什么是扩散模型(DiffusionModel)?-创新互联
扩散模型是什么?如何工作以及他如何解决实际的问题

在计算机视觉中,生成模型是一类能够生成合成图像的模型(文本生成图像【DALL2、Stable Diffusion】、图像生成图像【Diffusion-GAN】)。例如,一个被训练来生成人脸的模型,每次都会生成一张从未被该模型或任何人看到过的人脸。
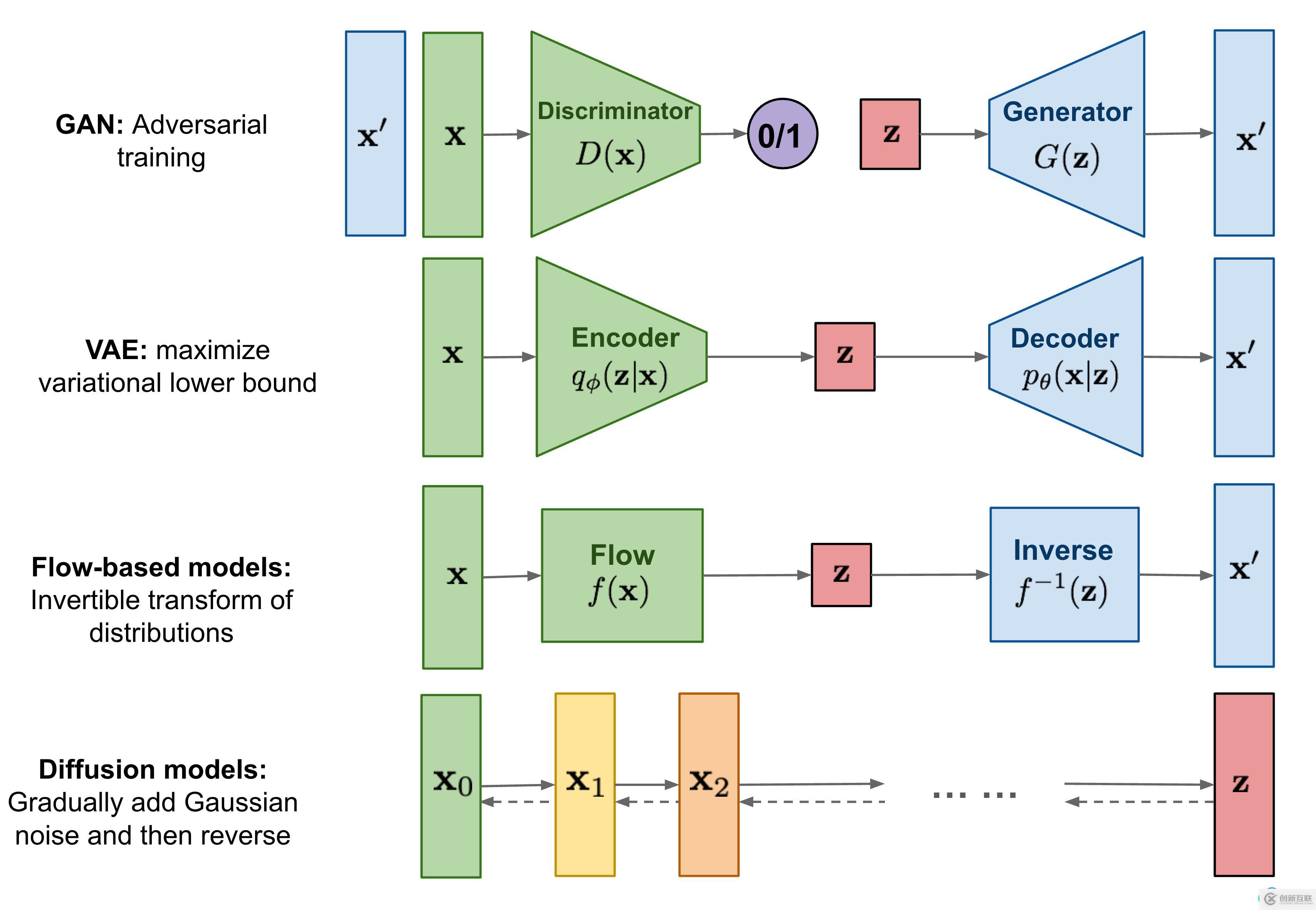
生成模型最著名的例子是GAN(生成对抗网络)。它有生成器和鉴别器,生成器G用来从随机噪声生成假的的图像,判别器(Discriminator)来判断输入是真实图像还是生成图像,两者在一个极小极大的相互博弈不断变强。由于模型本身具有对抗性,我们需要同时训练2个模型,所以很难进行训练。这使得很难达到一个最优的平衡。并且由于其训练稳定性差容易出现模式崩溃(Mode collapse)
2、变分自编码器(VAE)变分自编码器(Variational Autoencoder)通过编码器(Encoder)将原始高维输入转换为低维隐层编码,通过解码器(Decoder)从编码中重建数据。
为了可以随机生成图像,我们可以对编码器添加约束,就是强迫它产生服从高斯分布的潜在变量。然后我们只要从高斯分布中进行采样,然后把它传给解码器就可以产生随机图片了。
这种一般产生的图像比较模糊。
3、基于流的生成模型(Flow-based models)4、扩散模型(Diffusion Model)Diffusion Model (扩散模型) 是一类生成模型, 和 VAE (Variational Autoencoder, 变分自动编码器), GAN (Generative Adversarial Network, 生成对抗网络) 等生成网络不同的是, 扩散模型在前向阶段对图像逐步施加噪声, 直至图像被破坏变成完全的高斯噪声, 然后在逆向阶段学习从高斯噪声还原为原始图像的过程,大致分为3步:
1、前向具体来说, 前向阶段在原始图像 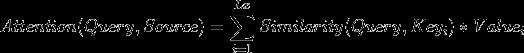 上逐步增加噪声, 每一步得到的图像 只和上一步的结果 相关, 直至第步的图像 变为纯高斯噪声. 前向阶段图示如下:
上逐步增加噪声, 每一步得到的图像 只和上一步的结果 相关, 直至第步的图像 变为纯高斯噪声. 前向阶段图示如下:

而逆向阶段则是不断去除噪声的过程, 首先给定高斯噪声, 通过逐步去噪, 直至最终将原图像 给恢复出来, 逆向阶段图示如下:

模型训练完成后, 只要给定高斯随机噪声, 就可以生成一张从未见过的图像.

1、前向过程:逐渐加噪声,找到X0与Xt-1、Xt-2.....Xt的关系
2、逆向过程:逐渐去噪声,找到Xt与Xt-1、Xt-2.....X0的关系
一、前向过程
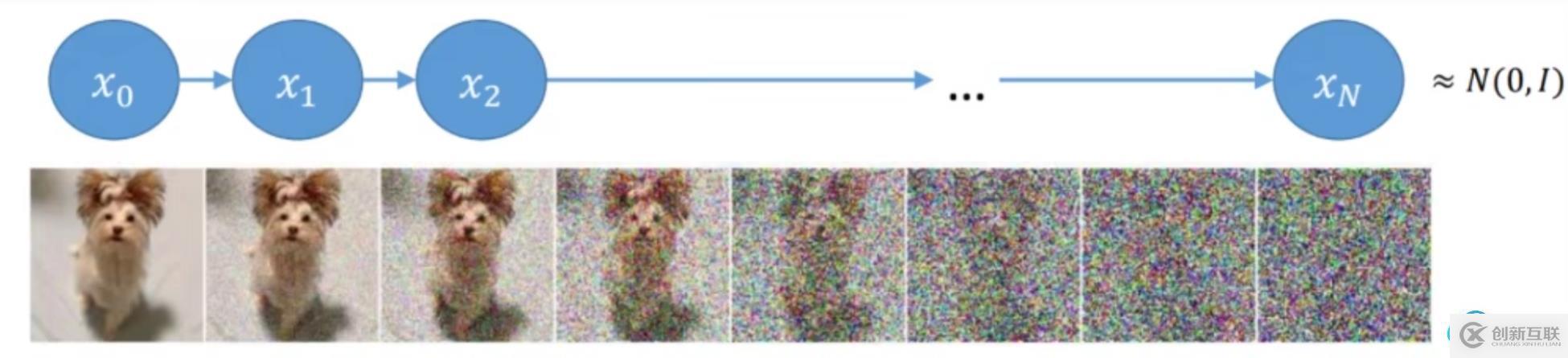
- 这里咱们先看前向过程,其实就是不断往输入数据中加噪声,最后就快变成了个纯噪声
- 每一个时刻都要添加高斯噪声,后—时刻都是由前一刻是增加噪声得到
- 其实这个过程可以看过咱们不断构建标签(噪声)的过程,后续会用到
Diffusion Model:比“GAN"还要牛逼的图像生成模型!公式推导+论文精读,迪哥打你从零详解扩散模型!_哔哩哔哩_bilibili
扩散模型 (Diffusion Model) 简要介绍与源码分析_珍妮的选择的博客-博客
你是否还在寻找稳定的海外服务器提供商?创新互联www.cdcxhl.cn海外机房具备T级流量清洗系统配攻击溯源,准确流量调度确保服务器高可用性,企业级服务器适合批量采购,新人活动首月15元起,快前往官网查看详情吧
网页题目:什么是扩散模型(DiffusionModel)?-创新互联
本文来源:https://www.cdcxhl.com/article28/dpisjp.html
成都网站建设公司_创新互联,为您提供面包屑导航、建站公司、手机网站建设、标签优化、做网站、网页设计公司
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 美国服务器托管怎么样?有什么要留意? 2022-10-04
- 艾克赛乐服务器托管怎么样? 2021-03-10
- 服务器托管太贵?可能这几方面你没选好 2022-10-07
- 四川服务器托管费用,四川托管一台服务器多少 2021-03-12
- 创新互联idc四川重庆服务器托管 2021-03-15
- 服务器托管收费标准 2021-03-20
- 服务器托管收费标准一般是多少? 2022-10-09
- 服务器托管带宽选择有什么依据? 2022-10-08
- 为什么企业进行服务器托管更好? 2022-10-03
- 企业要选服务器托管的原因是什么 2022-10-03
- 为何服务器托管成为企业的首选? 2022-10-05
- 服务器托管机房选择需要注意的几个问题 2022-10-09