Spark核心编程-创新互联
- Spark 核心编程
- 一、RDD
- 1、什么是 RDD
- 2、分布式计算模拟
- (1) 搭建基础的架子
- (2) 客户端向服务器发送计算任务
- 3、RDD 创建
- (1) 从集合(内存)中创建
- (2) 从外部存储(文件)创建RDD
- (3) 从其他RDD创建
- (4) 直接创建 RDD (new)
- 4、RDD 并行度与分区
- (1) makeRDD() 基于内存创建的RDD的分区
- (2) 基于文件创建的RDD 的分区
- (3) 数据分区的规则
Spark 计算框架为了能够进行高并发和高吞吐的数据处理,封装了三大数据结构,用于处理不同的应用场景。三大数据结构分别是:
1)RDD:弹性分布式数据集
2)累加器:分布式共享只写变量
3)广播变量:分布式共享只读变量
接下来让我们看看这三大数据结构是如何数据处理中使用的
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是 Spark 中最基本的数据处理模型。代码中是一个抽象类,它代表一个弹性的,不可变,可分区,里面的元素可并行计算的集合。
弹性:
存储的弹性:内存与磁盘的自动切换
容错的弹性:数据丢失可以自动恢复
计算的弹性:计算出错重试机制
分片的机制:可根据需要重新分片
分布式:数据存储在大数据集群不同的节点上
数据集:RDD 封装了计算逻辑,并不保存数据
数据抽象:RDD 是一个抽象类,需要子类具体实现
不可变:RDD 封装了计算逻辑,是不可以改变的,想要改变,只能产生新的RDD,在新的RDD里面封装逻辑计算
可分区,并行计算
首先分为两部分,我们把Excuter当成服务器,把Driver当成客户端。然后用客户端去连接服务器,然后客户端发送数据给服务器。
Excuter (服务器):
第一步设置服务器的端口号,ServerScket(9998)方法,里面的参数是端口号,这可以随便写。然后第二步等待客户端发送数据过来accept()方法。然后第三步使用getInputStream输入流接收客户端发送过来的数据,使用输入流的read()方法,这个就是从客户端拿到的数据,然后把这个数据给输出。最后把输出流,数据等待,还有服务器依次都给关闭。
package com.atguigu.bigdata.spark.core.wc.test2
import java.io.InputStream
import java.net.{ServerSocket, Socket}
//这个是做计算准备的,主要是逻辑代码部分
//这个相当于是服务器,然后Driver相当于是客户端,客户端连接服务器就可以直接使用了
class Excuter {}
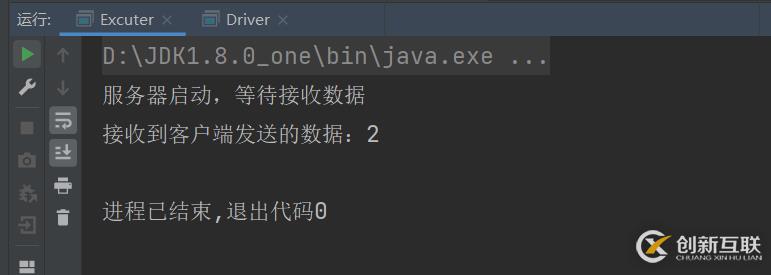
object Excuter{def main(args: Array[String]): Unit = {//启动服务器,接收数据 这个端口号是随便写的
val server = new ServerSocket(9998) //这个是网络编程的
println("服务器启动,等待接收数据")
//等待客户端的链接
val client: Socket = server.accept() //等待客户端发送过来的数据,accept()方法
val in: InputStream = client.getInputStream //输入流接收数据
val i = in.read() //这个就是拿到的值
println("接收到客户端发送的数据:" + i) //把客户端拿到的数据给输出
in.close() //把输入流给关闭掉
client.close()
server.close() //把服务器给关闭掉
}
}
Driver (客户端):
首先客户端连接服务器的端口号Socket("localhost",9998)方法,第一个参数是连接方式,这里是本地连接,第二个参数是服务器的端口号。然后第二步就向服务器发送数据,getOutputStream方法输出流,然后使用输出流的write()方法写出数据。然后使用输出流的flush()方法,flush方法的作用是,刷新此输出流并强制写出所有缓冲的输出字节。然后用完之后就把输出流和客户端给关闭了。
package com.atguigu.bigdata.spark.core.wc.test2
import java.io.OutputStream
import java.net.Socket
//这个是用来执行程序的
class Driver {}
object Driver{def main(args: Array[String]): Unit = {//连接服务器 本地连接,然后第二个参数是服务器定义的端口号
val client = new Socket("localhost",9998) //这个相当于是是客户端,连接服务器
val out: OutputStream = client.getOutputStream //向服务器发东西,用getOutputStream()
out.write(2)
