的nameservice为ns --> <property> <name>fs.defaultFS</name> <value>hdfs://ns</value> </property> <!--指定hadoop数据临时存放目录--> <property> <name>hadoop.tmp.dir</name> <value>/usr/loca/hadoop-2.9.2/temp</value> </property> <property> <name>io.file.buffer.size</name> <value>4096</value> </property> <!--指定zookeeper地址--> <property> <name>ha.zookeeper.quorum</name> <value>hadoop1:2181,hadoop2:2181,hadoop3:2181</value> </property>
etc/hadoop/hdfs-site.xml
<!--指定hdfs的nameservice为ns,需要和core-site.xml中的保持一致 --> <property> <name>dfs.nameservices</name> <value>ns</value> </property> <!-- ns下面有两个NameNode,分别是nn1,nn2 --> <property> <name>dfs.ha.namenodes.ns</name> <value>nn1,nn2</value> </property> <!-- nn1的RPC通信地址 --> <property> <name>dfs.namenode.rpc-address.ns.nn1</name> <value>hadoop1:9000</value> </property> <!-- nn1的http通信地址 --> <property> <name>dfs.namenode.http-address.ns.nn1</name> <value>hadoop1:50070</value> </property> <!-- nn2的RPC通信地址 --> <property> <name>dfs.namenode.rpc-address.ns.nn2</name> <value>hadoop2:9000</value> </property> <!-- nn2的http通信地址 --> <property> <name>dfs.namenode.http-address.ns.nn2</name> <value>hadoop2:50070</value> </property> <!-- 指定NameNode的元数据在JournalNode上的存放位置 --> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://hadoop1:8485;hadoop2:8485;hadoop3:8485/ns</value> </property> <!-- 指定JournalNode在本地磁盘存放数据的位置 --> <property> <name>dfs.journalnode.edits.dir</name> <value>/hadoop1/hdfs/journal</value> </property> <!-- 开启NameNode故障时自动切换 --> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> <!-- 配置失败自动切换实现方式 --> <property> <name>dfs.client.failover.proxy.provider.ns</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <!