Kubernetes高级进阶之Node自动扩容/缩容-创新互联
Kubernetes高级进阶之Node自动扩容/缩容目录:
1、Cluster AutoScaler云厂商扩容/缩容
2、Ansible一键自动扩容Node1、Cluster AutoScaler
扩容:Cluster AutoScaler 定期检测是否有充足的资源来调度新创建的 Pod,当资源不足时会调用 Cloud Provider 创建新的 Node。
工作流程:定期检查集群中的资源是否充足的,如果发现集群资源不够pod就会出现pending的状态,会等待资源的一个就绪,如果没有新的资源没有释放出来,它会一直等待,部署的服务就不会提供服务,此时autoscaler会检测到一个资源的利用率的情况,是不是存在资源的一个紧缺,存在的话会调用云供应商provider来创建新的node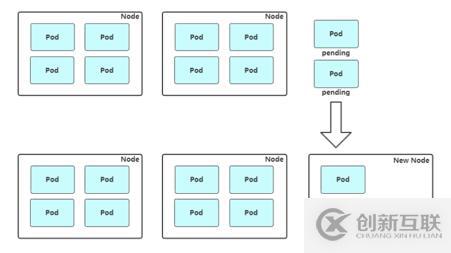

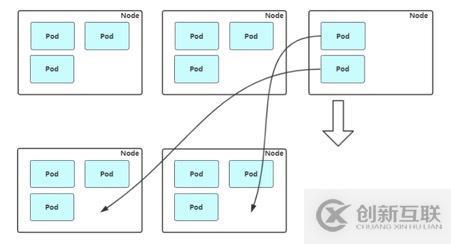
缩容:Cluster AutoScaler 也会定期监测 Node 的资源使用情况,当一个 Node 长时间资源利用率都很低时(低于 50%)长时间利用率比较低的资源下线,来进行判断,自动将其所在虚拟机从云服务商中删除。此时,将原来上面的pod驱逐掉,调度到其他节点上提供服务。
支持的云提供商:
要是使用它们云厂商的就可以使用它们的的组件解决去用,一般他们都对接完成了。
• 阿里云:https://github.com/kubernetes/autoscaler/blob/master/cluster-autoscaler/cloudprovider/alicloud/README.md
• AWS: https://github.com/kubernetes/autoscaler/blob/master/cluster-autoscaler/cloudprovider/aws/README.md
• Azure: https://github.com/kubernetes/autoscaler/blob/master/cluster-autoscaler/cloudprovider/azure/README.md
小结:
弹性伸缩主要解决的问题是容量规划与实际负载的矛盾,就是我这批机器中,其中负载高了,能不能让这批服务器快速的扩容,主要是解决这么一个问题,考验的就是快速的扩容和缩容。
就是传统的这种弹性伸缩放到k8s中,仔细想想会遇到两种问题
1、 机器规格不统一造成机器利用率百分比的碎片化
在k8s集群中不是所有机器都是一样的,我们也没必要都是一样,其实k8s已经帮我们做好资源的管理了,这些cpu,内存都会作为一个整体放在资源池中去调度,对于缩容和扩容的情况下,特别是缩容,机器规格的不统一,缩容时可能缩容一些小规格的机器,那么很有可能你缩容之后其实没有太多的效果,可能你大机器还没有去缩容,导致你效果还不是很明显,如果大规格机器缩容的话,可能会让你资源的一个争抢,可能你资源的冗余不是很多了。
2、 机器利用率不单纯依靠宿主机计算
当你没做容器之前,做一个服务器的资源的规划,内存和CPU去申请就完事了,那么在那种情况下做一些缩容扩容也比较简单,比如扩容你看你的服务器的资源是不是到达80%,90%,然后申请新的机器就好了,缩容也是如此,看一下资源空闲的整体资源利用率比较低,减少几台还是很容易的,但是到k8s的场景中呢,其实我们在上面部署的一些应用,没必要太注意服务器底层的资源了,不关心我机器的配置利用率多少,它关心的是,我申请的资源,我部署的应用你能不能给足我就行了,在k8s中容量规划是根据request和limit这两个值,request其实就是在k8s中的一个配额,你部署一个应用,申请的资源都是通过request去定义的,所以在k8s中就多了一个维度,request与宿主机的资源利用率,所以在做缩容扩容的时候要考虑到这一点,也就是不能根据你当前的节点去分配了,因为你申请部署request的这个配额它即使不用,你也不能说把它去掉,所以要考虑整体request的一个整体资源的利用率,并且在这个资源利用率之上保持一定的冗余。
2.2 Ansible扩容Node
第三种就是我们人工干预的去进行扩容缩容了,这是普遍自建采用的一种手段
1. 触发新增Node,要知道要不要去增加一个节点。
2. 调用Ansible脚本部署组件,怎么去准备好这个节点,这台新机器有没有准备好,有没有部署这些组件。
3. 检查服务是否可用,新加入的组件查看是否是正常的
4. 调用API将新Node加入集群或者启用Node自动加入
5. 观察新Node状态,进行监控,对于新节点观察,运行的日志,资源状态。
6. 完成Node扩容,接收新Pod模拟扩容node节点,由于我的资源过多,导致无法分配,出现pending的状态
[root@k8s-master1 ~]# kubectl run web --image=nginx --replicas=6 --requests="cpu=1,memory=256Mi"
