你与解决“缓存污染”只差这篇文章的距离-创新互联
什么是缓存污染?
由于缓存的读取速度比非缓存要快上很多,所以在高性能场景下,系统在读取数据时,是首先从缓存中查找需要的数据,如果找到了则直接读取结果,如果找不到的话,则从内存或者硬盘中查找,再将查找到的结果存入缓存,以备下次使用。
创新互联是一家专注于成都网站设计、网站制作与策划设计,零陵网站建设哪家好?创新互联做网站,专注于网站建设10余年,网设计领域的专业建站公司;建站业务涵盖:零陵等地区。零陵做网站价格咨询:13518219792实际上,对于一个系统来说,缓存的空间是有限且宝贵的,我们不可能将所有的数据都放入缓存中进行操作,即便可以数据安全性也得不到保证,而且,如果缓存的数据量过大大,其速度也会变得越来越慢。 这个时候就需要考虑缓存的淘汰机制,但是淘汰哪些数据,又保留哪些数据,这是一个问题。如果处理不得当,就会造成“缓存污染”问题。
而缓存污染,是指系统将不常用的数据从内存移到缓存,造成常用数据的挤出,降低了缓存效率的现象。
解决缓存污染的算法
LFU算法
LFU,英文名Least Frequently Used,字面意思就是最不经常使用的淘汰掉算法,是通过数据被访问的频率来判断一个数据的热点情况。其核心理念是“历史上这个数据被访问次数越多,那么将来其被访问的次数也多”。
LFU中每个数据块都有一个引用计数器,所有数据块按照引用数从大到小的排序。
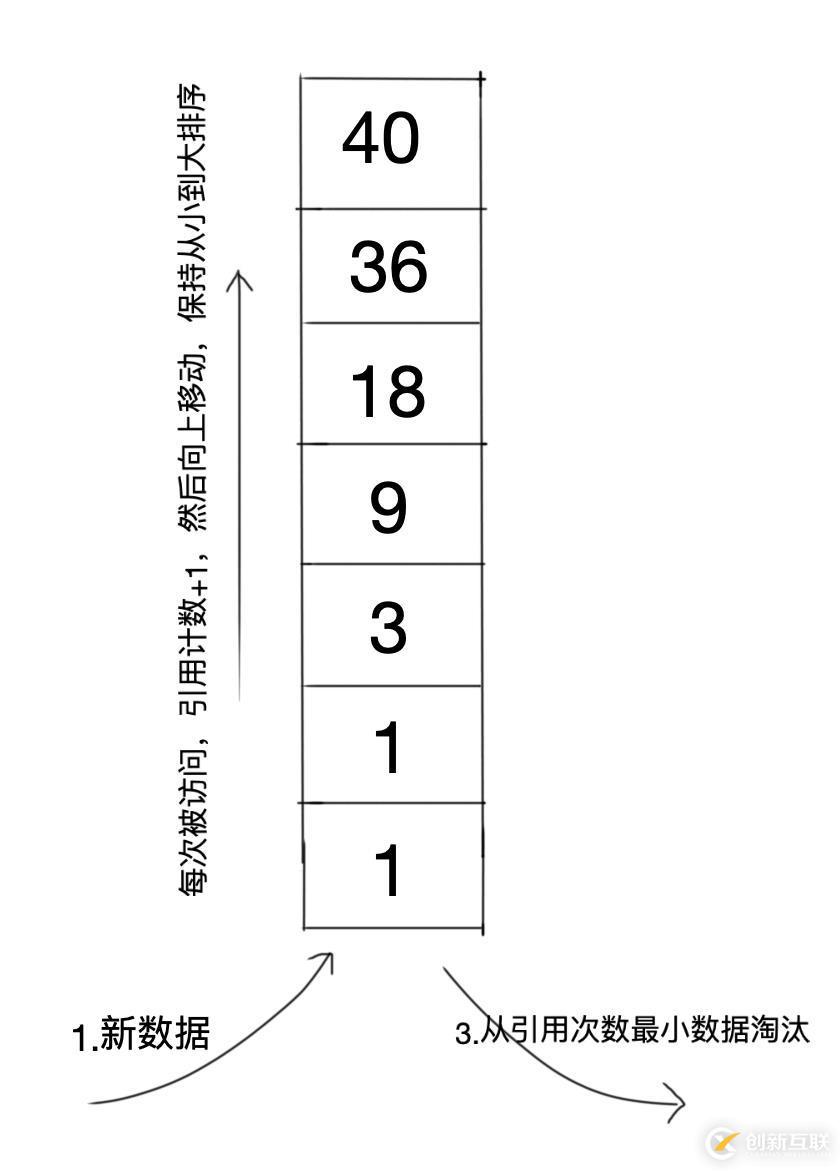
步骤:
新数据插入到尾部,并将计数设置为1;
当队列中的数据被访问后,引用计数+1,然后重新排序,保持引用次数从大到小排序;
当空间不足,需要淘汰数据时,将尾部引用计数最小的数据块删除。
分析:由于是根据频数进行热点判断和淘汰,所以先天具备避免偶发性、周期性批量操作导致临时非热点数据大量涌入缓存,挤出热点数据的问题。 虽然具备这种先天优势,但依旧存在另一种缓存污染问题,即历史热点数据污染当前热点数据,如果系统访问模式发生了改变,新的热点数据需要计数累加超过旧热点数据,才能将旧热点数据进行淘汰,造成热点效应滞后的问题。
复杂度与代价:每次操作都需要进行计数和排序,并且需要维护每个数据块计数情况,会占用较高的内存与cpu。
一个小思考,根据LFU算法,如何以O(1)时间复杂度实现get和put操作缓存?
