MySQL数据库丢失数据的场景分析
本篇内容主要讲解“MySQL数据库丢失数据的场景分析”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“MySQL数据库丢失数据的场景分析”吧!
创新互联2013年至今,先为古冶等服务建站,古冶等地企业,进行企业商务咨询服务。为古冶企业网站制作PC+手机+微官网三网同步一站式服务解决您的所有建站问题。
MySQL数据库丢失数据场景分析
1.引擎层数据丢失场景
1.1.InnoDB丢失数据场景分析
InnoDB作为MySQL支持事务的存储引擎,同Oracle类似,事务提交时需要写redo、undo log。 InnoDB采用预写日志(Write Ahead Log)策略,数据页的变更会首先在内存中完成,同时将事务操作顺序记录到redo log中。完成上述的操作后表示该事务已经完成,可以返回给应用已提交的信息。 但此时实际被更改的数据页还保存在内存中(称为脏页),并没有flush到磁盘上即没有落地。刷盘操作一般会在达到一定条件后,触发checkpoint机制,此时会将内存中的脏页合并写入到磁盘里,完成数据同步。刷盘策略由innodb_flush_log_at_trx_commit参数控制的策略。
注:这里应为redo log 而非 binlog。
参数innodb_flush_log_at_trx_commit:
=0 :每秒 write os cache & flush disk
=1 :每次commit都 write os cache & flush disk
=2 :每次commit都 write os cache,然后根据innodb_flush_log_at_timeout参数(默认为1s) flush disk
innodb_flush_log_at_trx_commit=1最为安全,因为每次commit都保证redo log写入了disk。但是这种方式性能对DML性能来说比较低,在我们的测试中发现,如果设置为2,DML性能要比设置为1高10倍左右(所以在短信平台出现写入问题时,已将该参数设置为2)。
innodb_flush_log_at_trx_commit为0或2的区别主要体现在在mysql service crash或system crash时丢失事务的类型:
1)当mysql service crash时,设置为0就会丢失1秒内的所有已提交及未提交的事务,且无法回滚(因为redo log还记录在log buffer中,没有落盘到redo log)。而设置为2时,每次提交都会写入到os cache中,即使service crash掉,也只会丢失1秒内所有未提交的事务,而已提交的事务已经写入redo log中,可以回滚。
2)当system crash时,与上述类似。
因此,业内的共识是在一些DML操作频繁的场景下,参数innodb_flush_log_at_trx_commit设置为2。
虽然这样就存在丢数据的风险:当出现mysql service crash时,重启后InnoDB会进行crash recovery,则会丢失innodb_flush_log_at_timeout秒内的已提交的数据。未提交的数据则可由应用中的事务补偿机制处理。但是IO性能可以提高至少10倍。
PS:当开启了内部XA事务(默认开启),且开启binlog,情况稍有不一样。见下文。
1.2.MyISAM丢失数据场景分析
MyISAM存储引擎在我们的生产环境中基本没有使用。而且我们线上的5.6版本已将系统的数据字典表元数据表等系统表的默认存储引擎修改为InnoDB。
由于MyISAM不支持事务,且没有data cache,所有DML操作只写到OS cache中,flush disk操作均由OS来完成,因此如果服务器宕机,这部分数据肯定会丢失。
2.主从复制导致数据不一致的场景
MySQL主从复制原理:MySQL主库在事务提交时写binlog,并通过sync_binlog参数来控制binlog刷新到磁盘“落地”。从库中有两个线程: IO线程负责从主库读取binlog,并记录到本地的relay log中;SQL线程再将relay log中的记录应用到从库。如下图所示:
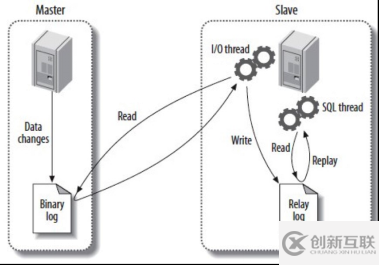
2.1.binlog刷新机制
master写binlog与innodb引擎写redo类似,由参数sync_binlog控制:
= 0 :表示MySQL不控制binlog的刷新,由文件系统控制binlog cache的刷盘操作
= N :表示每sync_binlog在N次事务提交后,MySQL调用文件系统的flush操作将binlog cache中的内容刷盘
sync_binlog=1时最安全,即表示每次事务提交,MySQL都会把binlog cache中的内容flush disk。这样在掉电等情况下,系统只有可能丢失1个事务的数据。但是sync_binlog为1时,系统的IO消耗非常大。
但是N的值也不易过大,否则在系统掉电时会丢失较多的事务。当前我们生产系统设置为100.
