redis实践及思考-创新互联
导语:当面临存储选型时是选择关系型还是非关系型数据库? 如果选择了非关系型的redis,redis常用数据类型占用内存大小如何估算的? redis的性能瓶颈又在哪里?

背景前段时间接手了一个业务,响应时间达到 10s左右。 阅读源码后发现,每一次请求都是查询多个分表数据(task1,task2….),然后再join其他表(course,teacher..), 时间全部花在了大量磁盘I/O上。 脑袋一拍,重构,上redis!
为什么选择redis拍脑袋做技术方案肯定是不行的,得用数据和逻辑说服别人才可以。
时延
时延=后端发起请求db(用户态拷贝请求到内核态)+ 网络时延 + 数据库寻址和读取 如果想要降低时延,只能减少请求数(合并多个后端请求)和减少数据库寻址和读取得时间。 从降低时延的角度,基于 单线程和内存的redis,每秒10万次得读写性能肯定远远胜过磁盘读写性能。数据规模
以redis一组K-V为例(”hello” -> “world”),一个简单的set命令最终会产生4个消耗内存的结构。
关于Redis数据存储的细节,又要涉及到内存分配器(如jemalloc),简单说就是存储170字节,其实内存分配器会分配192字节存储。
那么总的花费就是
一个dictEntry,24字节,jemalloc会分配32字节的内存块
一个redisObject,16字节,jemalloc会分配16字节的内存块
一个key,5字节,所以SDS(key)需要5+9=14个字节,jemalloc会分配16字节的内存块
- 一个value,5字节,所以SDS(value)需要5+9=14个字节,jemalloc会分配16字节的内存块
综上,一个dictEntry需要32+16+16+16=80个字节。
上面这个算法只是举个例子,想要更深入计算出redis所有数据结构的内存大小,可以参考 这篇文章 。 笔者使用的是哈希结构,这个业务需求大概一年的数据量是200MB,从使用redis成本上考虑没有问题。需求特点
笔者这个需求背景读多写少,冷数据占比比较大,但数据结构又很复杂(涉及多个维度数据总和),因此只要启动定时任务离线增量写入redis,请求到达时直接读取redis中的数据,无疑可以减少响应时间。
 [ 最终方案 ]
[ 最终方案 ]
redis瓶颈和优化
HGETALL
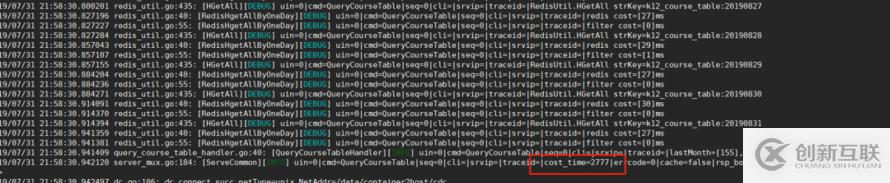
最终存储到redis中的数据结构如下图。
采用同步的方式对三个月(90天)进行HGETALL操作,每一天花费30ms,90次就是2700ms! redis操作读取应该是ns级别的,怎么会这么慢? 利用多核cpu计算会不会更快?
 常识告诉我,redis指令执行速度 >> 网络通信(内网) > read/write等系统调用。
因此这里其实是I/O密集型场景,就算利用多核cpu,也解决不到根本的问题,最终影响redis性能,
**其实是网卡收发数据
和用户态内核态数据拷贝
**。
常识告诉我,redis指令执行速度 >> 网络通信(内网) > read/write等系统调用。
因此这里其实是I/O密集型场景,就算利用多核cpu,也解决不到根本的问题,最终影响redis性能,
**其实是网卡收发数据
和用户态内核态数据拷贝
**。
pipeline
这个需求qps很小,所以网卡也不是瓶颈了,想要把需求优化到1s以内,减少I/O的次数是关键。 换句话说, 充分利用带宽,增大系统吞吐量。于是我把代码改了一版,原来是90次I/O,现在通过redis pipeline操作,一次请求半个月,那么3个月就是6次I/O。 很开心,时间一下子少了1000ms。
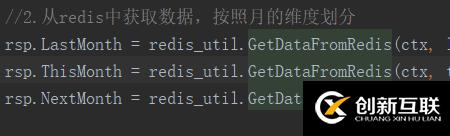

pipeline携带的命令数
代码写到这里,我不经反问自己,为什么一次pipeline携带15个HGETALL命令,不是30个,不是40个? 换句话说,一次pipeline携带多少个HGETALL命令才会发起一次I/O?我使用是golang的 redisgo 的客户端,翻阅源码发现,redisgo执行pipeline逻辑是 把命令和参数写到golang原生的bufio中,如果超过bufio默认大值(4096字节),就发起一次I/O,flush到内核态。