LFU-Aging算法
LFU-Aging是基于LFU的改进算法,目的是解决历史热点数据对当前热点数据的污染问题。有些数据在开始时使用次数很多,但以后就不再使用,这类数据将会长时间留在缓存中,所以“除了访问次数外,还要考虑访问时间”,这也是LFU-Aging的核心理念。
虽然算法将时间纳入了考量范围,但LFU-Aging并不是直接记录数据的访问时间,而是增加了一个大平均引用计数的阈值,然后通过当前平均引用计数来标识时间,换句话说,就是将当前缓存中的平均引用计数值当作当前的生命年代,当这个生命年代超过了预设的阈值,就会将当前所有计数值减半,形成指数衰变的生命年代。
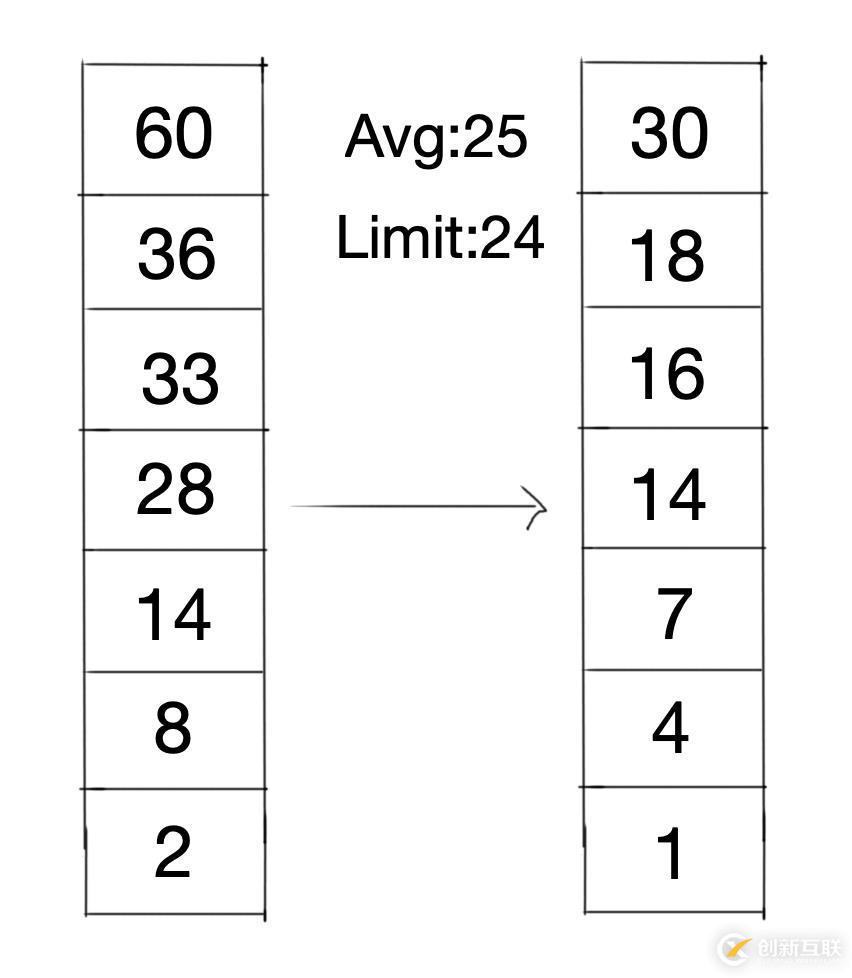
分析:优点是当访问模式发生改变的时候,生命年代的指数衰变会使LFU-Aging能够更快的适用新的数据访问模式,淘汰旧的热点数据。
复杂度与代价:在LFU的基础上又增加平均引用次数判断和统计处理,对cpu的消耗更高,并且当平均引用次数超过指定阈值(Aging)后,还需要遍历每一个数据块的引用计数,进行指数衰变。
Window-LFU算法
Window-LFU顾名思义叫做窗口期LFU,区别于原义LFU中记录所有数据的访问历史,Window-LFU只记录过去一段时间内(窗口期)的访问历史,相当于给缓存设置了有效期限,过期数据不再缓存。当需要淘汰时,将这个窗口期内的数据按照LFU算法进行淘汰。
