C语言指针习题-创新互联
1. 小试牛刀💬推荐一款模拟面试、刷题神器,从基础到大厂面试题👉点击跳转刷题网站进行注册学习
成都创新互联是专业的民勤网站建设公司,民勤接单;提供成都做网站、网站设计,网页设计,网站设计,建网站,PHP网站建设等专业做网站服务;采用PHP框架,可快速的进行民勤网站开发网页制作和功能扩展;专业做搜索引擎喜爱的网站,专业的做网站团队,希望更多企业前来合作!


1.1 一维数组在讲解之前我们还是要回顾一下两个知识点:
1、sizeof(数组名)--数组名表示整个数组---计算的是整个数组的大小
2、&数组名---数组名表示整个数组,取出的是整个数组的地址
除此之外,所有的数组名都是数组首元素的地址

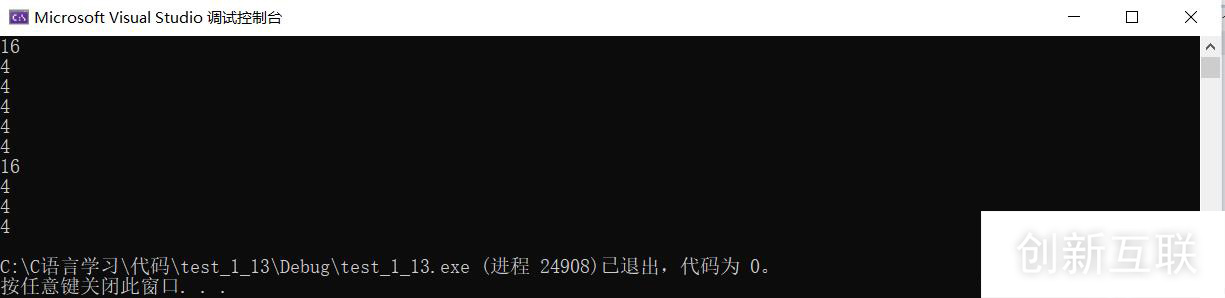
1、sizeof(a)操作的是整个数组;总共4个元素,每个元素都是int类型,占4个字节;所以最终结果是:4*4 = 16;
2、除了sizeof(a)和&a,代表操作的是整个数组,除此之外,所有的数组名都是数组首元素的地址:
sizof(a+0),a代表首元素的地址,a+0代表第一个元素的地址;最终sizeof(a+0)就是计算首元素地址的大小,是4或者8,对应着编译器是32 位和64位;
3、sizeof(*a),a代表的是首元素的地址,(*a)表示对首元素的地址进行解应用,访问的就是第一个元素1(是整型);sizeof(1)就是4;
4、sizeof(a+1),a代表的是首元素的地址,a+1代表的是第2个元素的地址;最终就是4或者8;
5、sizeof(a[1]),a[1]代表的是第2个元素2;sizoe(2)就是4。
6、sizeof(&a),&a代表的是整个数组的地址;但只要是地址,无论是什么类型,谁的地址,只要是地址,结果就是4或者8;
7、sizeof(*&a),*&a我们可以理解为先取地址,然后在解应用,抵消了;所以*&a就等价a;结果就是sizeof(a):16;
8、sizeof(&a+1),&a代表整个数组的二地址,&a+1代表跳过这个数组,下一个数组首元素的地址;是地址,结果就是4或者8;
9、sizeof(&a[0]),a[0]代表第一个元素,&a[0]代表一个元素的地址,是地址,结果就是4或者8;
10、sizeof(&a[0]+1),&a[0]是第一个元素的地址(也就是首元素的地址);&a[0]+1代表的就是第二个元素的地址,是地址,结果就是4或者8。
我用的是32位编译器,所以对于地址,就是4;如果用64位编译器,就是8了:
1.2.1 用sizeof和strlen计算由单个字符组成的数组对于字符数组计算长度,我们要先弄清楚下面几个概念:
(1)对于字符数组,我们常见的有2两种形式,一种是由单个字符组成的数组,另一种是由字符串组成的数组;
(2)这两种形式有一个本质的区别:单个字符组成的数组,默认没有\0;字符串组成的数组,默认有\0;
(3)并且对于求字符串长度,既可以用sizeof也可以用strlen,szieof计算长度会默认包括\0,strlen计算长度是找到\0就终止,不会包括\0;
(4)对于整型数组,我们一般用sizeof计算长度;对于字符串,我们一般用strlen计算长度
注意:sizeof后面既能跟地址,也能跟具体元素;strlen 后面只能跟地址!

