如何加快pandas计算速度
小编给大家分享一下如何加快pandas计算速度,相信大部分人都还不怎么了解,因此分享这篇文章给大家参考一下,希望大家阅读完这篇文章后大有收获,下面让我们一起去了解一下吧!
在沅陵等地区,都构建了全面的区域性战略布局,加强发展的系统性、市场前瞻性、产品创新能力,以专注、极致的服务理念,为客户提供成都做网站、成都网站建设 网站设计制作按需搭建网站,公司网站建设,企业网站建设,成都品牌网站建设,成都全网营销,外贸营销网站建设,沅陵网站建设费用合理。
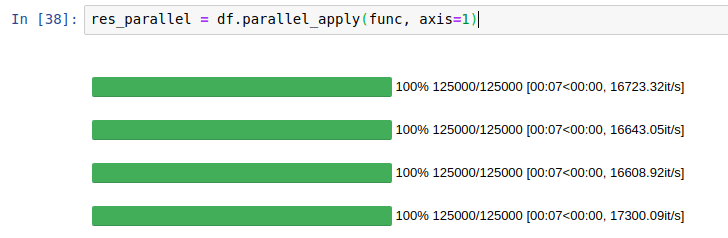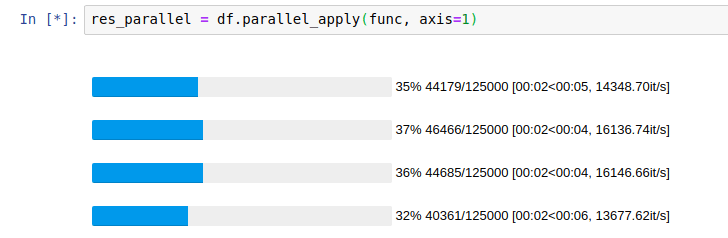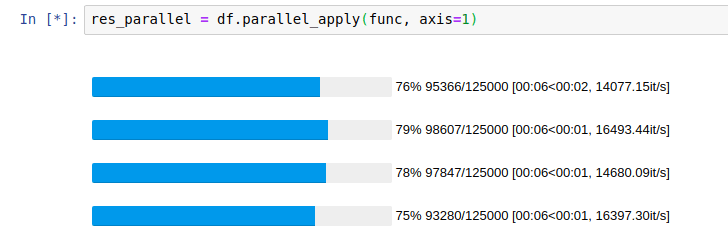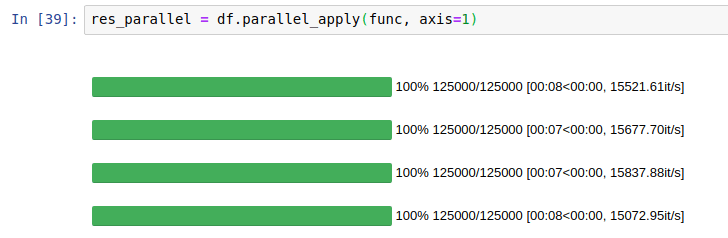
什么问题困扰我们?
使用pandas,当您运行以下行时:
# Standard apply
df.apply(func)
得到这个CPU使用率:
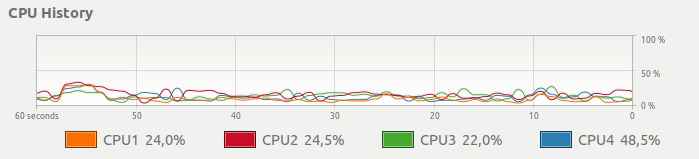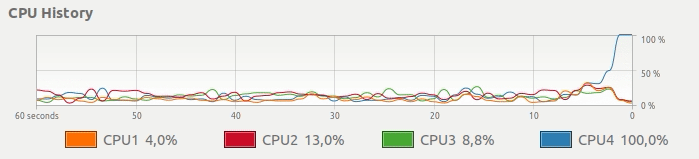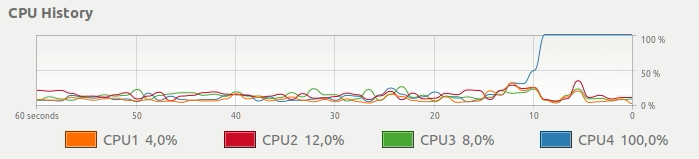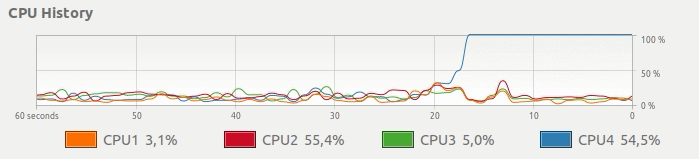
标准pandas适用 - 仅使用1个CPU
即使计算机有多个CPU,也只有一个完全专用于您的计算。
而不是下边这种CPU使用,想要一个简单的方法来得到这样的东西:
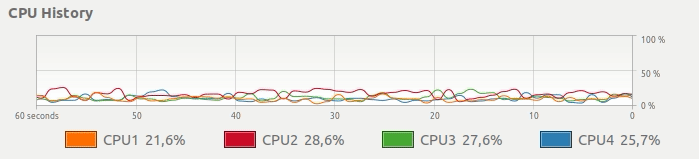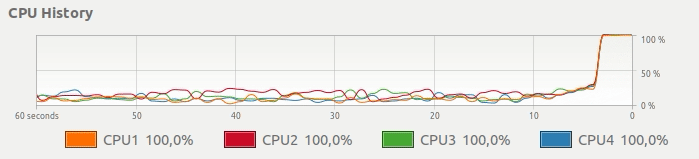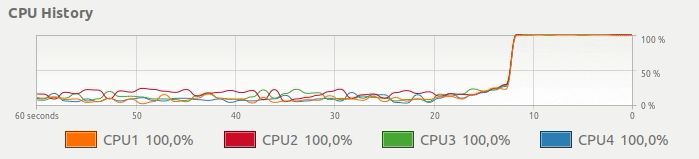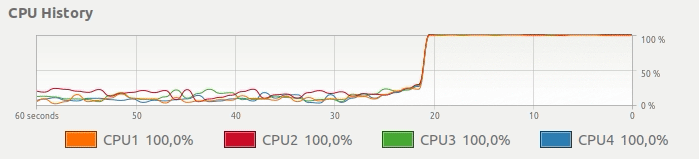
并行Pandas适用 - 使用所有CPU
Pandaral·lel 如何帮助解决这个问题?