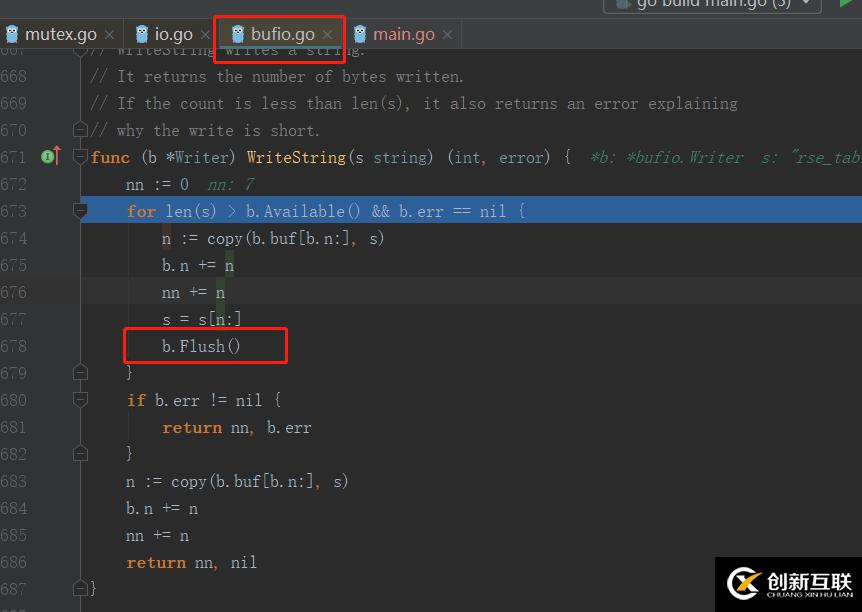
redisgo编码pipeline规则 如下图, *表示后面参数加命令的个数,$表示后面的字符长度 ,一条HGEALL命令实际占45字节。
那其实90天数据,一次I/O就可以搞定了(90 * 45 < 4096字节)!

果然,又快了1000ms,耗费时间达到了1秒以内

对吞吐量和qps的取舍
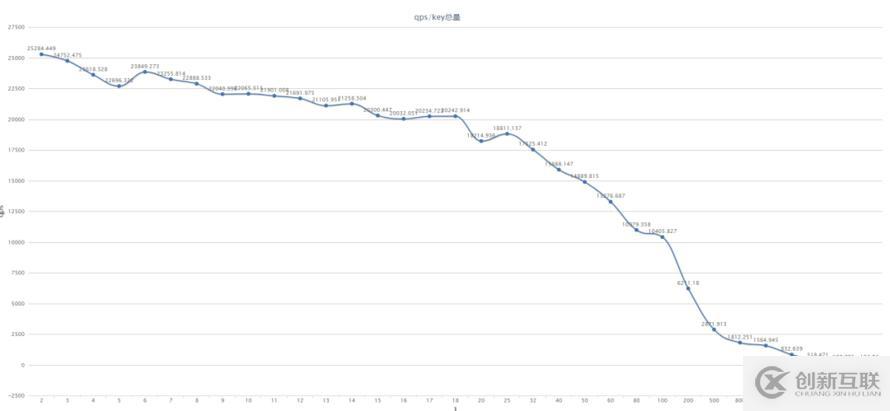
笔者需求任务算是完成了,可是再进一步思考,redis的pipeline一次性带上多少HGETALL操作的key才是合理的呢? 换句话说,服务器吞吐量大了,可能就会导致qps急剧下降(网卡大量收发数据和redis内部协议解析,redis命令排队堆积,从而导致的缓慢),而想要qps高,服务器吞吐量可能就要降下来,无法很好的利用带宽。 对两者之间的取舍,同样是不能拍脑袋决定的,用压测数据说话!简单写了一个压测程序,通过比较请求量和qps的关系,来看一下吞吐量和qps的变化,从而选择一个适合业务需求的值。
package main
import (
"crypto/rand"
"fmt"
"math/big"
"strconv"
"time"
"github.com/garyburd/redigo/redis"
)
const redisKey = "redis_test_key:%s"
func main() {
for i := 1; i < 10000; i++ {
testRedisHGETALL(getPreKeyAndLoopTime(i))
}
}
func testRedisHGETALL(keyList [][]string) {
Conn, err := redis.Dial("tcp", "127.0.0.1:6379")
if err != nil {
fmt.Println(err)
return
}
costTime := int64(0)
start := time.Now().Unix()
for _, keys := range keyList {
for _, key := range keys {
Conn.Send("HGETALL", fmt.Sprintf(redisKey, key))
}
Conn.Flush()
}
end := time.Now().Unix()
costTime = end - start
fmt.Printf("cost_time=[%+v]ms,qps=[%+v],keyLen=[%+v],totalBytes=[%+v]",
1000*int64(len(keyList))/costTime, costTime/int64(len(keyList)), len(keyList), len(keyList)*len(keyList[0])*len(redisKey))
}
//根据key的长度,设置不同的循环次数,平均计算,取除网络延迟带来的影响
func getPreKeyAndLoopTime(keyLen int) [][]string {
loopTime := 1000
if keyLen < 10 {
loopTime *= 100
} else if keyLen < 100 {
loopTime *= 50
} else if keyLen < 500 {
loopTime *= 10
} else if keyLen < 1000 {
loopTime *= 5
}
return generateKeys(keyLen, loopTime)
}
func generateKeys(keyLen, looTime int) [][]string {
keyList := make([][]string, 0)
for i := 0; i < looTime; i++ {
