R的一些统计分析包工具-创新互联
【另附】:R语言简明笔记系列
1.1. 描述性统计分析
1.1.1. 描述性统计量的计算
1.1.1.1. summary()
> vars<-c("mpg","hp","wt")
> head(mtcars[vars])
mpg hp wt
Mazda RX4 21.0 110 2.620
Mazda RX4 Wag 21.0 110 2.875
Datsun 710 22.8 93 2.320
Hornet 4 Drive 21.4 110 3.215
Hornet Sportabout 18.7 175 3.440
Valiant 18.1 105 3.460
> summary(mtcars[vars])
mpg hp wt
Min. :10.40 Min. : 52.0 Min. :1.513
1st Qu.:15.43 1st Qu.: 96.5 1st Qu.:2.581
Median :19.20 Median :123.0 Median :3.325
Mean :20.09 Mean :146.7 Mean :3.217
3rd Qu.:22.80 3rd Qu.:180.0 3rd Qu.:3.610
Max. :33.90 Max. :335.0 Max. :5.424
</pre>
>**`summary()`** 函数提供最小值、大值、四分位数和数值型变量的均值,以及因子向量和逻辑型向量的频数统计1.1.1.2. describe() 【Hmisc包】
> library(Hmisc) 载入需要的程辑包:grid 载入需要的程辑包:lattice 载入需要的程辑包:survival 载入需要的程辑包:Formula 载入需要的程辑包:ggplot2 载入程辑包:‘Hmisc’ The following objects are masked from ‘package:base’: format.pval, round.POSIXt, trunc.POSIXt, units > describe(mtcars[vars]) mtcars[vars] 3 Variables 32 Observations ------------------------------------------------------------------------------------------------ mpg n missing unique Info Mean .05 .10 .25 .50 .75 .90 .95 32 0 25 1 20.09 12.00 14.34 15.43 19.20 22.80 30.09 31.30 lowest : 10.4 13.3 14.3 14.7 15.0, highest: 26.0 27.3 30.4 32.4 33.9 ------------------------------------------------------------------------------------------------ hp n missing unique Info Mean .05 .10 .25 .50 .75 .90 .95 32 0 22 1 146.7 63.65 66.00 96.50 123.00 180.00 243.50 253.55 lowest : 52 62 65 66 91, highest: 215 230 245 264 335 ------------------------------------------------------------------------------------------------ wt n missing unique Info Mean .05 .10 .25 .50 .75 .90 .95 32 0 29 1 3.217 1.736 1.956 2.581 3.325 3.610 4.048 5.293 lowest : 1.513 1.615 1.835 1.935 2.140, highest: 3.845 4.070 5.250 5.345 5.424 ------------------------------------------------------------------------------------------------
1.1.1.3. stat.desc() 【pastecs包】
> library(pastecs) 载入需要的程辑包:boot > stat.desc(mtcars[vars]) mpg hp wt nbr.val 32.0000000 32.0000000 32.0000000 nbr.null 0.0000000 0.0000000 0.0000000 nbr.na 0.0000000 0.0000000 0.0000000 min 10.4000000 52.0000000 1.5130000 max 33.9000000 335.0000000 5.4240000 range 23.5000000 283.0000000 3.9110000 sum 642.9000000 4694.0000000 102.9520000 median 19.2000000 123.0000000 3.3250000 mean 20.0906250 146.6875000 3.2172500 SE.mean 1.0654240 12.1203173 0.1729685 CI.mean.0.95 2.1729465 24.7195501 0.3527715 var 36.3241028 4700.8669355 0.9573790 std.dev 6.0269481 68.5628685 0.9784574 coef.var 0.2999881 0.4674077 0.3041285
1.1.1.4. describe() 【psych包】
