详解Python爬虫如何实现百度翻译功能过程-创新互联
小编这次要给大家分享的是详解Python爬虫如何实现百度翻译功能过程,文章内容丰富,感兴趣的小伙伴可以来了解一下,希望大家阅读完这篇文章之后能够有所收获。

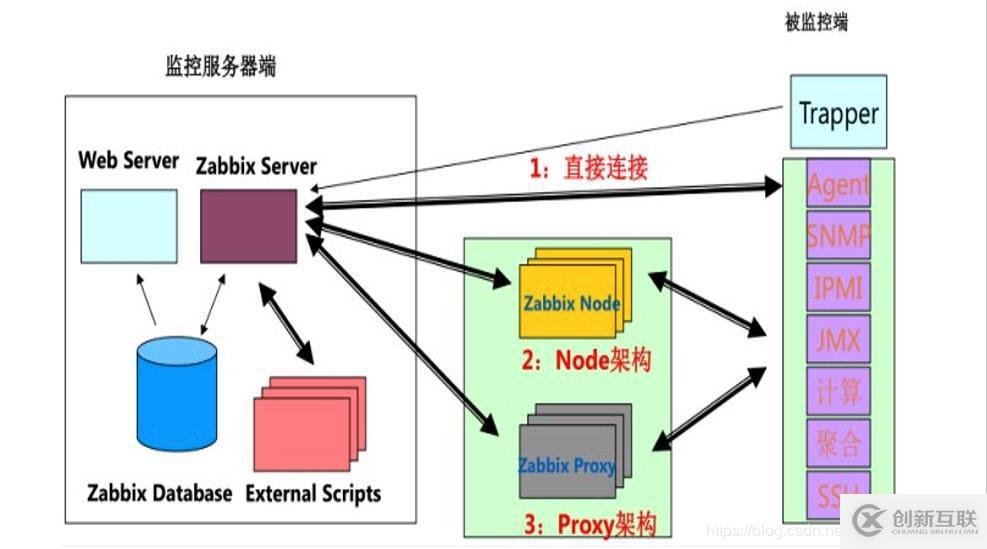
首先,需要简单的了解一下爬虫,尽可能简单快速的上手,其次,需要了解的是百度的API的接口,搞定这个之后,最后,按照官方给出的demo,然后写自己的一个小程序
打开浏览器 F12 打开百度翻译网页源代码:
我们可以轻松的找到百度翻译的请求接口为:http://fanyi.baidu.com/sug
然后我们可以从方法为POST的请求中找到参数为:kw:job(job是输入翻译的内容)
下面是代码部分:
from urllib import request,parse
import json
def translate(content):
url = "http://fanyi.baidu.com/sug"
data = parse.urlencode({"kw":content}) # 将参数进行转码
headers = {
'User-Agent': 'Opera/9.80 (Android 2.3.4; Linux; Opera Mobi/build-1107180945; U; en-GB) Presto/2.8.149 Version/11.10'
}
req = request.Request(url,data=bytes(data,encoding="utf-8"),headers=headers)
r = request.urlopen(req)
# print(r.code) 查看返回的状态码
html = r.read().decode('utf-8')
# json格式化
html = json.loads(html)
# print(html)
for k in html["data"]:
print(k["k"],k["v"])
if __name__ == '__main__':
content = input("请输入您要翻译的内容:")
translate(content)
当前名称:详解Python爬虫如何实现百度翻译功能过程-创新互联
本文链接:https://www.cdcxhl.com/article32/sppsc.html
成都网站建设公司_创新互联,为您提供定制开发、动态网站、电子商务、网站导航、面包屑导航、用户体验
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 外贸网站建设需要了解的知识 2022-12-29
- 成都外贸网站建设应该具备的功能有哪些? 2018-02-25
- 外贸网站建设时的注意事项 2022-11-14
- 如何进行高端外贸网站建设 2016-11-10
- 谈外贸网站建设用户体验的几个方面 2016-11-03
- 内贸网站建设和外贸网站建设的不同之处有哪些? 2022-05-01
- 成都外贸网站建设,推广需要同步跟进 2022-08-26
- 成都外贸网站建设关键词如何获得更好的排名 2022-05-30
- 聊聊外贸网站建设的关键之处是什么 2016-09-10
- 外贸网站建设需要做好哪些细节才能出彩? 2015-10-08
- 外贸网站建设这几项必须注意 2021-01-05
- 使用WordPress做外贸网站建设的注意事项 2022-06-02