prometheus搭建监控实操-创新互联
文章目录
- prometheus 服务监控
- grafana 图标展示
- alertmanager 告警通知
一个监控体系的核心,prometheus完成对实例数据的收集、监控,grafana将收集的业务数据汇总成报表,最后有alertmanager根据不同的业务告警配置生成不同维度的告警,这可以就算是一个运维监控体系的核心功能了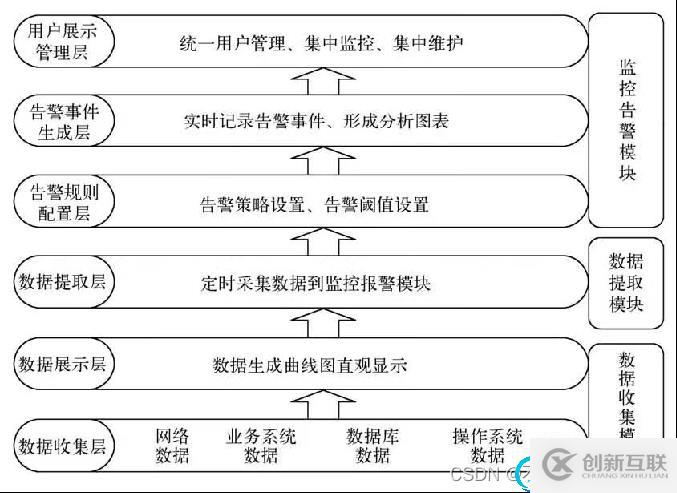

tar xvfz prometheus-*.tar.gz
cd prometheus-*
//后台运行
./prometheus --web.listen-address=:19090 --config.file=prometheus.yml &
//停止
pkill prometheus核心配置
#监控java服务
- job_name: "javaDemo"
metrics_path: "/actuator/prometheus"
static_configs:
- targets: ["127.0.0.1:5170"]
#其他服务
- job_name: "prometheus"
static_configs:
- targets: ["192.168.3.105:19090"]//下载安装
wget https://packages.grafana.com/enterprise/rpm/grafana-enterprise-8.3.6-1.x86_64.rpm
yum install grafana-enterprise-8.3.6-1.x86_64.rpm
//启动服务
systemctl start grafana-server
//grafana命令帮助
grafana-cli -h / --help
grafana-cli --pluginsDir "/home/prometheus/grafana/plugins" plugins install plugin-id
[Unit]
Description=alertmanager
[Service]
ExecStart=/prometheus/alertmanager-0.23/alertmanager \
--config.file=/prometheus/alertmanager-0.23/alertmanager.yml
Restart=on-failure
[Install]
WantedBy=multi-user.target
./alertmanager --config.file=alertmanager.yml --web.listen-address=":19093"
//如果9094端口被占用,需要关闭集群模式
./alertmanager --web.listen-address=localhost:19093 --cluster.listen-address= \
#修改prometheus配置
alerting:
alertmanagers:
- static_configs:
- targets: ['localhost:9093']
rule_files:
- "/prometheus/alertmanager-0.23/rules/*.yml" 告警模板内容
groups:
- name: node-alert
rules:
- alert: 主机停止运行
expr: up{job="node_info"} == 0
for: 15s
labels:
severity: 1
nodename: "{{ $labels.app }}"
annotations:
summary: "{{ $labels.app }}已停止运行超过15s!"
description: ""
- alert: 主机内存使用率过高
expr: (1 - (node_memory_MemAvailable_bytes / (node_memory_MemTotal_bytes))) * 100 >90
for: 10s # 告警持续时间,超过这个时间才会发送给alertmanager
labels:
severity: warning
nodename: "{{ $labels.app }}"
annotations:
summary: "服务器实例 {{ $labels.app }}内存使用率过高"
description: "{{ $labels.app }}的内存使用率超过90%,当前使用率[{{ $value }}]."
- alert: 主机cpu使用率过高
expr: 100-avg(irate(node_cpu_seconds_total{mode="idle"}[5m])) by(instance)*100 >80
for: 1m
labels:
severity: warning
nodename: "{{ $labels.app }}"
annotations:
summary: "服务器实例 {{ $labels.app }} cpu使用率过高"
description: "{{ $labels.app }}的cpu使用率超过80%,当前使用率[{{ $value }}]."
- alert: 主机磁盘使用率过高
expr: 100 - node_filesystem_avail_bytes{fstype=~"ext4|xfs",mountpoint="/"} * 100 / node_filesystem_size_bytes{fstype=~"ext4|xfs",mountpoint="/"} >80
for: 1m
labels:
severity: warning
nodename: "{{ $labels.app }}"
annotations:
summary: "服务器实例 {{ $labels.app }} 磁盘使用率过高"
description: "{{ $labels.app }}的disk使用率超过80%,当前使用率[{{ $value }}]."你是否还在寻找稳定的海外服务器提供商?创新互联www.cdcxhl.cn海外机房具备T级流量清洗系统配攻击溯源,准确流量调度确保服务器高可用性,企业级服务器适合批量采购,新人活动首月15元起,快前往官网查看详情吧
网页题目:prometheus搭建监控实操-创新互联
文章路径:https://www.cdcxhl.com/article32/dgsdpc.html
成都网站建设公司_创新互联,为您提供用户体验、营销型网站建设、企业网站制作、外贸网站建设、商城网站、微信公众号
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 集团型网站建设品牌网站制作设计 2020-12-03
- 为什么高端品牌网站制作公司越来越少了 2016-11-12
- 品牌网站制作的价格为什么那么高呢? 2016-10-28
- 高端品牌网站制作离不开独特新颖的设计 2016-10-30
- 如何打响品牌网站制作的知名度 2021-12-11
- 什么是品牌网站,品牌网站制作需要注意哪些内容? 2016-10-15
- 湛江品牌网站制作:做好品牌网站制作方案有哪些要点? 2021-12-23
- 品牌网站制作常见的布局方式! 2022-05-11
- 品牌网站制作有哪些重要注意事项? 2016-08-20
- 中小企业品牌网站制作与塑造 2021-12-06
- 周口品牌网站建设:在品牌网站制作的过程中有哪些值得注意的问题? 2021-09-10
- 品牌网站制作好方法好步骤有哪些? 2022-06-27