-- 配置隔离机制,如果ssh是默认22端口,value直接写sshfence即可 --> <property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <!-- 使用隔离机制时需要ssh免登陆 --> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/home/hadoop/.ssh/id_rsa</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/hadoop1/hdfs/name,file:/hadoop2/hdfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/hadoop1/hdfs/data,file:/hadoop2/hdfs/data,file:/hadoop3/hdfs/data</value> </property> <property> <name>dfs.replication</name> <value>2</value> </property> <!-- 在NN和DN上开启WebHDFS (REST API)功能,不是必须 --> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> <property> <!-- List of permitted/excluded DataNodes. --> <name>dfs.hosts.exclude</name> <value>/usr/local/hadoop-2.9.2/etc/hadoop/excludes</value> </property>
etc/hadoop/mapred-site.xml
<property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> yarn-site.xml <!-- 指定nodemanager启动时加载server的方式为shuffle server --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <!-- 指定resourcemanager地址 --> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop1</value> </property>
etc/hadoop/slaves
hadoop1 hadoop2 hadoop3
首次启动命令
1、首先启动各个节点的Zookeeper,在各个节点上执行以下命令: bin/zkServer.sh start 2、在某一个namenode节点执行如下命令,创建命名空间 hdfs zkfc -formatZK 3、在每个journalnode节点用如下命令启动journalnode sbin/hadoop-daemon.sh start journalnode 4、在主namenode节点格式化namenode和journalnode目录 hdfs namenode -format ns 5、在主namenode节点启动namenode进程 sbin/hadoop-daemon.sh start namenode 6、在备namenode节点执行第一行命令,这个是把备namenode节点的目录格式化并把元数据从主namenode节点copy过来,并且这个命令不会把journalnode目录再格式化了!然后用第二个命令启动备namenode进程! hdfs namenode -bootstrapStandby sbin/hadoop-daemon.sh start namenode 7、在两个namenode节点都执行以下命令 sbin/hadoop-daemon.sh start zkfc 8、在所有datanode节点都执行以下命令启动datanode sbin/hadoop-daemon.sh start datanode