分析:由于是维护一段窗口期的记录,数据量会比较少,所以内存占用和cpu消耗都比LFU要低。并且这段窗口期相当于给缓存设置了有效期,能够更快的适应新的访问模式的变化,缓存污染问题基本不严重。
复杂度与代价:维护一段时期内的数据访问记录,并对其排序。
LRU算法
LRU算法,英文名Least Recently Used,意思是最近最少使用的淘汰算法,根据数据的历史访问记录来进行淘汰数据,核心思想是“如果数据最近被访问过1次,那么将来被访问的概率会更高”,类似于就近优先原则。
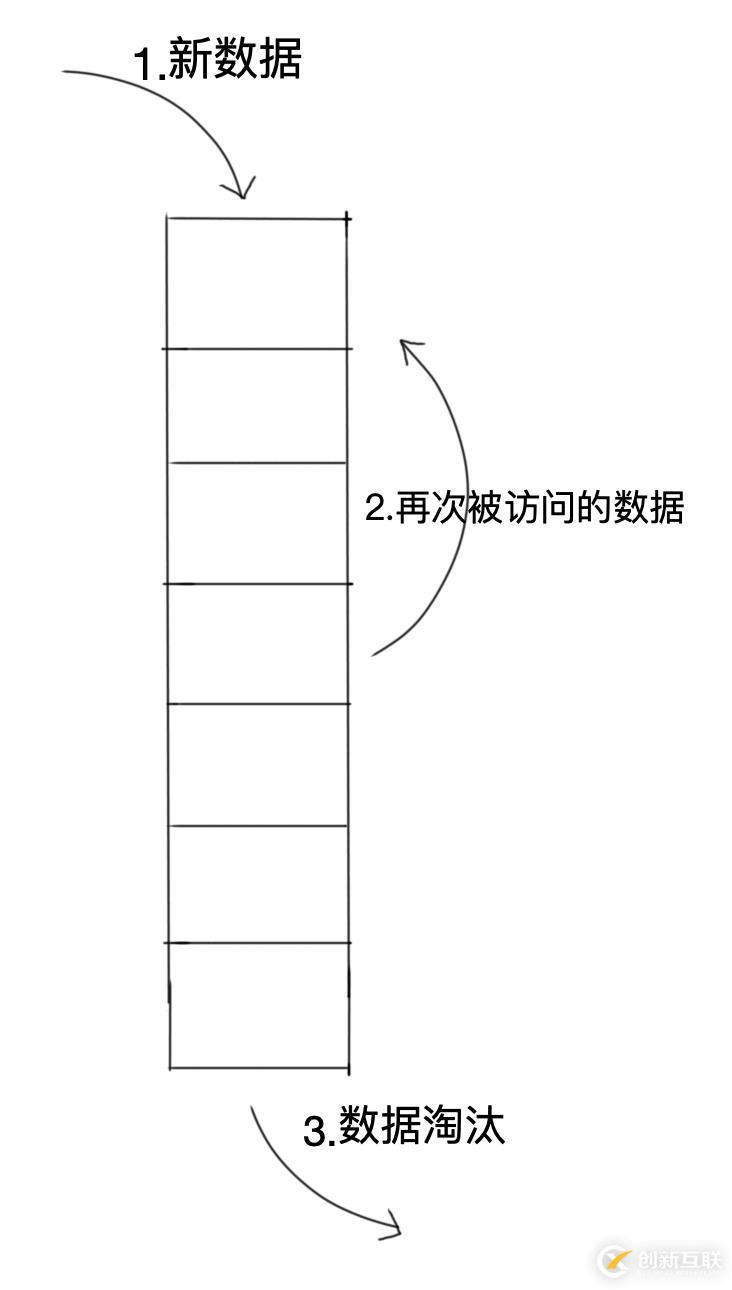
步骤:
新数据插入到链表头部;
每当命中缓存,便将命中的缓存数据移到链表头部;
当链表满的时候,将链表尾部的数据丢弃。
分析:偶发性的、周期性的批量操作会使临时数据涌入缓存,挤出热点数据,导致LRU热点命中率急剧下降,缓存污染情况比较严重。
复杂度与代价:数据结构复杂度较低;每次需要遍历链表,找到命中的数据块,然后将数据移到头部。
LRU-K算法
LRU-K是基于LRU算法的优化版,其中K代表最近访问的次数,从某种意义上,LRU可以看作是LRU-1算法,引入K的意义是为了解决上面所提到的缓存污染问题。其核心理念是从“数据最近被访问过1次”蜕变成“数据最近被访问过K次,那么将来被访问的概率会更高”。
LRU-K与LRU区别是,LRU-K多了一个数据访问历史记录队列(需要注意的是,访问历史记录队列并不是缓存队列,所以是不保存数据本身的,只是保存对数据的访问记录,数据此时依旧在原始存储中),队列中维护着数据被访问的次数以及时间戳,只有当这个数据被访问的次数大于等于K值时,才会从历史记录队列中删除,然后把数据加入到缓存队列中去。