> library(psych) 载入程辑包:‘psych’ The following object is masked from ‘package:boot’: logit > describe(mtcars[vars]) vars n mean sd median trimmed mad min max range skew kurtosis se mpg 1 32 20.09 6.03 19.20 19.70 5.41 10.40 33.90 23.50 0.61 -0.37 1.07 hp 2 32 146.69 68.56 123.00 141.19 77.10 52.00 335.00 283.00 0.73 -0.14 12.12 wt 3 32 3.22 0.98 3.33 3.15 0.77 1.51 5.42 3.91 0.42 -0.02 0.17
1.1.2. 分组计算描述性统计量
在比较多组个体或观测时,关注的焦点经常是各组的描述性统计信息,而不是样本整体的描述性统计信息。同样地,在R中完成这个任务有若干种方法。我们将以获取变速箱类型各水平的描述性统计量开始。

1.1.2.1. aggregate()
> aggregate(mtcars[vars], by=list(am=mtcars$am),mean) am mpg hp wt 1 0 17.1 160 3.77 2 1 24.4 127 2.41 > aggregate(mtcars[vars],by=list(am=mtcars$am),sd) am mpg hp wt 1 0 3.83 53.9 0.777 2 1 6.17 84.1 0.617 </pre> >由上面的分析结果可看出,am有两个值,根据am的两个值将`mtcars`数据集分为两组,得出上面的`mpg`, `hp`, `wt` 的平均值以及标准差。<br> >其中, **`list(am=mtcars$am)`** 的使用,将 `am` 列标注为一个更有帮助的列标签,而非 `Group.1`。<br> >遗憾的是,aggregate()仅允许在每次调用中使用平均数、标准差这样的单返回值函数。它无法一次返回若干个统计量。要完成这项任务,可以使用 **`by()`** 函数。
1.1.2.2. by()
> by(mtcars[vars],mtcars$am,summary) mtcars$am: 0 mpg hp wt Min. :10.4 Min. : 62 Min. :2.46 1st Qu.:14.9 1st Qu.:116 1st Qu.:3.44 Median :17.3 Median :175 Median :3.52 Mean :17.1 Mean :160 Mean :3.77 3rd Qu.:19.2 3rd Qu.:192 3rd Qu.:3.84 Max. :24.4 Max. :245 Max. :5.42 --------------------------------------------------------------------------------------------------- mtcars$am: 1 mpg hp wt Min. :15.0 Min. : 52 Min. :1.51 1st Qu.:21.0 1st Qu.: 66 1st Qu.:1.94 Median :22.8 Median :109 Median :2.32 Mean :24.4 Mean :127 Mean :2.41 3rd Qu.:30.4 3rd Qu.:113 3rd Qu.:2.78 Max. :33.9 Max. :335 Max. :3.57
1.1.2.3. 拓展
1.1.2.4. summaryBy() 【doBy包】
格式:summaryBy(formula, dataframe, FUN=function)
> **`formula`** 支持格式:<br> > **var1 + var2 + var3 + …… +varN ~ groupvar1 + groupvar2 + …… +groupvarN**<br> > **`~`** 左边的变量是需要分析的数值型变量,右侧的变量是类别性的分组变量。<br> > **`function`** 可为任何内建或用户自编的R函数。 <pre> > library(doBy) 载入需要的程辑包:survival 载入程辑包:‘survival’ The following object is masked from ‘package:boot’: aml > summaryBy(mpg+hp+wt~am,data=mtcars,FUN=mystats) am mpg.n mpg.mean mpg.stdev mpg.skew mpg.kurtosis hp.n hp.mean hp.stdev hp.skew hp.kurtosis wt.n wt.mean wt.stdev 1 0 19 17.14737 3.833966 0.01395038 -0.8031783 19 160.2632 53.90820 -0.01422519 -1.2096973 19 3.768895 0.7774001 2 1 13 24.39231 6.166504 0.05256118 -1.4553520 13 126.8462 84.06232 1.35988586 0.5634635 13 2.411000 0.6169816 wt.skew wt.kurtosis 1 0.9759294 0.1415676 2 0.2103128 -1.1737358
1.1.2.5. describe.by() 【psych包】
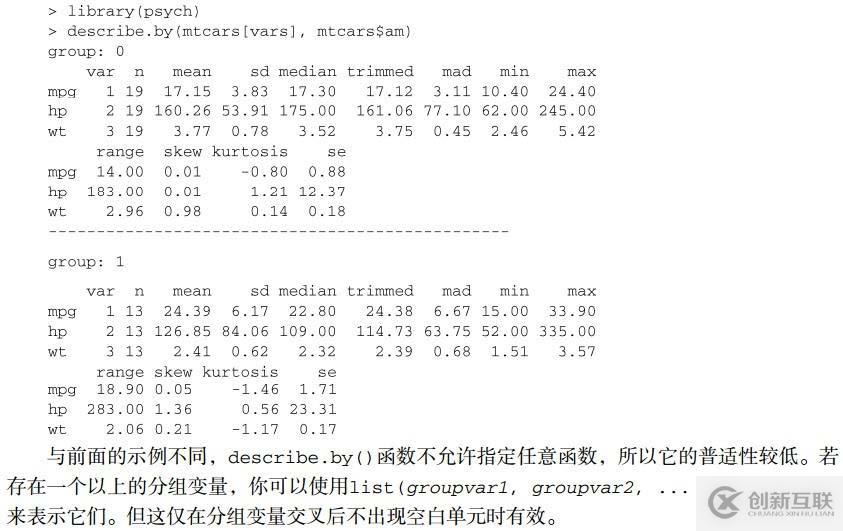
1.1.3. 使用reshape包导出描述性统计量
> library(reshape)
> dstats <- function(x) (c(n=length(x), mean=mean(x), sd=sd(x))
+ )
> dfm <- melt(mtcars, measure.vars=c("mpg","hp","wt"),id.vars=c("am","cyl"))
> cast(dfm,am+cyl+variable~.,dstats)
am cyl variable n mean sd
1 0 4 mpg 3 22.900000 1.4525839