[root@k8s-master1 ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
web-944cddf48-6qhcl 1/1 Running 0 15m
web-944cddf48-7ldsv 1/1 Running 0 15m
web-944cddf48-7nv9p 0/1 Pending 0 2s
web-944cddf48-b299n 1/1 Running 0 15m
web-944cddf48-nsxgg 0/1 Pending 0 15m
web-944cddf48-pl4zt 1/1 Running 0 15m
web-944cddf48-t8fqt 1/1 Running 0 15m现在的状态就是pod由于资源池不够,无法分配资源到当前的节点上了,所以现在我们需要对我们的node节点进行扩容
[newnode]
10.4.7.22 node_name=k8s-node3
[root@ansible ansible-install-k8s-master]# ansible-playbook -i hosts add-node.yml -uroot -k查看已经收到加入node的请求,并运行通过
[root@k8s-master1 ~]# kubectl get csr
NAME AGE REQUESTOR CONDITION
node-csr-0i7BzFaf8NyG_cdx_hqDmWg8nd4FHQOqIxKa45x3BJU 45m kubelet-bootstrap Approved,Issued查看node节点状态
[root@k8s-master1 ~]# kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-master1 Ready <none> 7d v1.16.0
k8s-node1 Ready <none> 7d v1.16.0
k8s-node2 Ready <none> 7d v1.16.0
k8s-node3 Ready <none> 2m52s v1.16.0查看资源状态的分配的总体利用率[root@k8s-master1 ~]# kubectl describe node k8s-node1
缩容Node节点
缩容的话,就是驱逐这个节点上的pod,对业务和集群可能都会受一些影响
如果想从kubernetes集群中删除节点,正确流程
1、 获取节点列表
Kubectl get node
2、 设置不可调度
Kubectl cordon $node_name
3、 驱逐节点上额pod
Kubectl drain $node_name –I gnore-daemonsets
4、 移除节点
该节点上已经没有任何资源了,可以直接移除节点:
Kubectl delete node $node_node
这样,我们平滑移除了一个k8s节点首先要了解到整个集群哪个节点要删除,这个人工干预的话,是要先确定好,哪个值得去缩容删除的,那肯定是资源利用率低,上面跑的资源最少最有优先缩容的节点。
然后设置不可调度,因为随时有可能新的pod去调度上面去,防止新的pod调度过来,这个有kubectl –help的相关命令
cordon 标记 node 为 unschedulable
[root@k8s-master1 ~]# kubectl cordon k8s-node3
node/k8s-node3 cordoned这里会给不可调度的node打个标记
[root@k8s-master1 ~]# kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-master1 Ready <none> 7d1h v1.16.0
k8s-node1 Ready <none> 7d1h v1.16.0
k8s-node2 Ready <none> 7d1h v1.16.0
k8s-node3 Ready,SchedulingDisabled <none> 45m v1.16.0现在这个阶段不会对现有的阶段的pod不会有任何影响
现在驱逐现在节点上已有的pod,所以现在要对这个node节点设置一定的维护期,这个也有相关命令drain Drain node in preparation for maintenance
设置这个状态的话,它会将这个节点上的pod进行驱逐,会给你一个提示会告诉你现在的这个节点已经是不可调度状态了,现在在进行驱逐,这里报了一个错误daemonset的一个pod,因为我们部署的flanneld是使用daemonset去启动的,所以会出现这种情况,这个就可以直接忽略
[root@k8s-master1 ~]# kubectl drain k8s-node3
node/k8s-node3 already cordoned
error: unable to drain node "k8s-node3", aborting command...
