盲反馈检索系统实验记录一-创新互联
在进行实验之前,先了解相关反馈和盲反馈的一些概念:
红桥ssl适用于网站、小程序/APP、API接口等需要进行数据传输应用场景,ssl证书未来市场广阔!成为创新互联的ssl证书销售渠道,可以享受市场价格4-6折优惠!如果有意向欢迎电话联系或者加微信:18980820575(备注:SSL证书合作)期待与您的合作!相关反馈是基于用户的,由用户标出初次查询结果相关还是不相关,再经过Rocchio算法或其他算法使检索结果更能满足用户需求;
盲反馈也称伪反馈,是由计算机自动处理检索结果,不需要用户的参与也可以得到比较满意的检索效果。这种方法假定用户初始检索结果的前k篇文档是相关的,再由系统抽选出这k篇文档的特征词,然后把这些特征词和初始查询词再放入搜索框中进行二次检索,这种行为我们称之为“扩展查询词”。通过扩展查询词可以提高检索系统的性能。
本项目就是基于盲反馈理论以及结合相应算法编写一个检索系统,并通过一系列的评价指标来测试此系统的性能。本系统是经过小组成员结合相关理论后而确定实施的,本文从项目最初代码的编写,直到一个检索系统的成功运行,以及涉及到的信息检索的理论,笔者都会一一讲解。
编程环境的准备:PHP+MySQL+Apache(项目初期没有使用MySQL,随着后期数据集的增大,可以考虑)
额外知识:HTML+CSS+JS+Ajax(主要用于前台的显示)
语料库:本实验使用搜狗实验室提供的语料库http://www.sogou.com/labs/dl/c.html
在测试时笔者使用的是mini版的10篇IT新闻(文件目录名问C000010)
在代码编写过程中,笔者先使用过程化的方法,然后再把各个功能封装到Tool.class.php的工具类中,便于以后代码重用。
首先,建立自己的词表。
笔者是这样考虑的,假如有三篇文档,文档内容为:
(html html)
(java html java)
(python java)
先对这三遍文档去重,
(html)
(java html)
(python java)
然后合并这三篇文档:
(html java html python java)
然后再对其去重,并且按字母升序排列:
(html java python)
这样就可以得到我们自己的词典了。
那为什么我们不直接把最初的三篇文档先合并再去重,这样不就可以省去对三篇文档分别去重这一步了吗?事实上我们也是这样做的,上面是为了便于我们理解我们的文档频率df是怎么计算出来的,由红色字体部分我们可以知道,有多少个重复的词,这个词的的文档频率就是多少。比如html的df为2,java的为2,python为1.
在中文分词系统中,我们采用的是分词工具SCWS,使用PHP调用他提供的方法get_tops可以得到分词的情况,在内部他已经帮我们对每篇文档去了重,并且计算出了每个词的出现的次数times。
我们先来了解一下初始配置文件init.inc.php
<?php define('TEXT_PATH','D:\AppServ\www\BlindFeedback\SogouC.mini.20061127\SogouC.mini\Sample\C000010'); define('ROOT_PATH',dirname(__FILE__)); require_once 'func.inc.php'; require_once 'Tool.class.php'; ?>此文件定义了两个常量,TEXT_PATH是保存搜狗实验室的10篇IT新闻的硬路径,ROOT_PATH是系统存储位置的硬路径;然后是require引入的两个文件,func.inc.php用来存放使用到的函数,以后会讲到;Tool.class.php存放系统主要的功能,随着功能的增多,可能会再创建一个类。以后需要用到的配置都存放到这个文件中。
在Tool.class.php文件中我们定义了一个静态方法,用来获得并存储词表:
class Tool{ //获取并存储词表 static public function dic($seg){ $dic=array(); //词表 for($i=0;$i<count($seg);$i++){ for($j=0;$j<count($seg[$i]);$j++){ array_push($dic,$seg[$i][$j]['word']); } } $dic=array_unique($dic); sort($dic); $dic=implode(',',$dic); //把词表存储起来 $fp=fopen('dic.txt','w'); if(!$fp) exit('词典打开失败!'); if(!fwrite($fp,$dic)) exit('词典写入失败!'); fclose($fp); } ?>这个方法需要传递一个参数,这个参数是由Tool.class.php里定义的一个分词方法segment得来的,稍后会讲到。变量$seg是一个三维数组,$seg[i][j][]表示第i篇文档的第j个词。通过两个for循环,把该词压入数组$dic中(array_push方法可以压入具有相同值的元素),然后array_unique对$dic去重,再按中文拼音字母升序排列,一个数组形式的词表产生了。为了把该词表存入文件名为dic的txt文件中,需要使用imploded方法把数组通过“,”连接成字符串,然后在使用文件方法fopen把词表存入dic.txt.