1、用sizeof来计算由单个字符组成的数组
1、sizeof(arr),由单个字符组成的数组,默认没有\0;有6个元素,每个元素都char类型占1个字节,最终结果就是:6*1 = 6;
2、sizeof(arr+0),arr代表首元素的地址,arr+0表示第一个元素的地址;只要是地址无论是char类型还是int类型,结果都是4或者8;
3、sizeof(*arr),arr代表首元素的地址,*arr表示第一个元素‘a’;占1个字节,结果就是1;
4、sizeof(arr[1]),arr[1]代表第二个元素‘b’;占1个字节,结果就是1;
5、sizeof(&arr),&arr代表的整个数组的地址,只要是地址,结果就是4或者8;
6、sizeof(&arr+1),&arr代表的整个数组的地址,&arr+1表示跳过一个数组,下一个数组首元素的地址;只要是地址,结果就是4或者8;
7、sizeof(&arr[0]+1),&arr[0]代表第一个元素的地址,&arr[0]+1代表第二个元素的地址;只要是地址,结果就是4或者8;
8、sizeof(*&arr),&arr表示整个元素的地址,*&arr表示对整个数组解应用,得到的就是一整个数组;所以*&arr就等价于arr,sizeof(arr)结果就是6。
我用的是32位编译器,所以对于地址,就是4;如果用64位编译器,就是8了:

2、用strlen来计算由单个字符组成的数组
strlen找到\0才能停下来,不然就会一直往后找;strlen后面只能跟地址:strlen(地址)
1、strlen(arr),根据首元素的地址,一直往后找\0;因为由单个字符组成的字符串默认没有\0,所以结果就是随机值;
2、strlen(arr+0),arr是首元素的地址,arr+0就是第一个元素的地址,也就是首元素的地址;和第一个结果一样,是随机值;
3、strlen(*arr),arr代表首元素的地址,*arr代表取到第一个元素‘a’;strlen后面跟具体元素,是错误的写法error;
4、strlen(arr[1]),arr[1]代表取到第二个元素'b';strlen后面跟具体元素,是错误的写法error;
5、strlen(&arr),&arr表示整个数组的地址,其实也就等于首元素的地址;一直往后面找\0,是随机值;
6、strlen(&arr + 1),&arr代表首元素的地址,&arr+1代表跳过整个数组,下一个数组首元素的地址,从下一个数组首地址开始;最终结果也就是:随机值-6;
7、strlen(&arr[0] + 1),&arr[0]代表第一个元素的地址,&arr[0]+1代表第二个元素的地址;从第二个元素的地址开始;最终结果也就是:随机值-1。
把3、4屏蔽掉结果就是随机值19,随机值19,随机值19,随机值-6,随机值-1:


1、用sizeof来计算字符串组成的数组
1、sizeof(arr),由字符串组成的数组,默认有\0;总共有7个元素(6个元素+1个\0);每个元素都char类型占1个字节,最终结果就是:7*1 = 7;
2、sizeof(arr+0),arr代表首元素的地址,arr+0就是第一个元素的地址,也就是第一个元素的地址;只要是地址,结果就是4或者8;
3、sizeof(*arr),arr代表首元素的地址,*arr就是取出首元素'a';是char类型,占1个字节,最终结果就是:1
4、sizeof(arr[1]),ar[1]代表取出的是第二个元素‘b’;是char类型,占1个字节,最终结果就是:1
5、sizeof(&arr),&arr代表是整个数组的地址;只要是地址,结果就是4或者8;
6、sizeof(&arr+1),&arr代表是整个数组的地址;&arr+1表示跳过一个数组,下一个数组的首元素地址;只要是地址,结果就是4或者8;
7、sizeof(&arr[0]+1),&arr[0]代表第一个元素的地址;&arr[0]+1代表第二个元素的地址;只要是地址,结果就是4或者8;
我用的是32位编译器,所以对于地址,就是4;如果用64位编译器,就是8了:

2、用strlen来计算字符串组成的数组
1、strlen(arr),strlen是找\0,而字符串刚好默认里面有\0,但是不算\0的大小;总共有6个元素;每个元素都char类型占1个字节,最终结果就是:6*1 = 6;
2、strlen(arr+0),arr代表是首元素的地址,arr+0代表第一个元素的地址(也就是首元素的地址);所以和上面一样,最终结果就是:6*1 = 6;
3、strlen(*arr),arr代表首元素的地址,*arr表示取第一个元素;strlen后面不能跟具体元素,只能跟具体地址;所以是错误写法error;
4、strlen(arr[1]),arr[1]是取第二个元素,strlen后面跟具体元素,错误写法error;
5、strlen(&arr),&arr代表整个数组的地址,也就等于首元素的地址;总共有6个元素;每个元素都char类型占1个字节,最终结果就是:6*1 = 6;
6、strlen(&arr + 1),&arr代表整个数组的地址,*arr+1表示跳过这个数组,下一个数组的首地址;但是下一个地址几个元素?有没有\0?我们都不清楚;所以是随机值;
7、strlen(&arr[0] + 1),&arr[0]代表第一个元素的地址;&arr[0] + 1表示第二个元素的的地址,从第二个元素开始;所以最终结果就是6-1 = 5;
把3、4屏蔽掉结果就是6、6、6、随机值16、5



1、用sizeof计算由指针指向的常量字符串
1、sizeof(p),p是一个指针;指向的是首元素的地址,只要是地址,结果就是4或者8;
2、sizeof(p+1),p指针+1,指向的就是第二个元素的地址,只要是地址,结果就是4或者8;
3、sizeof(*p),p是一个指针;指向的是首元素的地址;*p表示取出第一个字符a,占1个字节,最终结果就是:1;
4、sizeof(p[0]),p[0]代表取出第一个字符a,占1个字节,最终结果就是:1;
5、sizeof(&p),p是一个指针,&p表示取出p的地址;指针p的地址也是一个地址;只要是地址,结果就是4或者8;
6、sizeof(&p + 1),&p表示取出p的地址,&p+1就是跳过一个p的地址,本质还是地址;只要是地址,结果就是4或者8;
7、sizeof(&p[0] + 1),&p[0]表示第一个元素a的地址,&p[0] + 1就是第二个元素b的地址;只要是地址,结果就是4或者8;
我用的是32位编译器,所以对于地址,就是4;如果用64位编译器,就是8了:

2、用strlen计算由指针指向的常量字符串
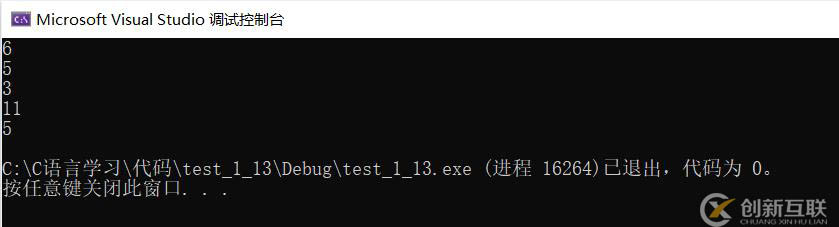
1、strlen(p),p指向的是首元素a的地址,strlen往后面找\0,最终结果就是:6;
2、strlen(p + 1),指针p+1表示从第二个元素地址开始,往后面找\0,最终结果就是:6-1 = 5;
3、strlen(*p),p指向的是首元素a的地址,*p解应用找到首元素a;strlen后面跟具体元素是错误写法error;
4、strlen(p[0]),p[0]代表是第一个元素a;strlen后面跟具体元素是错误写法error;
5、strlen(&p),&p表示取p的地址,p本身是地址占4个字节;但是我们并不知道p占用的这4个字节放的什么,本身有没有\0;所以最终是随机值;
6、strlen(&p + 1),&p表示取出p的地址,&p+1表示跳过一个p的内容;此时往后找\0,但是&p+1后面我们还是不知道内存的存储情况;所以还是随机值
7、strlen(&p[0] + 1),&p[0]第一个元素的地址,&p[0] + 1表示b的地址;从b开始往后数,结果就是:5;
把3、4屏蔽掉结果就是6、5、随机值3、随机值11、5
首先我们对二维数组要有一个简单的理解:
1、二维数数组的数组名也代表首元素的地址,但是首元素的地址实际上是第一行的地址;
2、二维数组可以看成几个一维数组组成,比如:arr[0]对于二维数组而言,可以理解为第一行元素的数组名;也就相当于一个一维数组的数组名!
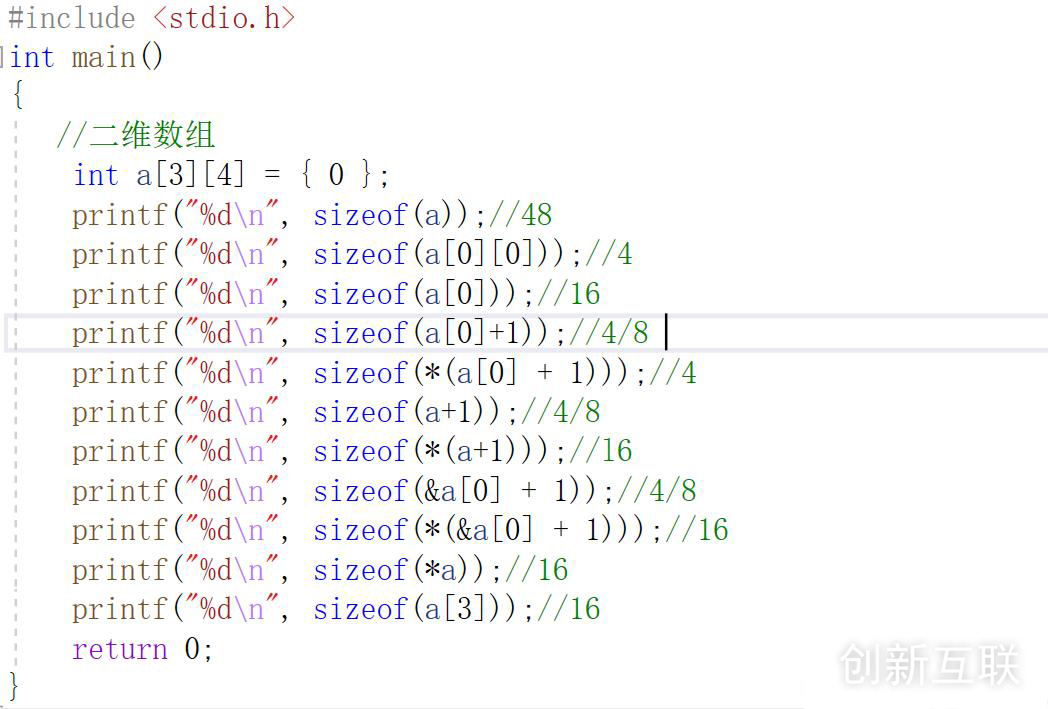
2. 指针笔试题 笔试题 1:1、sizeof(a),数组名单独放在sizeof里面,求的是整个数组的大小;总共3*4 = 12个元素,每个元素是整型占4个字节;最终大小就是:12*4 = 48;
2、sizeof(a[0][0]),a[0][0]表示的是二维数组的一个元素;最终求的是第一个元素的大小,是4;
3、sizeof(a[0]),a[0]可以理解为第一行元素的数组名,实际上也就相当于一个一维数组的数组名;数组名单独放到sizeof里面,求的是整个数组的大小;也就是4*4 = 16;
4、sizeof(a[0]+1),a[0]为第一行的数组名,并没有单独放到sizeof,表示的是首元素的地址;a[0]+1表示的是第一行第二个元素的地址;只要是地址,结果就是4或者8;
5、sizeof(*(a[0] + 1)),就是步骤4的解应用,拿到的第一行第二个元素,结果是4;
6、sizeof(a+1),数组名a没有单独放到sizeof里面,表示的是首元素的地址:实际上也就是第一行的地址;a+1就是二维数组第二行的地址;只要是地址,结果就是4或者8;
7、sizeof(*(a+1)),就是步骤6的解应用,拿到的是第二行的所有元素;也就是4*4 = 16;
8、sizeof(&a[0] + 1),a[0]是第一行的数组名,&a[0]取出的就是第一行的地址;&a[0]+1就是第二行的地址;只要是地址,结果就是4或者8;
9、sizeof(*(&a[0] + 1)),就是步骤8的解应用,拿到的是第二行的所有元素;也就是4*4 = 16;
10、sizeof(*a),数组名没有单独放到sizeof里面,代表的是第一行的地址;解应用拿到的是第一行的所有元素;也就是4*4 = 16;
11、sizeof(a[3]);看着好像是越界了;但是这里我们要明白一点:值属性和类型属性
比如3+5表达式:1.值属性是8 2.类型属性是int(4个字节)
并且sizeof()内部的表达式是不计算的,它并不会计算里面的值属性;只会计算类型属性!
解释:a[3]其实是第四行的数组名(如果有的话),但是其实不存在,也能通过类型计算大小的是16;这里如果计算下标为负值也是16,例如:sizeof(a[-1]) = 16