out.flush()
out.close() //用完了吧这个输出流给关掉
client.close() //然后把这个客户端也关掉
}
}Excuter 类里面是服务器,Driver是客户端,Task 里面是准备数据和逻辑操作的,那个Driver 里面创建一个Task 对象然后把Task 用ObjectOutputstream输出流把对象给输出到Excuter接收,接收也是使用ObjectIntputstream对象输入流进行接收,因为输出的是一个操作逻辑,用字节流接收肯定不对,所有要用对象。然后Excuter 拿到Task之后,就可以直接使用里面的函数了。Task里面要混入Serializable特质,因为在网络中肯定是无法直接传送一个对象过去的,所以要进行序列化。 7
7
Excuter 代码:
package com.atguigu.bigdata.spark.core.wc.test2
import java.io.{InputStream, ObjectInputStream}
import java.net.{ServerSocket, Socket}
//这个是做计算准备的,主要是逻辑代码部分
//这个相当于是服务器,然后Driver相当于是客户端,客户端连接服务器就可以直接使用了
class Excuter {}
object Excuter{//要混入序列化的特征,不然不能那个传一个对象过去
def main(args: Array[String]): Unit = {//启动服务器,接收数据 这个端口号是随便写的
val server = new ServerSocket(9998) //这个是网络编程的
println("服务器启动,等待接收数据")
//等待客户端的链接
val client: Socket = server.accept() //等待客户端发送过来的数据,accept()方法
val in: InputStream = client.getInputStream //输入流接收数据
val objin: ObjectInputStream = new ObjectInputStream(in) //输出流失obj那么接收也应该是obj
val task: Task = objin.readObject().asInstanceOf[Task] //这个就是拿到的值 ,但是这里不应该是AnyRef,所以要进行转换
val ints = task.compute() //上面已经拿到了传过来的操作了,所以可以直接使用里面定义的函数了
println("计算节点的计算结果为:" + ints) //把客户端拿到的数据给输出
objin.close() //把输入流给关闭掉
client.close()
server.close() //把服务器给关闭掉
}
}Driver 代码:
package com.atguigu.bigdata.spark.core.wc.test2
import java.io.{ObjectOutputStream, OutputStream}
import java.net.Socket
//这个是用来执行程序的
class Driver {}
object Driver {def main(args: Array[String]): Unit = {//连接服务器 本地连接,然后第二个参数是服务器定义的端口号
val client = new Socket("localhost",9998) //这个相当于是是客户端,连接服务器
val out: OutputStream = client.getOutputStream //向服务器发东西,用getOutputStream()
val objout = new ObjectOutputStream(out) //定义这个Object的输出,因为上面那个是输出字节的不能传输对象
val task:Task = new Task() //然后创建一个task
objout.writeObject(task) //把task 传入给objout 对象输出流
objout.flush()
objout.close() //用完了吧这个输出流给关掉
client.close() //然后把这个客户端也关掉
println("客户端发送数据完毕")
}
}Task 代码:
package com.atguigu.bigdata.spark.core.wc.test2
class Task extends Serializable {//要混入序列化的特征,不然不能那个传一个对象过去
val datas = List(1,2,3,4) //这个是数据
val logic = (num:Int) =>{num * 2} //匿名函数 这个是逻辑
//计算
def compute() = {datas.map(logic) //莫logic 上面定义的逻辑操作传入进去
}
}在 Spark 中创建 RDD 的创建方式可以分为四种: 一般就是用前两种就行了,一般前两种用的比较多。
(1) 从集合(内存)中创建从集合中创建RDD,Spark主要提供了两个方法:parallelize和makeRDD