2.2.内部XA事务原理
MySQL的存储引擎与MySQL服务层之间,或者存储引擎与存储引擎之间的分布式事务,称之为MySQL内部XA事务。最为常见的内部XA事务存在与binlog与InnoDB存储引擎之间。在事务提交时,先写二进制日志,再写InnoDB存储引擎的redo log。对于这个操作要求必须是原子的,即需要保证两者同时写入。内部XA事务机制就是保证两者的同时写入。
XA事务的大致流程:
1)事务提交后,InnoDB存储引擎会先做一个PREPARE操作,将事务的XID写入到redo log中
2)写binlog
3)将该事务的commit信息写到redo log中
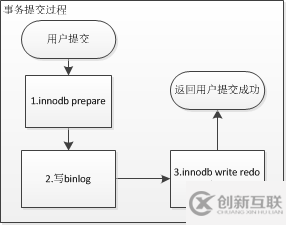
如果在步骤1和步骤2失败的情况下,整个事务会回滚,如果在步骤3失败的情况下,MySQL数据库在重启后会先检查PREPARE的XID事务是否已经提交,若没有,则在存储引擎层再进行一次提交操作。这样就保证了redo与binlog的一致性,防止丢失事务。
2.3.主库写redo log、binlog不实时造成的数据不一致
上面我们介绍了MySQL的内部XA事务流程,但是这个流程并不是天衣无缝的,redo的ib_logfile与binlog日志如果被设置非实时flush,就有可能出现以下数据不一致的情况:
1)Redo log的trx_prepare未写入,但binlog已写入,则crash recovery后从库数据比主库多。
2)Redo log的trx_prepare与commit都写入了,但binlog未写入,则crash recovery后从库数据量比主库少。
从目前来看,只能牺牲性能去换取数据的安全性,必须要设置redo log和binlog为实时刷盘,如果对性能要求很高,则考虑使用SSD来替代机械盘。
2.4.从库写redo log、binlog不实时造成的数据不一致
主库正常,但是从库出现异常情况宕机,如果数据丢失,从库的SQL线程还会重新应用吗?这个我们需要先了解SQL线程的机制。
从库读取主库的binlog日志后,需要落地3个文件:
relay log:即IO Thread读取过来的主库binlog,内容格式与主库的binlog一致
relay log info:记录SQL Thread应用的relay log的位置、文件号等信息
master info:记录IO Thread读取主库的binlog的位置、文件号、延迟等信息
因此如果当这3个文件如果不及时落地,则system crash后会导致数据的不一致。
在MySQL 5.6.2之前,从库记录的主库信息以及从库应用binlog的信息存放在文件中,即master.info与relay-log.info。在5.6.2版本之后,允许记录到table中,参数设置如下:
master-info-repository = TABLE relay-log-info-repository = TABLE 对应的表分别为mysql.slave_master_info与mysql.slave_relay_log_info,且这两个表均为innodb引擎表。
master info与relay info还有3个参数控制刷新:
1)sync_relay_log:默认为10000,即每10000次sync_relay_log事件会刷新到磁盘。为0则表示不刷新,交由OS的cache控制。
2)sync_master_info:若master-info-repository为FILE,当设置为0时,则每次sync_master_info事件都会刷新到磁盘,默认为10000次刷新到磁盘;若master-info-repository为TABLE,当设置为0时,则表不做任何更新,设置为1,则每次事件会更新表。默认为10000。
3)sync_relay_log_info:若relay_log_info_repository为FILE,当设置为0时,交由OS刷新磁盘,默认为10000次刷新到磁盘;若relay_log_info_repository为TABLE,则无论为任何值,每次evnet都会更新表。
如果参数设置如下:
sync_relay_log = 1
sync_master_info = 1 sync_relay_log_info = 1 master-info-repository = TABLE relay-log-info-repository = TABLE