There are pending nodes to be drained:
k8s-node3
error: cannot delete DaemonSet-managed Pods (use --ignore-daemonsets to ignore): ingress-nginx/nginx-ingress-controller-qxhj7, kube-system/kube-flannel-ds-amd64-j9w5l这个加后面的命令
[root@k8s-master1 ~]# kubectl drain k8s-node3 --ignore-daemonsets
node/k8s-node3 already cordoned
WARNING: ignoring DaemonSet-managed Pods: ingress-nginx/nginx-ingress-controller-qxhj7, kube-system/kube-flannel-ds-amd64-j9w5l
evicting pod "web-944cddf48-nsxgg"
evicting pod "web-944cddf48-7nv9p"
pod/web-944cddf48-nsxgg evicted
pod/web-944cddf48-7nv9p evicted
node/k8s-node3 evicted
[root@k8s-master1 ~]# kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-master1 Ready <none> 7d1h v1.16.0
k8s-node1 Ready <none> 7d1h v1.16.0
k8s-node2 Ready <none> 7d1h v1.16.0
k8s-node3 Ready,SchedulingDisabled <none> 53m v1.16.0
[root@k8s-master1 ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
web-944cddf48-6qhcl 1/1 Running 0 127m
web-944cddf48-7ldsv 1/1 Running 0 127m
web-944cddf48-b299n 1/1 Running 0 127m
web-944cddf48-cc6n5 0/1 Pending 0 38s
web-944cddf48-pl4zt 1/1 Running 0 127m
web-944cddf48-t8fqt 1/1 Running 0 127m
web-944cddf48-vl5hg 0/1 Pending 0 38s
[root@k8s-master1 ~]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
web-944cddf48-6qhcl 1/1 Running 0 127m 10.244.0.6 k8s-node2 <none> <none>
web-944cddf48-7ldsv 1/1 Running 0 127m 10.244.0.5 k8s-node2 <none> <none>
web-944cddf48-b299n 1/1 Running 0 127m 10.244.0.7 k8s-node2 <none> <none>
web-944cddf48-cc6n5 0/1 Pending 0 43s <none> <none> <none> <none>
web-944cddf48-pl4zt 1/1 Running 0 127m 10.244.2.2 k8s-master1 <none> <none>
web-944cddf48-t8fqt 1/1 Running 0 127m 10.244.1.2 k8s-node1 <none> <none>
web-944cddf48-vl5hg 0/1 Pending 0 43s <none> <none> <none> <none>现在缩容完,由于我的资源比较紧张所以又出现了pending的状态,所以这就是缩容,当缩容之后,还是由控制器去保证pod的副本数量的,这个当前你要保证一个其他节点的冗余性,这样缩容才有意义,不然出现pending状态肯定不行的。
然后删除k8s-node3节点
[root@k8s-master1 ~]# kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-master1 Ready <none> 7d2h v1.16.0
k8s-node1 Ready <none> 7d2h v1.16.0
k8s-node2 Ready <none> 7d2h v1.16.0
k8s-node3 Ready,SchedulingDisabled <none> 71m v1.16.0移除节点,当驱逐完成之后,也要保证在其他的节点上有预期的副本,还要做好一定的策略,在下线期间不能做pod的调度。
或者将node3关机也可以,首先要保证其他的节点的资源是冗余的,即使在出现其他的状况下,k8s有一定的机制会在5分钟之内将出现故障的node节点上的pod飘移到其他正常的node节点上,像微服务我们的服务当我们去驱逐的时候,其实业务也会收到一些影响,毕竟我们需要将这个节点上的node做驱逐,转移到其他节点上,所以尽量在业务低峰期去做这件事。
[root@k8s-master1 ~]# kubectl delete node k8s-node3
node "k8s-node3" deleted
[root@k8s-master1 ~]# kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-master1 Ready <none> 7d2h v1.16.0
k8s-node1 Ready <none> 7d2h v1.16.0
k8s-node2 Ready <none> 7d2h v1.16.0另外有需要云服务器可以了解下创新互联cdcxhl.cn,海内外云服务器15元起步,三天无理由+7*72小时售后在线,公司持有idc许可证,提供“云服务器、裸金属服务器、高防服务器、香港服务器、美国服务器、虚拟主机、免备案服务器”等云主机租用服务以及企业上云的综合解决方案,具有“安全稳定、简单易用、服务可用性高、性价比高”等特点与优势,专为企业上云打造定制,能够满足用户丰富、多元化的应用场景需求。
分享名称:Kubernetes高级进阶之Node自动扩容/缩容-创新互联
当前URL:https://www.cdcxhl.com/article32/dgdopc.html
成都网站建设公司_创新互联,为您提供响应式网站、网站改版、静态网站、定制开发、网站导航、搜索引擎优化
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 创业团队如何进行股权分配 2017-02-26
- 网页设计的要点有哪些 2023-09-11
- 提高北京网站建设的质量应该做到哪些方面 2023-08-12
- 搜索引擎的下载系统 2021-06-17
- 如何策划企业营销型网站建设 2022-12-31
- 教育行业推广介绍 2020-10-15
- 浅谈中小互联网公司的公司人才管理 2021-07-25
- 国内服务器租赁到底怎样 2023-12-10
- 网站怎样建设更吻合客户需求 2023-03-08
- 网站目录结构的创建问题 2016-10-31
- 网站建设来说说那些响应式网站建设的注意事项!(组图)加强网站无障碍服务能力建设 2023-12-04
- 新的一年,网站建设再次腾飞! 2023-09-28