如何使用BeautifulSoup4数据解析实例
小编给大家分享一下如何使用BeautifulSoup4数据解析实例,相信大部分人都还不怎么了解,因此分享这篇文章给大家参考一下,希望大家阅读完这篇文章后大有收获,下面让我们一起去了解一下吧!
10年积累的成都做网站、成都网站设计经验,可以快速应对客户对网站的新想法和需求。提供各种问题对应的解决方案。让选择我们的客户得到更好、更有力的网络服务。我虽然不认识你,你也不认识我。但先网站制作后付款的网站建设流程,更有滨江免费网站建设让你可以放心的选择与我们合作。
这里以爬取三国演义所有章节为例。
1.爬取要求是爬取三国演义的所有章节
2.目标地址:https://www.shicimingju.com/book/sanguoyanyi.html
3.代码
from bs4 import BeautifulSoupimport requestsif __name__ == '__main__':headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'}url = 'https://www.shicimingju.com/book/sanguoyanyi.html'page_text = requests.get(url=url,headers=headers).text
soup = BeautifulSoup(page_text,'lxml')li_list = soup.select('.book-mulu > ul > li')fp = open('./三国演义小说.txt','w',encoding='utf-8')for li in li_list:title = li.a.string
detail_url = 'https://www.shicimingju.com'+li.a['href']detail_page_text = requests.get(url=detail_url,headers=headers).text
detail_soup = BeautifulSoup(detail_page_text, 'lxml')div_tag = detail_soup.find('div',class_='chapter_content')content = div_tag.text
fp.write('\n' + title + ':' + content +'\n')print(title,'爬取成功')4.出现乱码以及处理
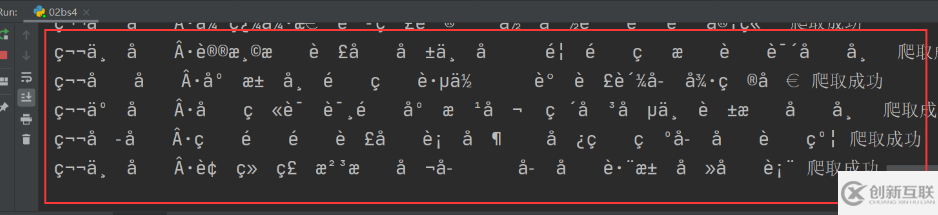
response.text在用文本格式看的时候有乱码,回来的内容可能被压缩了。在此修改response.content.decode(utf-8)以utf-8格式输出。
from bs4 import BeautifulSoupimport requestsif __name__ == '__main__':headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'}url = 'https://www.shicimingju.com/book/sanguoyanyi.html'page_text = requests.get(url=url,headers=headers).content.decode("utf-8")soup = BeautifulSoup(page_text,'lxml')li_list = soup.select('.book-mulu > ul > li')fp = open('./三国演义小说.txt','w',encoding='utf-8')for li in li_list:title = li.a.string
detail_url = 'https://www.shicimingju.com'+li.a['href']detail_page_text = requests.get(url=detail_url,headers=headers).content.decode("utf-8")detail_soup = BeautifulSoup(detail_page_text, 'lxml')div_tag = detail_soup.find('div',class_='chapter_content')content = div_tag.text
fp.write('\n' + title + ':' + content +'\n')print(title,'爬取成功')5.最终效果展现
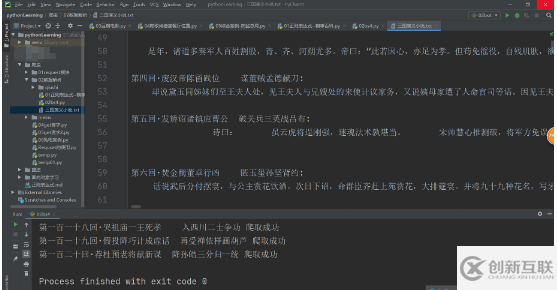
以上是“如何使用BeautifulSoup4数据解析实例”这篇文章的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注创新互联行业资讯频道!
当前文章:如何使用BeautifulSoup4数据解析实例
网站链接:https://www.cdcxhl.com/article28/jgoijp.html
成都网站建设公司_创新互联,为您提供网站营销、全网营销推广、自适应网站、网站收录、企业建站、移动网站建设
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 网站维护一定要注意的事情 2016-09-28
- 作为企业网站维护人员,应该注意哪些方面的操作? 2016-04-29
- 关于网站维护的日常任务 2016-10-29
- 怎样做好外贸英文网站制作 2014-04-09
- 网站的收录和虚拟主机有关系吗? 2016-10-22
- 网站维护是什么? 2016-11-08
- 网站优化:如何做好营销型网站维护与运营? 2023-01-23
- 网站制作者就是最好的网站维护者 2021-12-26
- 小程序搜索功能,真的很重要哦! 2016-09-01
- 关于阿里云虚拟主机与VPS服务器的解读 2014-02-19
- 需要虚拟主机的有哪些?购买虚拟主机要注意哪些要点? 2016-10-09
- 网站维护一年大概在多少钱? 2016-09-03