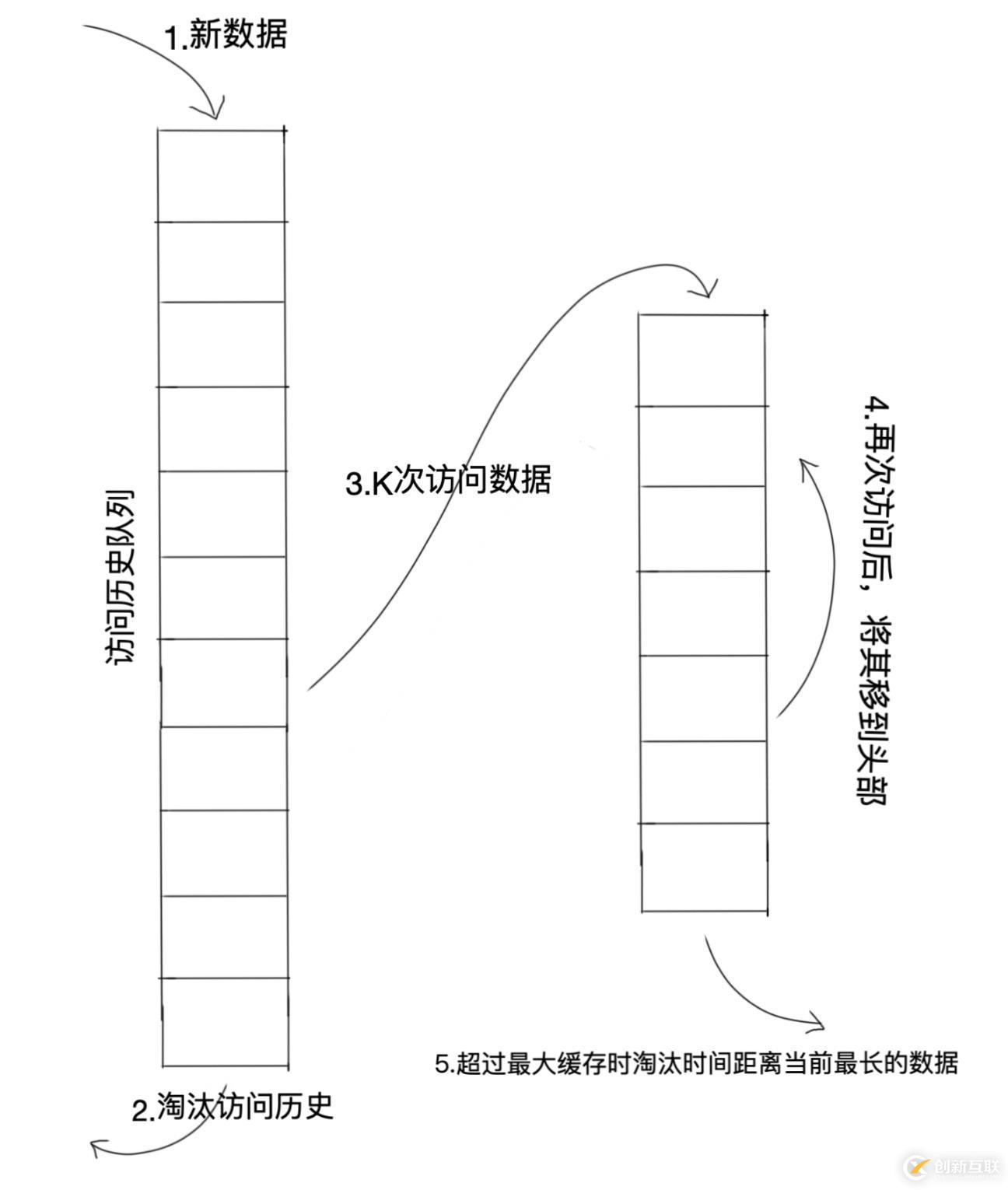
步骤:
数据第一次被访问时,加入到历史访问记录队列中,访问次数为1,初始化访问时间戳;
如果数据访问次数没有达到K次,则访问次数+1,更新时间戳。当队列满了时,按照某种规则(LRU或者FIFO)将历史记录淘汰。为了避免历史数据污染未来数据的问题,还需要加上一个有效期限,对超过有效期的访问记录,进行重新计数。(可以使用懒处理,即每次对访问记录做处理时,先将记录中的访问时间与当前时间进行对比,如果时间间隔超过预设的值,则访问次数重置为1并更新时间戳,表示重新开始计数)
当数据访问计数大于等于K次后,将数据从历史访问队列中删除,更新数据时间戳,保存到缓存队列头部中(缓存队列时间戳递减排序,越到尾部距离当前时间越长);
缓存队列中数据被再次访问后,将其移到头部,并更新时间戳;
缓存队列需要淘汰数据时,淘汰缓存队列中排在末尾的数据,即:淘汰“倒数第K次访问离现在最久”的数据。
分析:LRU-K降低了“缓存污染”带来的问题,命中率比LRU要高。实际应用中LRU-2是综合各种因素后最优的选择,LRU-3或者更大的K值命中率会高,但适应性差,一旦访问模式发生变化,需要大量的新数据访问才能将历史热点访问记录清除掉。