上面提到的segment分词方法代码如下:
//scws分词 static function segment($str){ if(!$scws=scws_new()) exit('创建SCWS对象失败!'); //创建SCWS $scws->set_charset('gbk'); //设置字符集 if(!$scws->set_dict('C:\Program Files\scws\dict.xdb')) exit('词典路径设置失败!'); $scws->set_multi(1); $scws->set_ignore(true); //忽略标点 if(is_string($str)){ $scws->send_text($str); $top=$scws->get_tops(800); }else if(is_array($str)){ for($i=0;$i<count($str);$i++){ $scws->send_text($str[$i]['con']); $top[]=$scws->get_tops(800); } } return $top; }该方法需要传第一个参数该参数可以说字符串,也可以是包含内容的数组。可以使用下面介绍的fileStr方法获取10篇IT新闻的内容并把它们存入数组中。segment方法内部都是调用SCWS提供的分词方法,如需详细了解可以到SCWS官网查看文档(该项目开源)。笔者只介绍get_tops方法,该方法返回的是最终的分词结果:

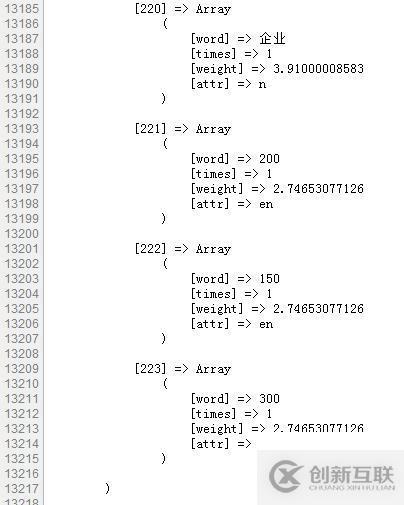
由于词的数量太多,以后实验效果截图只截取前面和最后的部分。可以看到get_tops的返回结果是一个三维数组[word]表示所截取的词,[times]表示词频,[weight]表示权重(不是我们所了解的tf*idf),[attr]表示词性。get_tops方法已经为我们除去了大部分无意义的词。与get_tops相对应的是get_result,它返回的是所有分好的词,包括停用词、标点符号等。
另外有需要云服务器可以了解下创新互联cdcxhl.cn,海内外云服务器15元起步,三天无理由+7*72小时售后在线,公司持有idc许可证,提供“云服务器、裸金属服务器、高防服务器、香港服务器、美国服务器、虚拟主机、免备案服务器”等云主机租用服务以及企业上云的综合解决方案,具有“安全稳定、简单易用、服务可用性高、性价比高”等特点与优势,专为企业上云打造定制,能够满足用户丰富、多元化的应用场景需求。
本文名称:盲反馈检索系统实验记录一-创新互联
链接地址:https://www.cdcxhl.com/article32/csoesc.html
成都网站建设公司_创新互联,为您提供做网站、商城网站、搜索引擎优化、网页设计公司、小程序开发、手机网站建设
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 营销型网站建设费用高低与什么有关 2016-10-30
- 营销型网站建设都拥有什么优势和价值? 2022-11-24
- 高质量的营销型网站建设应符合哪些要求呢 2021-09-25
- 怎样实现营销型网站建设的扫码登录 2016-10-26
- 利用营销型网站建设做好互联网营销 2013-06-30
- 相信大家都知道优秀的营销型网站建设工作,往往都需要建站时的精益求精 2021-05-09
- 营销型网站建设的推广公式 2023-01-29
- 如何实现营销型网站建设推广的终极目标 2013-06-14
- 对企业网站来说,什么样的营销型网站建设才有价值? 2021-03-02
- 营销型网站建设的价格 2021-04-18
- 营销型网站建设流程 2022-11-06
- 重庆营销型网站建设概念 2021-01-15