2 0 4 hp 3 84.666667 19.6553640
3 0 4 wt 3 2.935000 0.4075230
4 0 6 mpg 4 19.125000 1.6317169
5 0 6 hp 4 115.250000 9.1787799
6 0 6 wt 4 3.388750 0.1162164
7 0 8 mpg 12 15.050000 2.7743959
8 0 8 hp 12 194.166667 33.3598379
9 0 8 wt 12 4.104083 0.7683069
10 1 4 mpg 8 28.075000 4.4838599
11 1 4 hp 8 81.875000 22.6554156
12 1 4 wt 8 2.042250 0.4093485
13 1 6 mpg 3 20.566667 0.7505553
14 1 6 hp 3 131.666667 37.5277675
15 1 6 wt 3 2.755000 0.1281601
16 1 8 mpg 2 15.400000 0.5656854
17 1 8 hp 2 299.500000 50.2045815
18 1 8 wt 2 3.370000 0.28284271.1.4. 结果可视化
分布特征的数值刻画的确很重要,但是这并不能代替视觉呈现。对于定量变量,我们有直方 图(6.3节)、密度图(6.4节)、箱线图(6.5节)和点图(6.6节)。它们都可以让我们洞悉那些依 赖于观察一小部分描述性统计量时忽略的细节。
目前我们考虑的函数都是为定量变量提供概述的。下一节中的函数则允许考察类别型变量的 分布。
1.2. 频数表和列联表
1.2.1. 生成频数表
1.2.1.1. 一维列联表

> mytable<-with(Arthritis,table(Improved)) > mytable Improved None Some Marked 42 14 28 > prop.table(mytable) Improved None Some Marked 0.5000000 0.1666667 0.3333333 > prop.table(mytable)*100 Improved None Some Marked 50.00000 16.66667 33.33333
1.2.1.2. 二维列联表
> attach(Arthritis)
> mytable1<-xtabs(~Treatment+Improved,data=Arthritis)
> mytable1
Improved
Treatment None Some Marked
Placebo 29 7 7
Treated 13 7 21
> margin.table(mytable1,1)
Treatment
Placebo Treated
43 41
> margin.table(mytable1,2)
Improved
None Some Marked
42 14 28
> prop.table(mytable,2)
Error in if (d2 == 0L) { : 需要TRUE/FALSE值的地方不可以用缺少值
> prop.table(mytable1,2)
Improved
Treatment None Some Marked
Placebo 0.6904762 0.5000000 0.2500000
Treated 0.3095238 0.5000000 0.7500000
> addmargins(mytable1)
Improved
Treatment None Some Marked Sum
Placebo 29 7 7 43
Treated 13 7 21 41
Sum 42 14 28 84
> addmargins(prop.table(mytable1))
Improved
Treatment None Some Marked Sum
Placebo 0.34523810 0.08333333 0.08333333 0.51190476
Treated 0.15476190 0.08333333 0.25000000 0.48809524
Sum 0.50000000 0.16666667 0.33333333 1.00000000
> addmargins(prop.table(mytable1),2)
Improved
Treatment None Some Marked Sum
Placebo 0.34523810 0.08333333 0.08333333 0.51190476
Treated 0.15476190 0.08333333 0.25000000 0.48809524
table(A,B);
xtabs(~A+B,data=mydata):~符号右方出现的为要进行交叉分类的变量,以+作为分隔;
margin.table(table(A,B) or xtabs.table(~A+B),no.ofvariables): 生成边际频数和比例
prop.table(table(A,B),no.ofvariables): 生成比例
addmargins(table(A,B) or xtabs.table(~A+B) or prop.table(mytable1), no.ofvariables): 增加第几个变量的合计,如果不加no.ofvariables则都加;
1.2.1.3. 三维列联表