keys := make([]string, 0)
for i := 0; i < keyLen; i++ {
result, _ := rand.Int(rand.Reader, big.NewInt(100))
keys = append(keys, strconv.FormatInt(result.Int64(), 10))
}
keyList = append(keyList, keys)
}
return keyList
}
windows上单机版redis结果如下:
扩展 (分布式方案下pipeline操作)需求最终是完成了,可是转念一想,现在都是集群版的redis,pipeline批量请求的key可能分布在不同的机器上,但pipeline请求最终可能只被一台redis server处理,那不就是会读取数据失败吗? 于是,笔者查找几个通用的redis 分布式方案,看看他们是如何处理这pipeline问题的。
redis cluster
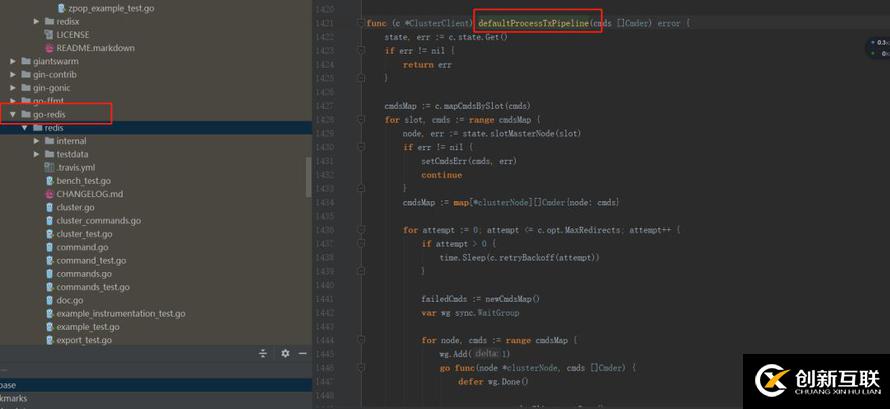
redis cluster 是官方给出的分布式方案。 Redis Cluster在设计中没有使用一致性哈希,而是使用数据分片(Sharding)引入哈希槽(hash slot)来实现。 一个 Redis Cluster包含16384(0~16383)个哈希槽,存储在Redis Cluster中的所有键都会被映射到这些slot中,集群中的每个键都属于这16384个哈希槽中的一个,集群使用公式slot=CRC16 key/16384来计算key属于哪个槽。 比如redis cluster有5个节点,每个节点就负责一部分哈希槽, 如果参数的多个key在不同的slot,在不同的主机上,那么必然会出错。因此redis cluster分布式方案是不支持pipeline操作,如果想要做,只有客户端缓存slot和redis节点的关系,在批量请求时,就通过key算出不同的slot以及redis节点,并行的进行pipeline。
github.com/go-redis就是这样做的,有兴趣可以阅读下源码。
codis
市面上还流行着一种在客户端和服务端之间增设代理的方案,比如codis就是这样。 对于上层应用来说,连接 Codis-Proxy 和直接连接 原生的 Redis-Server 没有的区别,也就是说codis-proxy会帮你做上面并行分槽请求redis server,然后合并结果在一起的操作,对于使用者来说无感知。总结在做需求的过程中,发现了很多东西不能拍脑袋决定,而是前期做技术方案的时候,想清楚,调研好,用数据和逻辑去说服自己。
标题名称:redis实践及思考-创新互联
网页链接:https://www.cdcxhl.com/article30/djegpo.html
成都网站建设公司_创新互联,为您提供企业建站、标签优化、自适应网站、商城网站、App开发、企业网站制作
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 网站出现重复内容会对Google SEO优化有何影响? 2013-07-20
- Google优化推广的重要性,品牌大于品质! 2016-03-08
- Google对为何对新站都比较敏感呢? 2016-11-21
- Google优化是谷歌推广的最佳选择吗? 2015-01-12
- Google已经正式推出了针对电子邮件的AMP 2019-10-25
- 怎样解决Google有害信息的网站提示 2016-04-10
- 如何有效提高Google自然搜索中网站关键词的排名 2014-02-26
- 百度与Google做SEO的方式不同,主要有两大因素:算法和搜索结果页。 2016-02-27
- 为什么你的Google推广效果不佳? 2016-03-10
- 做百度的排名和做google搜索引擎优化的差别 2020-03-31
- 外贸网站设计如何被Google快速收录 2016-01-13
- Google外贸网站无排名 做好这7点就对了 2016-03-14