复杂度与代价:LRU-K队列是一个优先级队列。由于LRU-K需要记录那些被访问过,但还没有放入缓存的对象,导致内存消耗会很多。
URL-Two queues算法
URL-Two queues算法类似于LRU-2,不同点在于URL-Two queues将LRU-2算法中的访问历史队列(注意这不是缓存数据的)改为一个FIFO缓存队列,即:URL-Two queues算法有两个缓存队列,一个是FIFO队列(First in First out,先进先出),一个是LRU队列。
当数据第一次访问时,URL-Two queues算法将数据缓存在FIFO队列里面,当数据第二次被访问时,则将数据从FIFO队列移到LRU队列里面,两个队列各自按照自己的方法淘汰数据。
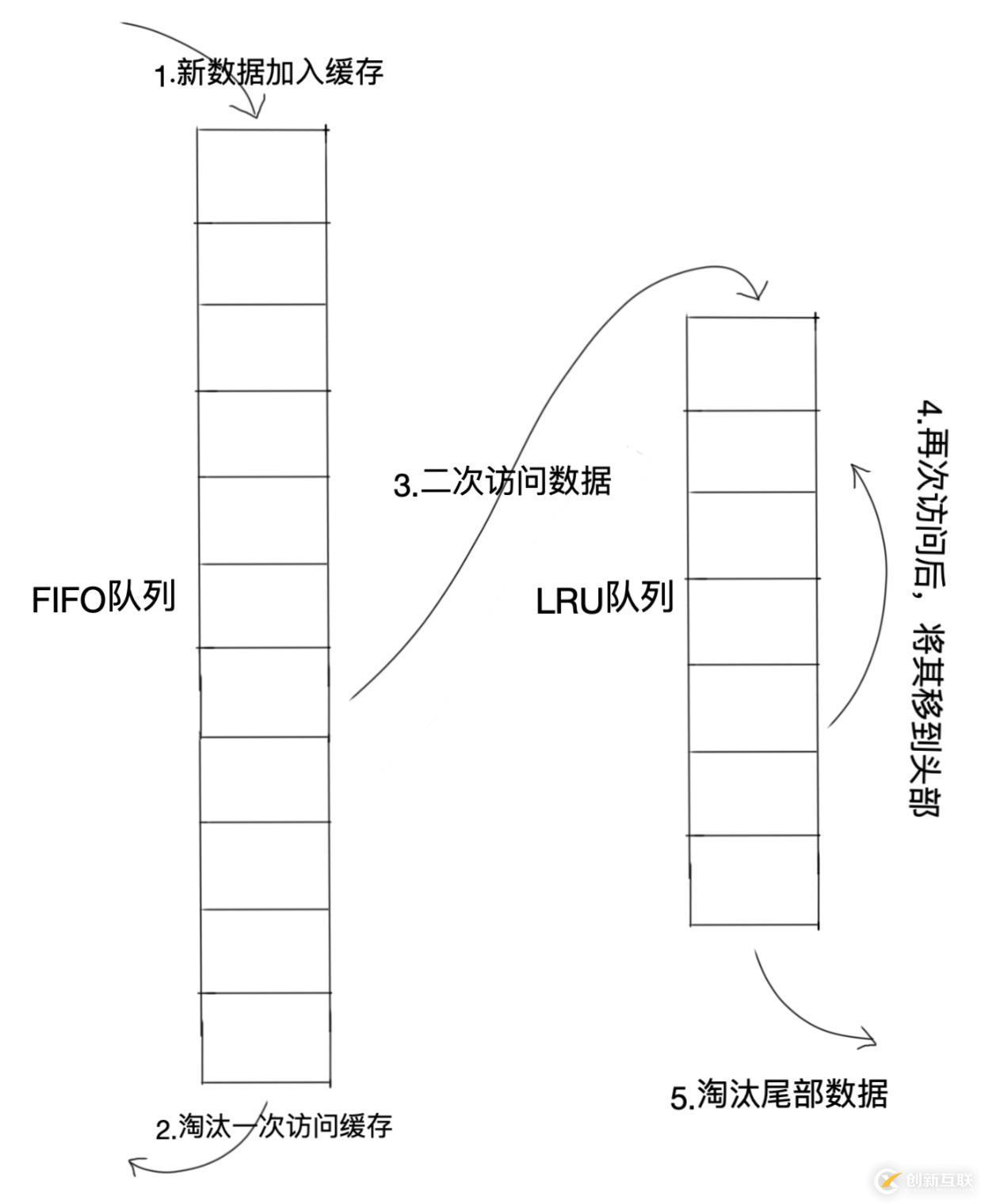
步骤:
新访问的数据先插入到FIFO队列中;
如果数据在FIFO队列中一直没有被再次访问,则最终按照FIFO规则淘汰;
如果数据在FIFO队列中被再次访问,则将数据从FIFO删除,加入到LRU队列头部;
如果数据在LRU队列再次被访问,则将数据移到LRU队列头部;
LRU队列淘汰末尾的数据。
分析:URL-Two queues算法和LRU-2算法命中率类似,但是URL-Two queues会减少一次从原始存储读取或计算数据的操作。命中率要高于LRU。
复杂度与代价:需要维护两个队列,代价是FIFO和LRU代价之和。
五三LRU算法
emmmm...