Pandaral·lel 的想法是将pandas计算分布在计算机上所有可用的CPU上,以显着提高速度。
安装:
$ pip install pandarallel [--user]
导入和初始化:
# Import
from pandarallel import pandarallel
# Initialization
pandarallel.initialize()
用法:
使用带有pandas DataFrame的简单用例df和要应用的函数func,只需替换经典apply的parallel_apply。
# Standard pandas apply
df.apply(func)
# Parallel apply
df.parallel_apply(func)
做完了!
请注意如果不想并行化计算,仍然可以使用经典apply方法。
也可以通过将显示每个工作CPU一个进度条progress_bar=True的initialize功能。
并行应用进度条
并配有更复杂的情况下使用带有pandas DataFrame df,该数据帧的两列column1,column2和功能应用func:
# Standard pandas apply
df.groupby(column1).column2.rolling(4).apply(func)
# Parallel apply
df.groupby(column1).column2.rolling(4).parallel_apply(func)
基准
对于此处提供的四个示例,请执行以下配置:
https://github.com/nalepae/pandarallel/blob/master/docs/examples.ipynb
操作系统:Linux Ubuntu 16.04
硬件:Intel Core i7 @ 3.40 GHz - 4核
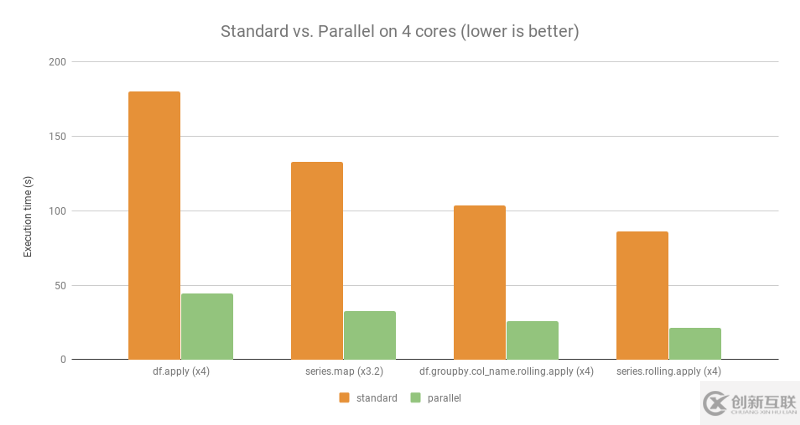
4核上的标准与并行(越低越好)
除了df.groupby.col_name.rolling.apply速度仅增加x3.2因子之外,平均速度增加约x4因子,即使用过的计算机上的核心数。
它是如何在引擎盖下工作的?
调用parallel_apply时,Pandaral·lel:
实例化一个Pyarrow Plasma共享内存
https://arrow.apache.org/docs/python/plasma.html
为每个CPU创建一个子进程,然后要求每个CPU在DataFrame的子部分上工作
将所有结果合并到父进程中
以上是“如何加快pandas计算速度”这篇文章的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注创新互联行业资讯频道!
网站名称:如何加快pandas计算速度
分享地址:https://www.cdcxhl.com/article30/jdhjso.html
成都网站建设公司_创新互联,为您提供手机网站建设、商城网站、网站排名、静态网站、外贸网站建设、网站导航
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 成都软件开发是由有那些方面组成的? 2022-06-16
- App软件开发必须解决的“疑难杂症”和解决方法 2022-05-07
- 电商APP软件开发应如何选择软件开发公司? 2020-11-13
- 软件开发行业如何在激烈竞争中取胜 2016-08-30
- 生活服务APP软件开发有哪些优势和价值 2020-12-09
- 软件开发课堂:智能语音能代替人吗? 2021-06-03
- 云计算理念将拉动软件开发迈入开发即服务(DaaS)的新阶段 2021-02-18
- 上海app软件开发如何找到切入点 2021-01-01
- 软件开发中,我们应该保持的工匠心态 2021-05-14
- 成都软件开发简述传统企业如何实现网络营销 2022-06-07
- 选择软件开发的时容易犯的错误 2017-01-05
- 创新互联:APP软件开发和小程序有什么区别 2022-12-01