parallelize 是并行的意思,makeRDD 的底层则完全就是调用了parallelize方法,因为这个单词字面意思不大好理解,所以都用makeRDD就行了。
注意:local[*]里面加上*的意思是可以模拟多核多线程,要是不加的话那么就是模拟单线程,从内存中创建makeRDD()方法要传一个集合进去
package com.atguigu.bigdata.spark.core.wc.create_RDD
import org.apache.spark.api.java.JavaSparkContext.fromSparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
//在内存(集合)中创建RDD
class Spark01_RDD_Memory {}
object Spark01_RDD_Memory{def main(args: Array[String]): Unit = {//TODO 准备环境
//这个 local[*] 里面加上*的意思是,可以模拟多核多线程,不加的话就是模拟的单线程
val conf = new SparkConf().setMaster("local[*]").setAppName("create_RDD")
val context = new SparkContext(conf)
//TODO 创建RDD
//从内存中创建RDD,将内存中集合的数据作为处理的数据
val seq: Seq[Int] = Seq(1, 2, 3, 4)
//parallelize 并行
//val sc: RDD[Int] = context.parallelize(seq) //这里面传入的参数是一个集合,当做数据源,
val sc: RDD[Int] = context.makeRDD(seq) //makeRDD方法和parallelize方法是一样的
sc.collect().foreach(println) //只有触发collect方法,才会执行我们的应用程序
//TODO 关闭环境
context.stop()
}
}由外部存储系统的数据集创建RDD 包括:本地的文件系统,所有Hadoop支持的数据集,比如HDFS,HBase 等。
注意:这个文件的路径,可以是项目目录下,可以洗本地环境目录下,或者说hdfs 的路径下都是可以的。在文件中创建RDD,就要用textFile()方法将文件的路径给导入进去。或者读取数据的时候用wholeTextFiles()方法可以看到里面的数据来源,具体是来自于哪一份文件。textFile:以行为单位来读取数据,读取的数据都是字符串wholeTextFIles:以文件为单位读取数据,读取的结果表示为元组,第一个元素表示文件路径,第二个元素表示文件内容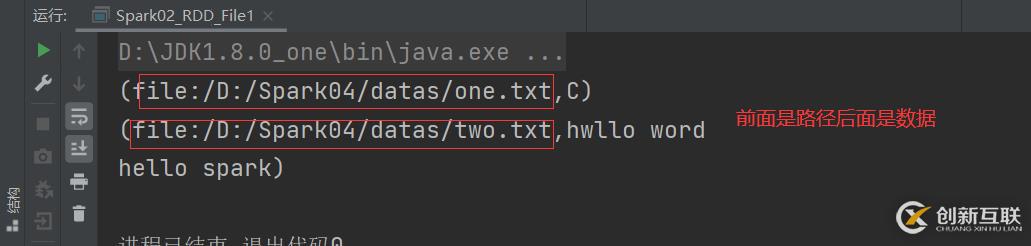
package com.atguigu.bigdata.spark.core.wc.create_RDD
import org.apache.spark.{SparkConf, SparkContext}
//从文件中创建RDD
class Spark02_RDD_File {}
object Spark02_RDD_File{def main(args: Array[String]): Unit = {//TODO 准备环境
val conf = new SparkConf().setMaster("local[*]").setAppName("create_RDD_File")
val context = new SparkContext(conf)
//TODO 创建RDD
//从文件中创建RDD,将文件中的数据作为处理的数据源
//path路径默认以当前环境的根路径为基准,可以写绝对路径,也可以写相对路径,
//还可以hdfs路径也是可以的,例如:hdfs://master:9080/test.txt
val file = context.textFile("datas/*")
file.collect().foreach(println)
//TODO 关闭环境
context.stop()
}
}主要是通过一个RDD运算完后,再产生新的RDD。
(4) 直接创建 RDD (new)使用new的方式直接构造 RDD,一般由 Spark 框架自身使用。
4、RDD 并行度与分区默认情况下,Spark 可以将一个作业切分多个任务后,发送给Executor 节点并行计算,而能够并行计算的任务数量我们称之为并行度。这个数量可以在构建RDD时指定。记住,这里的并行执行的任务数量,并不是指的切分任务的数量,不要混淆了。
(1) makeRDD() 基于内存创建的RDD的分区注意:makeRDD()方法,第二个参数是个隐式参数,是分区的数量,如果不传的话那么默认分区跟本地环境的核有关。比如我的电脑是4核,那么分区就是分为四个,并行计算。saveAsTextFile()方法 将处理的数据保存成分区文件,里面的参数是要创建的文件名。然后输出之后会自动生成一个这个名字的目录,下面的文件是分区文件。