这个名字其实是我取的,大概是这种算法还没有被命名?当然,这是一个玩笑话。
我是在mysql底层实现里发现这个算法的,mysql在处理缓存淘汰时是用的这个方法,有点像URL-Two queues的变体,只是我们只需要维护一个队列,然后将队列按照5:3的比例进行分割,5的那部分叫做young区,3的那部分叫做old区。具体是怎么样的请先看我把图画出来:
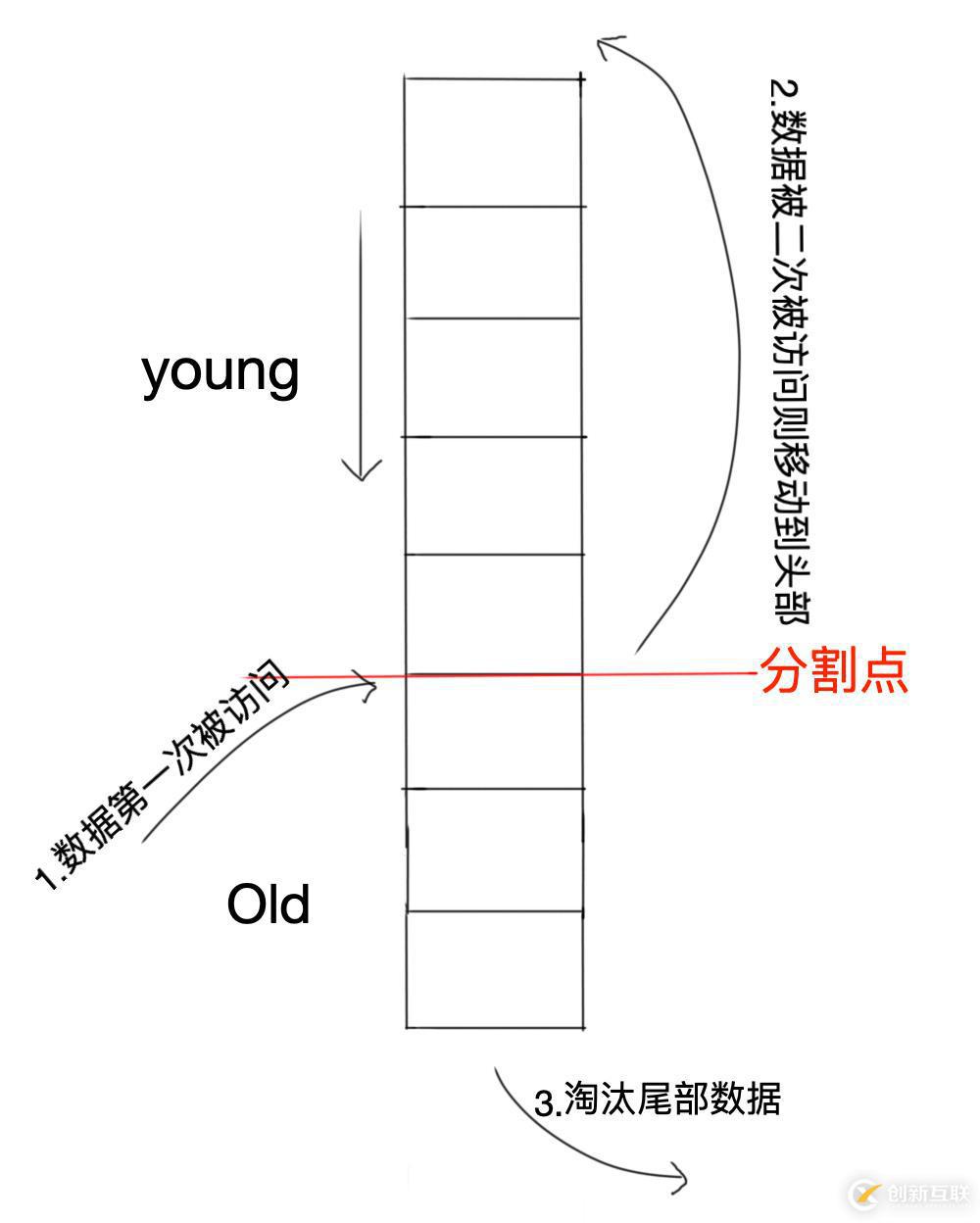
步骤:
第一次访问的数据从队列的3/8处位置插入;
如果数据再次被访问,则移动到队列头部;
如果数据没有被再访问,会逐步被热点数据驱逐向下移;
淘汰尾部数据。
分析:五三LRU算法算作是URL-Two queues算法的变种,原理其实是一样的,只是把两个队列合二为一个队列进行数据的处理,所以命中率和URL-Two queues算法一样。
复杂度与代价:维护一个队列,代价较低,但是内存占用率和URL-Two queues一样。
Multi Queue算法
Multi Queue算法根据访问频率将数据划分为多个队列,不同的队列具有不同的访问优先级,其核心思想是“优先缓存访问次数多的数据”。
Multi Queue算法将缓存划分为多个LRU队列,每个队列对应不同的访问优先级。访问优先级是根据访问次数计算出来的,例如: Q0,Q1....Qn代表不同的优先级队列,Q-history代表从缓存中淘汰数据,但记录了数据的索引和引用次数。
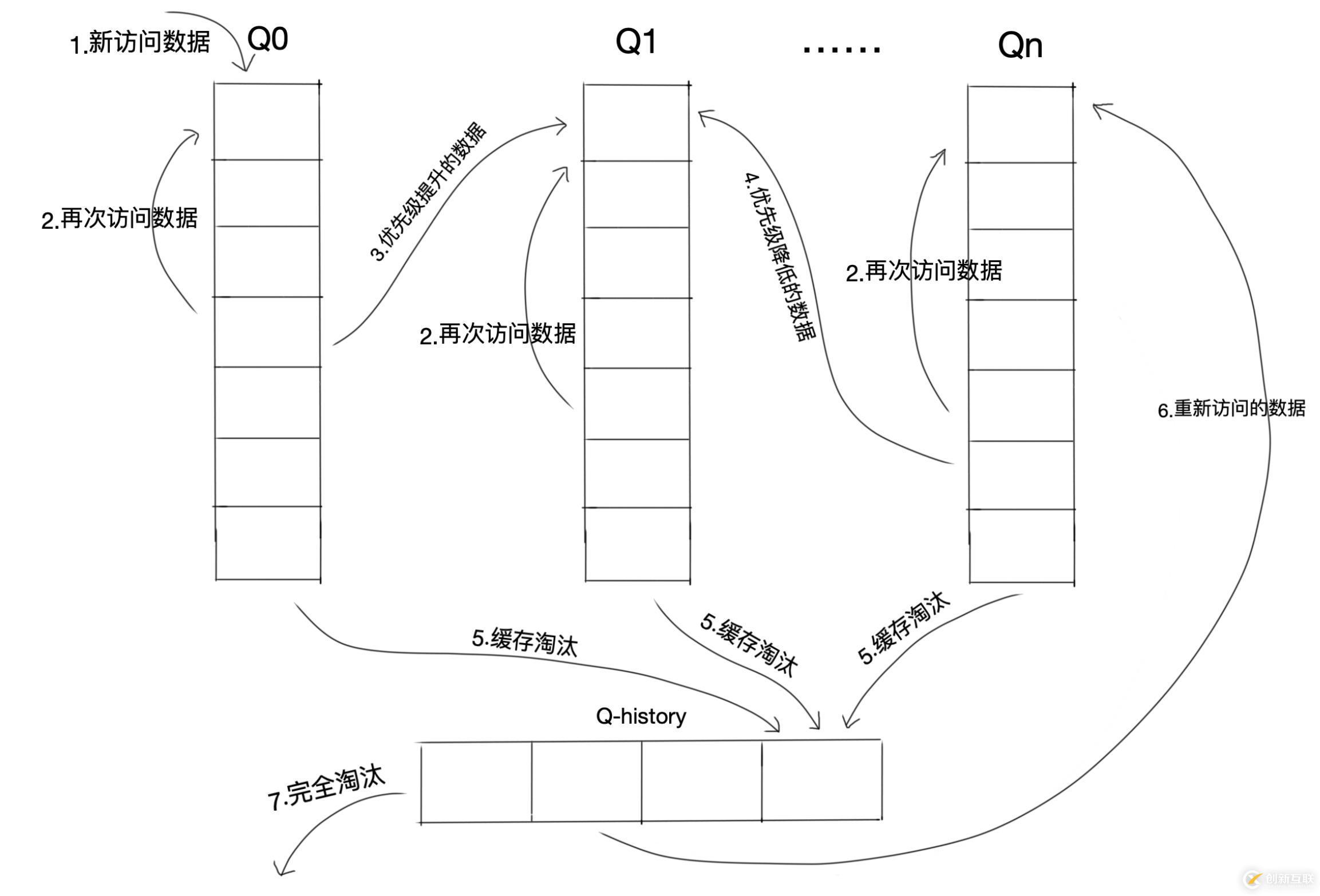
