Hadoop生态系统的存储格式CarbonData性能分析
本篇内容主要讲解“Hadoop生态系统的存储格式CarbonData性能分析”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“Hadoop生态系统的存储格式CarbonData性能分析”吧!
成都创新互联公司为您提适合企业的网站设计 让您的网站在搜索引擎具有高度排名,让您的网站具备超强的网络竞争力!结合企业自身,进行网站设计及把握,最后结合企业文化和具体宗旨等,才能创作出一份性化解决方案。从网站策划到成都网站建设、成都网站设计, 我们的网页设计师为您提供的解决方案。
一、评测环境
1)网络拓扑图
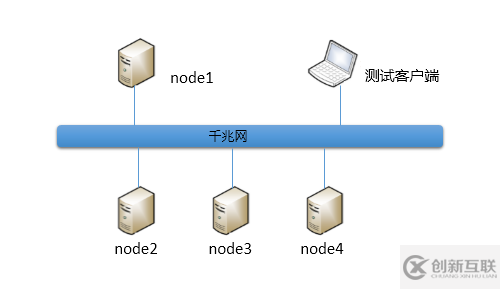
2)配置参数
服务器配置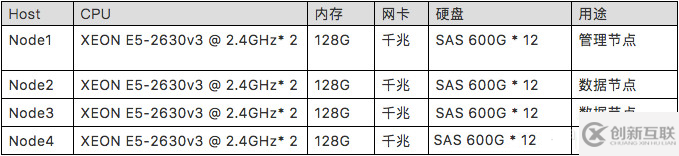
二、性能对比
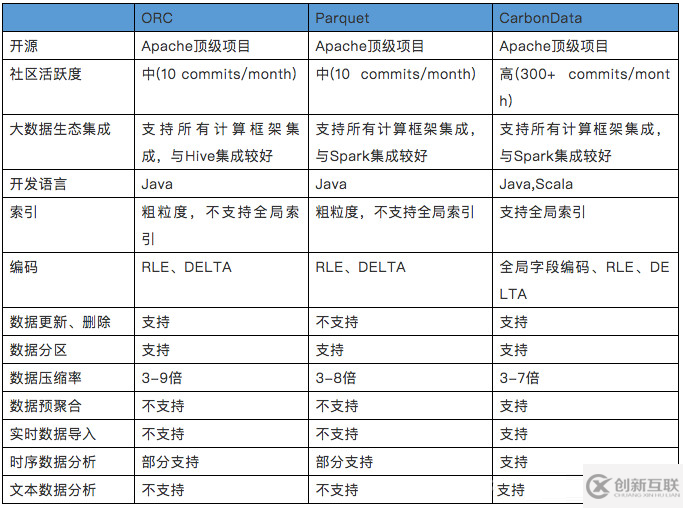
目前主流hadoop的文件存储格式有行存储的CSV格式,列式存储的ORC和Parquet等。本章给出的是Parquet+Spark和CarbonData+Spark在过滤查询场景和聚合计算场景的性能测试结果。
1)测试数据
创建沈阳社保的数据仓库,导入、集成1年的测试数据,如下表:
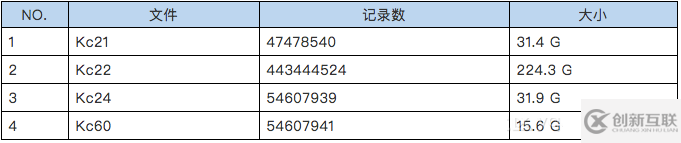
生成CarbonData格式文件,如下表: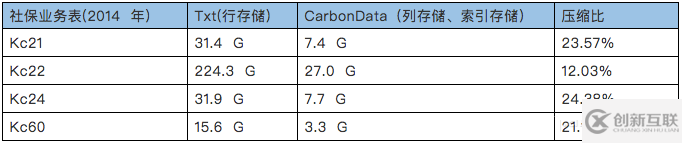
2)过滤查询场景测试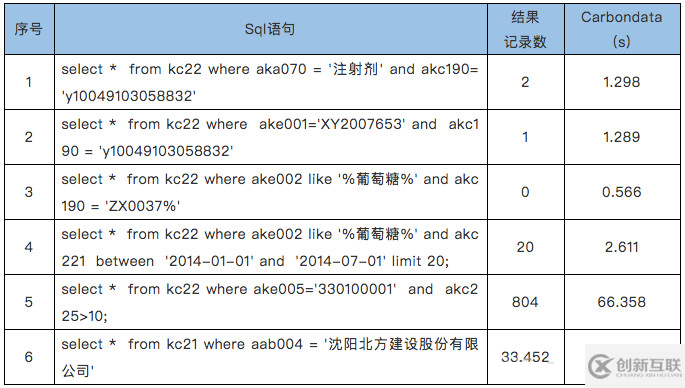
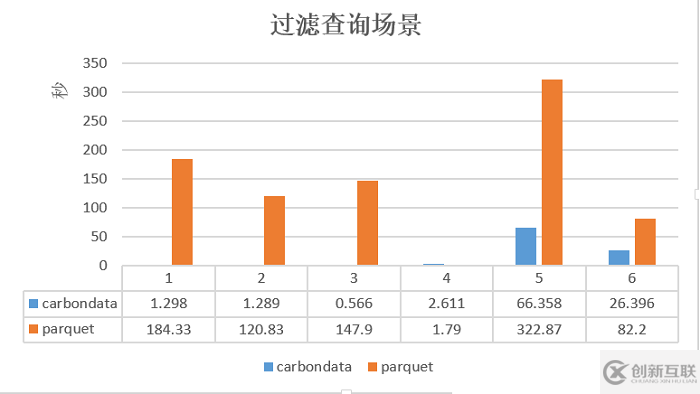
Parquet和CarbonData在过滤查询场景下的性能对比
3)聚合计算场景测试
Parquet和CarbonData在聚合计算场景下的性能对比
