Python中怎么PDF文件提取数据
这篇文章将为大家详细讲解有关Python中怎么PDF文件提取数据,文章内容质量较高,因此小编分享给大家做个参考,希望大家阅读完这篇文章后对相关知识有一定的了解。
10年积累的做网站、网站设计经验,可以快速应对客户对网站的新想法和需求。提供各种问题对应的解决方案。让选择我们的客户得到更好、更有力的网络服务。我虽然不认识你,你也不认识我。但先网站设计后付款的网站建设流程,更有振安免费网站建设让你可以放心的选择与我们合作。
示例:使用Python从PDF文件中提取一个表格
a) 将表复制到Excel并保存为table_1_raw.csv
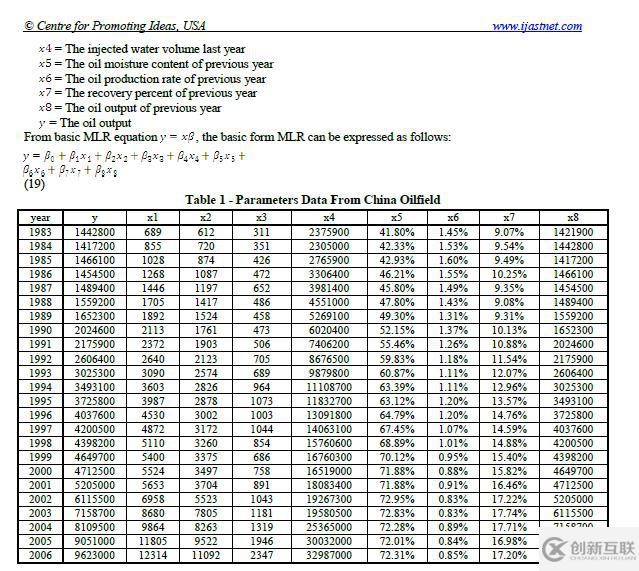
数据以一维格式存储,必须进行重塑、清理和转换。
b) 导入必要的库
import pandas as pd import numpy as np
c) 导入原始数据,重新定义数据
df=pd.read_csv("table_1_raw.csv", header=None) df.values.shape df2=pd.DataFrame(df.values.reshape(25,10)) column_names=df2[0:1].values[0] df3=df2[1:] df3.columns = df2[0:1].values[0] df3.head()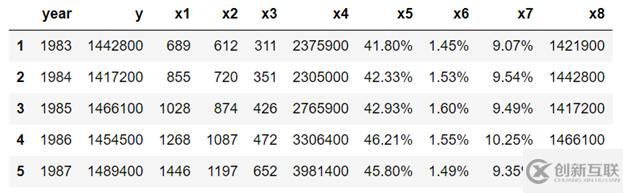
d) 使用字符串处理工具进行数据纠缠
我们从上面的表格中注意到,x5、x6和x7列是用百分比表示的,所以我们需要去掉percent(%)符号:
df4['x5']=list(map(lambda x: x[:-1], df4['x5'].values)) df4['x6']=list(map(lambda x: x[:-1], df4['x6'].values)) df4['x7']=list(map(lambda x: x[:-1], df4['x7'].values))
e) 将数据转换为数字形式
我们注意到列x5、x6和x7的列值数据类型为string,因此我们需要将它们转换为数值数据,如下所示:
df4['x5']=[float(x) for x in df4['x5'].values] df4['x6']=[float(x) for x in df4['x6'].values] df4['x7']=[float(x) for x in df4['x7'].values]
f) 查看转换数据的最终形式
df4.head(n=5)
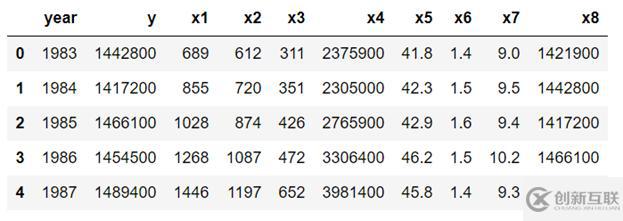
g) 导出最终数据到一个csv文件
df4.to_csv('table_1_final.csv',index=False)关于Python中怎么PDF文件提取数据就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
网站标题:Python中怎么PDF文件提取数据
网站路径:https://www.cdcxhl.com/article30/igjhpo.html
成都网站建设公司_创新互联,为您提供企业网站制作、移动网站建设、网站建设、云服务器、响应式网站、面包屑导航
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 未来年网站制作的发展趋势。 2018-11-09
- 网站制作不可不知的知识技能 2023-01-31
- 企业网站设计如何制作?企业网站制作需要注意哪些方面? 2021-01-28
- 长沙企业怎么运营网站制作公司能实现可观的转化收益? 2022-05-27
- APP开发前需要注意什么 2016-11-04
- 网站制作公司的核心是什么 2022-12-19
- 企业网站制作如何更具“特点” 2021-05-21
- 网站制作浅谈网站数据处理的欺骗性 2021-08-29
- 企业的手机网站制作更有优势吗 2021-09-01
- 从搜索引擎蜘蛛的角度改善网站无法被收录的情况 2015-03-29
- 网站制作时主要的划分要求要有那些呢 2016-10-28
- 成都网站建设谈企业网站制作要符合访客心理属性 2016-10-17