> mytable2<-xtabs(~Treatment+Sex+Improved,data=Arthritis) > mytable2 , , Improved = None Sex Treatment Female Male Placebo 19 10 Treated 6 7 , , Improved = Some Sex Treatment Female Male Placebo 7 0 Treated 5 2 , , Improved = Marked Sex Treatment Female Male Placebo 6 1 Treated 16 5 > ftable(mytable2) Improved None Some Marked Treatment Sex Placebo Female 19 7 6 Male 10 0 1 Treated Female 6 5 16 Male 7 2 5 > margin.table(mytable2,1) Treatment Placebo Treated 43 41 > margin.table(mytable2,2) Sex Female Male 59 25 > margin.table(mytable2,2) Sex Female Male 59 25 > margin.table(mytable2,3) Improved None Some Marked 42 14 28 > margin.table(mytable2,c(1,2,3)) , , Improved = None Sex Treatment Female Male Placebo 19 10 Treated 6 7 , , Improved = Some Sex Treatment Female Male Placebo 7 0 Treated 5 2 , , Improved = Marked Sex Treatment Female Male Placebo 6 1 Treated 16 5 > margin.table(mytable2,c(1,3)) Improved Treatment None Some Marked Placebo 29 7 7 Treated 13 7 21 > ftable(prop.table(mytable2,c(2,3)) + ) Improved None Some Marked Treatment Sex Placebo Female 0.7600000 0.5833333 0.2727273 Male 0.5882353 0.0000000 0.1666667 Treated Female 0.2400000 0.4166667 0.7272727 Male 0.4117647 1.0000000 0.8333333 > ftable(addmargins(prop.table(mytable2,c(1,2)),3))*100 Improved None Some Marked Sum Treatment Sex Placebo Female 59.375000 21.875000 18.750000 100.000000 Male 90.909091 0.000000 9.090909 100.000000 Treated Female 22.222222 18.518519 59.259259 100.000000 Male 50.000000 14.285714 35.714286 100.000000
1.2.1.4. 独立性检验
1.2.1.4.1. 卡方独立性检验
> mytable3<-xtabs(~Treatment+Improved,data=Arthritis);mytable3 Improved Treatment None Some Marked Placebo 29 7 7 Treated 13 7 21 > chisq.test(mytable3) Pearson's Chi-squared test data: mytable3 X-squared = 13.055, df = 2, p-value = 0.001463
1.2.1.4.2. Fisher精确检验
> mytable4<-xtabs(~Treatment+Improved,data=Arthritis);mytable4 Improved Treatment None Some Marked Placebo 29 7 7 Treated 13 7 21 > fisher.test(mytable4) Fisher's Exact Test for Count Data data: mytable4 p-value = 0.001393 alternative hypothesis: two.sided
1.2.1.4.3. Cochran-Mantel-Haenszel检验
> mytable5<-xtabs(~Treatment+Improved+Sex, data=Arthritis) > mantelhaen.test(mytable5) Cochran-Mantel-Haenszel test data: mytable5 Cochran-Mantel-Haenszel M^2 = 14.632, df = 2, p-value = 0.0006647
另外有需要云服务器可以了解下创新互联scvps.cn,海内外云服务器15元起步,三天无理由+7*72小时售后在线,公司持有idc许可证,提供“云服务器、裸金属服务器、高防服务器、香港服务器、美国服务器、虚拟主机、免备案服务器”等云主机租用服务以及企业上云的综合解决方案,具有“安全稳定、简单易用、服务可用性高、性价比高”等特点与优势,专为企业上云打造定制,能够满足用户丰富、多元化的应用场景需求。
新闻标题:R的一些统计分析包工具-创新互联
网站网址:https://www.cdcxhl.com/article30/egjpo.html
成都网站建设公司_创新互联,为您提供营销型网站建设、静态网站、企业建站、网站设计公司、响应式网站、网站营销
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 移动网站建设需要注意哪些细节 2017-07-03
- 成都网站建设公司浅谈移动网站建设的那些要点分析 2016-11-08
- 移动网站建设相关问题 2021-05-23
- 从用户体验角度介绍移动网站建设需求基本内容 2016-11-30
- 移动网站建设时的哪些要点一定要谨记 2021-03-06
- 成都移动网站建设公司的六大重要步骤 2021-12-09
- 移动网站建设的四个基本要素 2017-01-25
- 移动网站建设十大原则 2022-11-28
- 好的移动网站建设应该满足哪些条件? 2016-10-29
- 无锡企业移动网站建设如何优化 2022-05-31
- 企业移动网站建设需要注意哪些用户反感的设定? 2022-10-25
- 移动网站建设关于用户注册设计的技巧 2021-07-21