4)总结分析
在过滤查询中,CarbonData的查询效率比parquet效率好,主要体现在列数据的索引查询,极大地提高了精确查询的性能。在聚合查询中,CarbonData通过使用全局字典编码来加快计算速度,这使得处理、查询引擎可以直接在编码好的数据上进行处理而不需要转换数据,数据只有在返回结果给用户的时候才转换成用户可读的形式,通过索引有效过滤文件数据块减少磁盘的IO,提高查询性能。
到此,相信大家对“Hadoop生态系统的存储格式CarbonData性能分析”有了更深的了解,不妨来实际操作一番吧!这里是创新互联网站,更多相关内容可以进入相关频道进行查询,关注我们,继续学习!
标题名称:Hadoop生态系统的存储格式CarbonData性能分析
浏览地址:https://www.cdcxhl.com/article32/jcjgpc.html
成都网站建设公司_创新互联,为您提供营销型网站建设、静态网站、、外贸网站建设、软件开发、电子商务
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 品牌网站设计对企业来说有什么意义 2021-10-27
- 想要做好品牌网站设计的4个要点 2022-01-09
- 品牌网站设计如何在同行业中脱颖而出? 2016-01-18
- 如何制作自己的网站 企业品牌网站设计思路 2021-05-05
- 吴江高端网站建设制作品牌网站设计如何布局 2020-11-23
- 如何做好品牌网站设计,成都网站建设公司来帮您。 2022-08-20
- 品牌网站设计制作过程中要注意哪些问题? 2020-12-03
- 4个消费电子产品的品牌网站设计 2021-09-28
- 怎样做深圳品牌网站设计才有效果 2021-10-18
- 品牌网站设计怎样做更加高端? 2016-10-05
- 创新互联设计师谈品牌网站设计中色彩如何运用 2023-02-18
- 深圳品牌网站设计:如何制作设计一个好的网站 2021-08-17