将导致调用fsync()/fdatasync()随着master的事务的增加而增加,且若slave的binlog和redo也实时刷新的话,会带来很严重的IO性能瓶颈。
2.5.主库宕机后无法及时恢复造成的数据不一致
当主库出现故障后,binlog未及时拉到从库中,或者各个从库收到的binlog不一致(多数是由于网络原因)。且主库无法在第一时间恢复:
1)如果主库不切换,则应用只能读写主库。如果有读写分离的场景则会影响应用(读写分离场景中从库会从)。
2)如果将某一从库提升为新的主库(如MHA),那么原主库未来得及传到从库的binlog数据则会丢失,并且还涉及到下面2个问题:
a)各个从库之间接收到的binlog不一致,如果强制拉起一个从库做新主库,则从库之间数据会不一致。
b)原主库恢复正常后,由于新的主库日志丢弃了部分原主库的binlog日志,那么会多出来故障时期的这部分binlog。
对于上面出现的问题,业内已经有较成熟的方法来解决:
2.5.1确保binlog全部传到从库
方案一:使用semisync replication(半同步复制)插件。半同步复制的特点是从库中有一台提交后,主库才能提交事务。优点是保证了主、从库的数据一致性;缺点是对性能影响很大,依赖网络,适合tps压力小的场景。
方案二:双写binlog,通过DBDR OS层的文件系统复制到备机,或者使用共享盘保存binlog日志。优点和方案一类似,但此方案缺点较明显:
1)DBDR需要部署自己的服务
2)DBDR脑裂严重。在发生灾难场景时,往往不能正确切换。
3)需要建立heartbeat机制。保证被监控机的存活。
方案三:架构层面调整,引入消息队列做异步消息处理。比如保证数据库写成功后,再异步队列的方式写一份,部分业务可以借助设计和数据流解决。
2.5.2保证数据最小化丢失
上面的方案设计及架构比较复杂,如果能容忍数据的丢失,可以考虑使用MHA。
当master宕机后,MHA可以指定一台或者选延迟最低或者binlog pos最新的一台从库,并将其提升为主库。
MHA在切换master后,原master可以修复后以新master的slave角色重新加入集群。从而达到高可用。
3.总结
通过上面的总结分析,MySQL丢数据的场景众多,主要还是涉及到引擎层数据丢失场景、主从的数据不一致场景等。
根据分布式领域的CAP理论(Consistency一致性、Availability高可用性、Partition tolerance分区耐受性),在任何的分布式系统只能同时满足2点,没办法三者兼顾。MySQL的主从环境满足Availability,且在半同步场景中数据可以做到数据强一致性,可以满足Consistency。但是不能完全满足Partition tolerance。
因此现在业内对于事务(数据)丢失的处理有很多解决方案,如事务补偿机制、半同步复制、双写机制、异步消息队列等等。甚至,还可以针对业务对CAP中哪两者更有需求来选择相应的数据产品,如需要分区耐受性和高可用兼顾时,可以使用Cassandra等列式存储。都可以达到业务相应的数据一致性需求。
到此,相信大家对“MySQL数据库丢失数据的场景分析”有了更深的了解,不妨来实际操作一番吧!这里是创新互联网站,更多相关内容可以进入相关频道进行查询,关注我们,继续学习!
当前文章:MySQL数据库丢失数据的场景分析
浏览路径:https://www.cdcxhl.com/article32/josepc.html
成都网站建设公司_创新互联,为您提供ChatGPT、手机网站建设、域名注册、网页设计公司、商城网站、App开发
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 如何找合适的APP开发公司? 2023-01-18
- 如何才能确保APP开发项目能够按时交付 2021-05-18
- 成都app开发,依然是成都企业大众趋势所需 2022-07-22
- 成都app开发的报价流程是怎样的 2022-07-10
- 歙县app开发外包公司哪家好? 2020-12-11
- 江苏手机APP开发都有哪些类型 2020-12-09
- 成都app开发之短视频app,源码有什么特色功能? 2022-07-24
- APP开发需要花多长时间? 2023-02-25
- 山东租车APP开发如何让用户更方便 2020-12-31
- 点下您的手机,家装APP开发小鲜肉送货上门! 2022-08-17
- APP开发生态变了 归根结底还是钱的问题 2022-07-02
- app开发公司全力火开,合理规划APP定制策略 2023-03-20