package com.atguigu.bigdata.spark.core.wc.create_RDD
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
//RDD 并行度
class Spark01_RDD_Memory_Par {}
object Spark01_RDD_Memory_Par{def main(args: Array[String]): Unit = {//TODO 准备环境
//这个 local[*] 里面加上*的意思是,可以模拟多核多线程,不加的话就是模拟的单线程
val conf = new SparkConf().setMaster("local[*]").setAppName("create_RDD")
val context = new SparkContext(conf)
//TODO 创建RDD
//RDD的并行度 & 分区
//makeRDD 方法可以传入第二个参数,第二个参数是分区的数量
//第二个参数是可以不传的,因为是隐式参数,如果不传默认分区就是按照内核数量决定的,我的内核是4个,所以分区是4
val rdd:RDD[Int] = context.makeRDD(List(1, 2, 3,4,5),3) //里面的第一个参数是一个集合,第二个参数是分区的数量,分为几个区
//saveAsTextFile方法 将处理的数据保存成分区文件
rdd.saveAsTextFile("output")//saveAsTextFile方法
//TODO 关闭环境
context.stop()
}
}它分区分配数据的方式和Hadoop的分区的方式是一样的。和上面的基于内存的分配数据的方式不一样。
package com.atguigu.bigdata.spark.core.wc.create_RDD
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
class Spark02_RDD_File_Par {}
object Spark02_RDD_File_Par{def main(args: Array[String]): Unit = {//TODO 准备环境
val conf = new SparkConf().setMaster("local[*]").setAppName("create_RDD_File2")
val context = new SparkContext(conf)
//TODO 创建RDD
//textFile 可以将文件作为数据处理的数据源,默认也可以设定分区
// minPartitions:最小分区数量
//默认分区是两个,如果不想使用默认的分区数量那么,可以通过第二个参数指定分区数
val rdd: RDD[String] = context.textFile("datas/one.txt",3)
rdd.saveAsTextFile("output")
//TODO 关闭环境
context.stop()
}
}首先看字节,可以看到这个文件一共是14个字节,加上回车符
然后我们分两个区,14 / 2 = 7,一个区是7个字节,再用 14 / 7 = 2 可以看到刚好是2没有余数,所以没有问题刚刚好。首先是要计算行偏移量,计算出第一行的行偏移量是多少,计算出第二行是多少,然后计算行偏移量的范围就可以算出每个分区得到的数据是什么了。
查看结果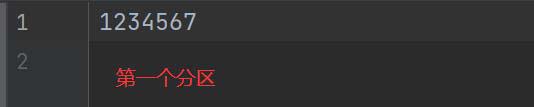
你是否还在寻找稳定的海外服务器提供商?创新互联www.cdcxhl.cn海外机房具备T级流量清洗系统配攻击溯源,准确流量调度确保服务器高可用性,企业级服务器适合批量采购,新人活动首月15元起,快前往官网查看详情吧
新闻名称:Spark核心编程-创新互联
文章链接:https://www.cdcxhl.com/article28/ccesjp.html
成都网站建设公司_创新互联,为您提供网站建设、App开发、定制开发、企业建站、建站公司、关键词优化
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 用户体验其实就这么简单! 2022-06-07
- 品牌网站设计的流程有哪些 2023-02-13
- 我要做的是品牌网站设计,实际上是品牌网页优化设计,可懂? 2022-05-23
- 品牌网站设计都需要一个“新闻工具包” 2023-03-02
- 如何做好网站设计?企业品牌网站设计重要指南 2022-08-16
- 品牌网站设计怎样做更加高端? 2022-11-15
- 金融网站建设竞争力,品牌网站设计新趋势 2014-06-08
- 深圳品牌网站设计公司 2014-05-13
- 深圳福田网站设计与制作,品牌网站设计制作的步骤是什么? 2021-11-20
- 深圳品牌网站设计:如何制作设计一个好的网站 2021-08-17
- 理解透公司品牌内涵后才能做好品牌网站设计制作 2022-04-05
- 优秀品牌网站设计欣赏 2014-06-25