日常启停命令
#启动脚本,启动所有节点服务 sbin/start-dfs.sh #停止脚本,停止所有节点服务 sbin/stop-dfs.sh验证
jps检查进程
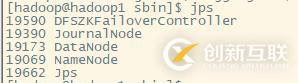
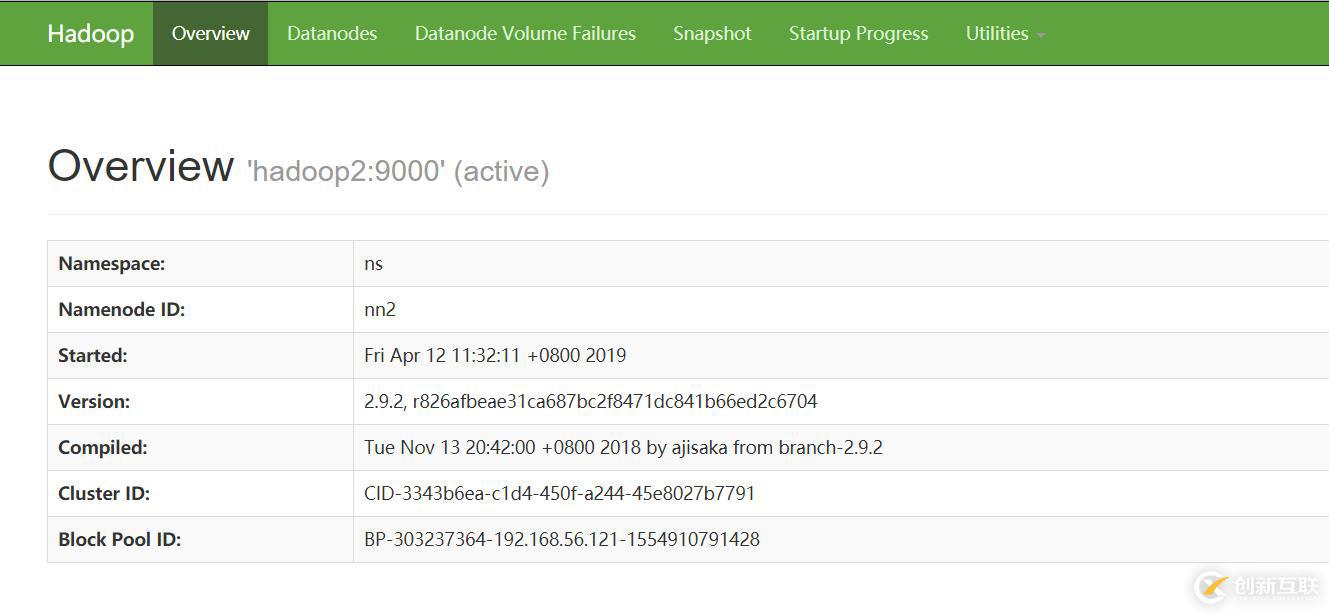
http://192.168.56.122:50070
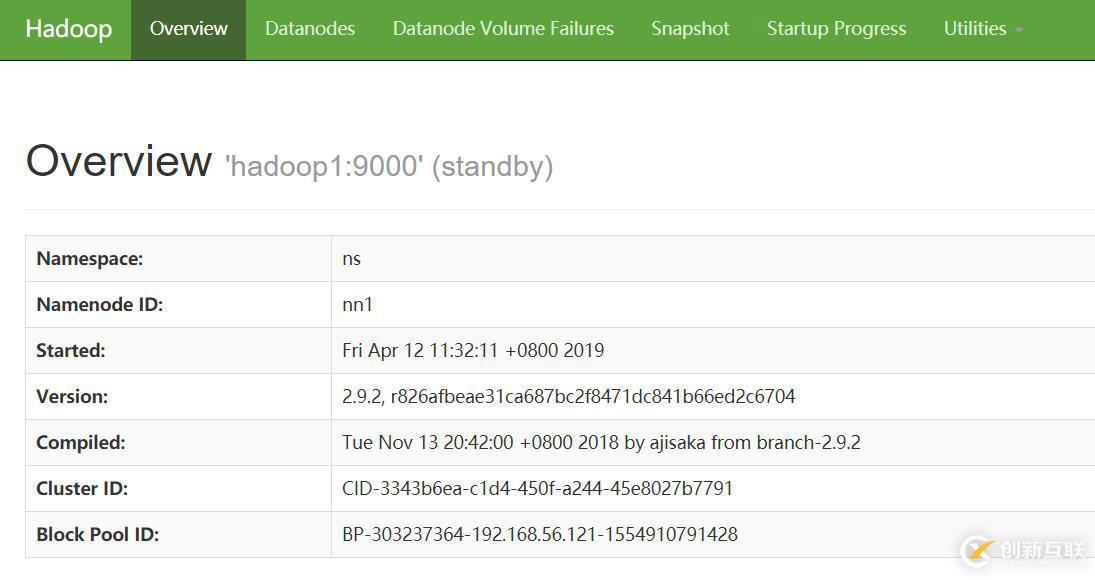
http://192.168.56.121:50070
测试文件上传下载
#创建目录 [hadoop@hadoop1 ~]$ hadoop fs -mkdir /test #验证 [hadoop@hadoop1 ~]$ hadoop fs -ls / Found 1 items drwxr-xr-x - hadoop supergroup 0 2019-04-12 12:16 /test #上传文件 [hadoop@hadoop1 ~]$ hadoop fs -put /usr/local/hadoop-2.9.2/LICENSE.txt /test #验证 [hadoop@hadoop1 ~]$ hadoop fs -ls /test Found 1 items -rw-r--r-- 2 hadoop supergroup 106210 2019-04-12 12:17 /test/LICENSE.txt #下载文件到/tmp [hadoop@hadoop1 ~]$ hadoop fs -get /test/LICENSE.txt /tmp #验证 [hadoop@hadoop1 ~]$ ls -l /tmp/LICENSE.txt -rw-r--r--. 1 hadoop hadoop 106210 Apr 12 12:19 /tmp/LICENSE.txt
参考:https://blog.csdn.net/Trigl/article/details/55101826
另外有需要云服务器可以了解下创新互联scvps.cn,海内外云服务器15元起步,三天无理由+7*72小时售后在线,公司持有idc许可证,提供“云服务器、裸金属服务器、高防服务器、香港服务器、美国服务器、虚拟主机、免备案服务器”等云主机租用服务以及企业上云的综合解决方案,具有“安全稳定、简单易用、服务可用性高、性价比高”等特点与优势,专为企业上云打造定制,能够满足用户丰富、多元化的应用场景需求。
网站名称:HadoopHA双namenode搭建-创新互联
本文URL:https://www.cdcxhl.com/article34/ccgpse.html
成都网站建设公司_创新互联,为您提供全网营销推广、企业建站、网站内链、电子商务、静态网站、App设计
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 分析网站建设网站设计中关于图象的属性 2022-01-30
- 网站设计-网络时代新营销方式 2023-03-26
- 电子商务网站设计技巧 2015-02-06
- 北京网站建设公司网站设计的工期 2022-07-30
- 企业官网网站设计的重要性 2013-10-02
- 网站设计中确定网站的整体风格 2016-11-12
- 网站设计常见的转换扼制你需要避免的错误 2022-10-23
- 网站设计如何提高用户体验设计的可用性? 2017-02-16
- 一个优秀的网站设计需要具备的因素 2022-12-03
- 专业高端网站设计网络公司:喔,优秀的网站原来这样制作的! 2022-09-01
- 北京网站设计如何搭建完整的企业网站 2020-12-20
- 手机网站设计适应8大浏览器的对比 2017-01-18