步骤:
新插入的数据放入Q0;
每个队列按照LRU管理数据,再次访问的数据移动到头部;
当数据的访问次数达到一定次数,需要提升优先级时,将数据从当前队列删除,加入到高一级队列的头部;
为了防止高优先级数据永远不被淘汰,当数据在指定的时间里访问没有被访问时,需要降低优先级,将数据从当前队列删除,加入到低一级的队列头部;
需要淘汰数据时,从最低一级队列开始按照LRU淘汰;每个队列淘汰数据时,将数据从缓存中删除,将数据索引加入Q-history头部;
如果数据在Q-history中被重新访问,则重新计算其优先级,移到目标队列的头部;
Q-history按照LRU淘汰数据的索引。
分析:Multi Queue降低了“缓存污染”带来的问题,命中率比LRU要高。
复杂度与代价:Multi Queue需要维护多个队列,且需要维护每个数据的访问时间,复杂度比LRU高。Multi Queue需要记录每个数据的访问时间,需要定时扫描所有队列,代价比LRU要高。虽然Multi Queue的队列看起来数量比较多,但由于所有队列之和受限于缓存容量的大小,因此这里多个队列长度之和和一个LRU队列是一样的,因此队列扫描性能也相近。
另外有需要云服务器可以了解下创新互联scvps.cn,海内外云服务器15元起步,三天无理由+7*72小时售后在线,公司持有idc许可证,提供“云服务器、裸金属服务器、高防服务器、香港服务器、美国服务器、虚拟主机、免备案服务器”等云主机租用服务以及企业上云的综合解决方案,具有“安全稳定、简单易用、服务可用性高、性价比高”等特点与优势,专为企业上云打造定制,能够满足用户丰富、多元化的应用场景需求。
文章题目:你与解决“缓存污染”只差这篇文章的距离-创新互联
浏览地址:https://www.cdcxhl.com/article32/dhjosc.html
成都网站建设公司_创新互联,为您提供网站改版、软件开发、外贸建站、Google、品牌网站建设、网站设计公司
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 成都如何估算关键词优化难度 2023-03-04
- seo关键词优化有哪些教程? 2015-03-24
- 网站关键词优化排名的目的是什么呢? 2016-10-30
- 【网站优化】百度优化公司seo关键词优化排名技巧 2021-08-15
- 【SEO优化】热门关键词优化离不开网站粘性度的提升 2022-05-06
- 网站优化的重点-长尾关键词优化 2022-05-02
- 网站老域名做关键词优化的利与弊? 2023-04-05
- 石家庄网站建设中网站优化的重点—长尾关键词优化 2023-01-26
- 网站SEO关键词优化方法是什么 2022-12-25
- SEO优化如何做长尾关键词优化过程? 2014-01-26
- 企业网站关键词优化如何稳定首页? 2023-04-23
- 网站优化如何做整站关键词优化 2022-12-24