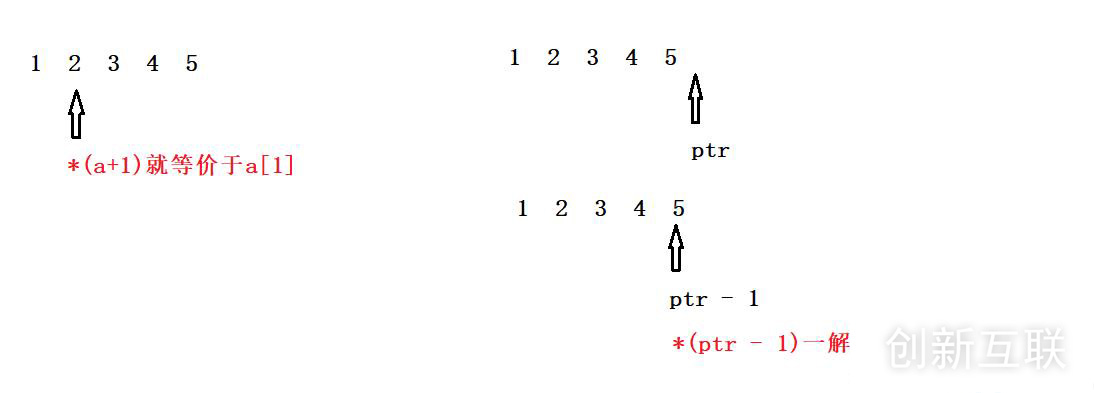
我们先理解一下题目,然后在画图进行分析:
(1)&a代表是整个数组的地址,&a+1表示跳过整个数组,下一个数组的首地址。
(2)所以*(a+1)就等价于a[1] = 2这个很简单;
(3)int* ptr = (int*)(&a + 1)表示指针ptr指向的是下一个数组的首元素地址,(ptr-1)表示指针后移一位指向5的地址,一解应用结果就是元素5。
逻辑图:
测试结果:


这里已经给出了结构体的大小,具体是怎么算的,等我们复习到会深度讲解的!
这里我们首先要明白一点:指针的类型决定了它的步长:
1、如果是整型指针int* p,那么p+1就是跳过4个字节;
2、如果是浮点型指针char* p,那么p+1就是跳过1个字节;
3、如果是结构体型指针struct Test* p,那么p+1就是跳过一个结构体的长度,这里就是跳过20个字节!
对于1:p+0x1,指针p+1跳过的是一个结构体类型所占的字节20,20转化为十六进制也就是14;所以最终的结果就是:p的地址+0x14;
对于2:把p强制类型转换为长整型int,+1就是加1;就相当于一个整型数据4,+1就是5;整型+整型;所以最终的结果就是:p的地址+0x1;
对于3:把p强制类型转换为整型指针int*,指针p+1跳过的就是4个字节;所以最终的结果就是:p的地址+0x4;
测试结果:


这道题就是专门区分:指针+1 和 整型+1的区别!对于指针+1,根据指针的类型来决定跳过几个字节。对于整型+1,+1就是跳过一个字节!
第一个问题:&a+1表示跳过一整个数组的下个数组的首元素地址,并把这个地址赋值给ptr1;ptr[-1]就等价于*(ptr-1);下面通过画图分析一下:
逻辑图:

第二个问题:数组a是首元素的地址,强制类型转换为一个整型,整型+1就是+1,跳过一个字节;而一个整型是占4个字节,所以我们就需要更细致的画图方式:

测试结果:

这道题目,我们乍一看觉得很简单结果是0,却忽略了逗号表达式;实际上数组里存储的是{1,3,5};所以最终p[0]的值就为1。
测试结果:


这道题就有意思了,没有赋值任何元素;还是先画图分析一下:
逻辑图:
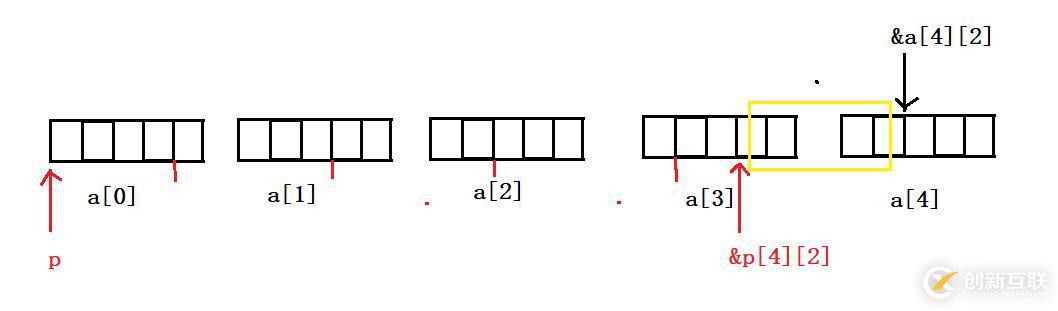
我们已经学过,指针-指针实际上中间元素的个数,从图中就可以看出相差4个元素;又因为是小地址-大地址,所以&p[4][2] - &a[4][2]以%d的形式打印出来就是-4;对于-4我们以%p打印它的地址,又是怎么的呢?

测试结果:


我们还是先简单分析一下,在画图。
1、对于&aa+1表示跳过一整个二维数组的下个数组的首元素地址
2、*(aa+1)等价于aa[1]相当于第二行的数组名
逻辑图:
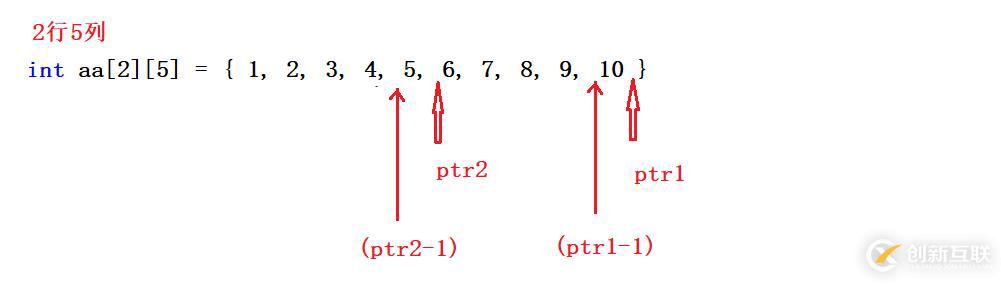
测试结果:


逻辑图:
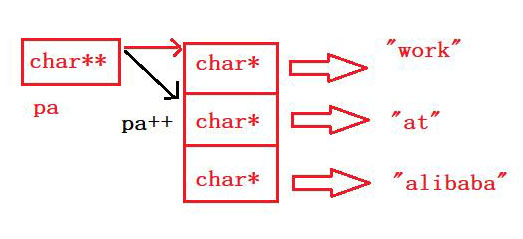
这道题只要我们分析清楚了,就很简单; char* a[]是一个指针数组,数组的每个元素都是char*;数组名a代表首元素的地址,也就是char*的地址,需要一个二级指针pa来接收;pa++指针+1就改变了它的方向;最终我们*pa解应用得到的就是存储的数据at的首元素地址,最终打印出来是at。
测试结果:


逻辑图:
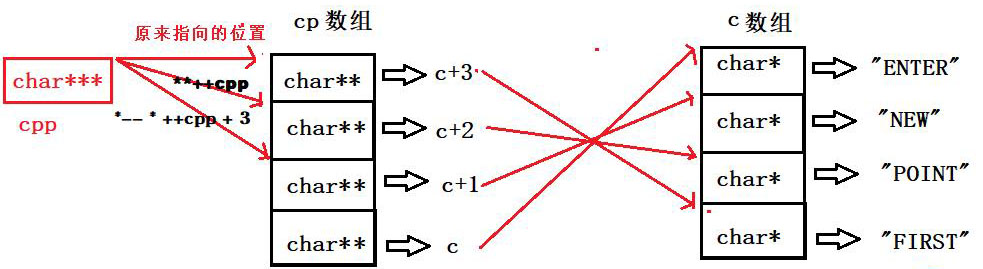
这道题首先我们要先把图画对,然后才能把题作对;数组c和数组cpp都是数组指针,我们根据映射关系,先把图画出来。
1、**++cpp:++cpp指针指向下一个位置,我们第一次解应用*++cpp,我们找到c+2;第二次解应用**++cpp,我们找到''POINT"的首元素地址;然后%s打印,最终就是POINT;
2、 *-- * ++cpp + 3:这里我们要先弄清楚优先级,(解应用*)和(自增++)、(自减--)优先级都是比(加+)高的;++cpp指针在原来的基础上,在指向下一个位置;第一解应用*++cpp,我们找到c+1;然后--解应用*找到的是"ENTER"首元素地址;最后+3,指针后移3位到E的地址,然后%s打印,最终就是ER;
3、 *cpp[-2] + 3:cpp[-2]等价于*(cpp-2),所以就是**(cpp-2)+3;第一次解应用*(cpp-2)找到的是c+3;第二次解应用**(cpp-2)找到的是"FIRST"的首元素地址;最后+3,指针后移3位到S的地址,然后%s打印,最终就是ST;
4、cpp[-1][-1] + 1:cpp[-1][-1]等价于*(*(cpp-1)-1),第一次解应用*(cpp-1)找到的是c+2;第二次解应用*(*(cpp-1)-1)找到的是"NEW"的首元素的65地址;最后+1,指针后移1位到E的地址,然后%s打印,最终就是EW;
测试结果:
方法1:遍历整个二维数组所谓杨氏矩阵:就是有一个数字矩阵,矩阵的每行从左到右是递增的,矩阵从上到下是递增的。我们需要在这个矩阵中查找某个元素是否存在,怎么办呢?当然很简单的方法是遍历整个二维数组,很容易就能实现;但是如果限制时间复杂度小于O(N)呢?
1 2 3
4 5 6
7 8 9我们就假如在这个杨氏矩阵中查找数字7:
这种方法很好想,遍历整个二维数组,时间复杂度为O(
);但是并没有利用上杨氏矩阵的特点;效率很低
具体代码:

逻辑测试:

我们就利用杨氏矩阵的特点:矩阵的每行从左到右是递增的,矩阵从上到下是递增的;所以我们就从第一行的最后一个元素开始找:如果小了就x++,如果大了就y--!

具体代码:

逻辑测试:

问题来了find_num函数我们只负责让它找,而不让它在函数内部打印怎么办呢?直接return坐标?显然是不可行的,return只能有一个返回值,不能一次返回两个值!所以我们不妨创建两个变量;利用值传递的方式把最终坐标带回来!
具体代码:

逻辑测试:

方法1:常规法所谓旋转字符串就是:实现一个函数,可以左旋转字符串中的k个字符;例如:ABCD左旋转一个字符BCDA;ABCD左旋转两个字符CDAB。这很类似于我们以前讲过的旋转数组,感兴趣的小伙伴可以去看一下:《旋转数组》
我们就先旋转一次看具体是怎样得操作,一次旋转成功了,想要旋转多次,直接在外面加一层循环就可以啦!
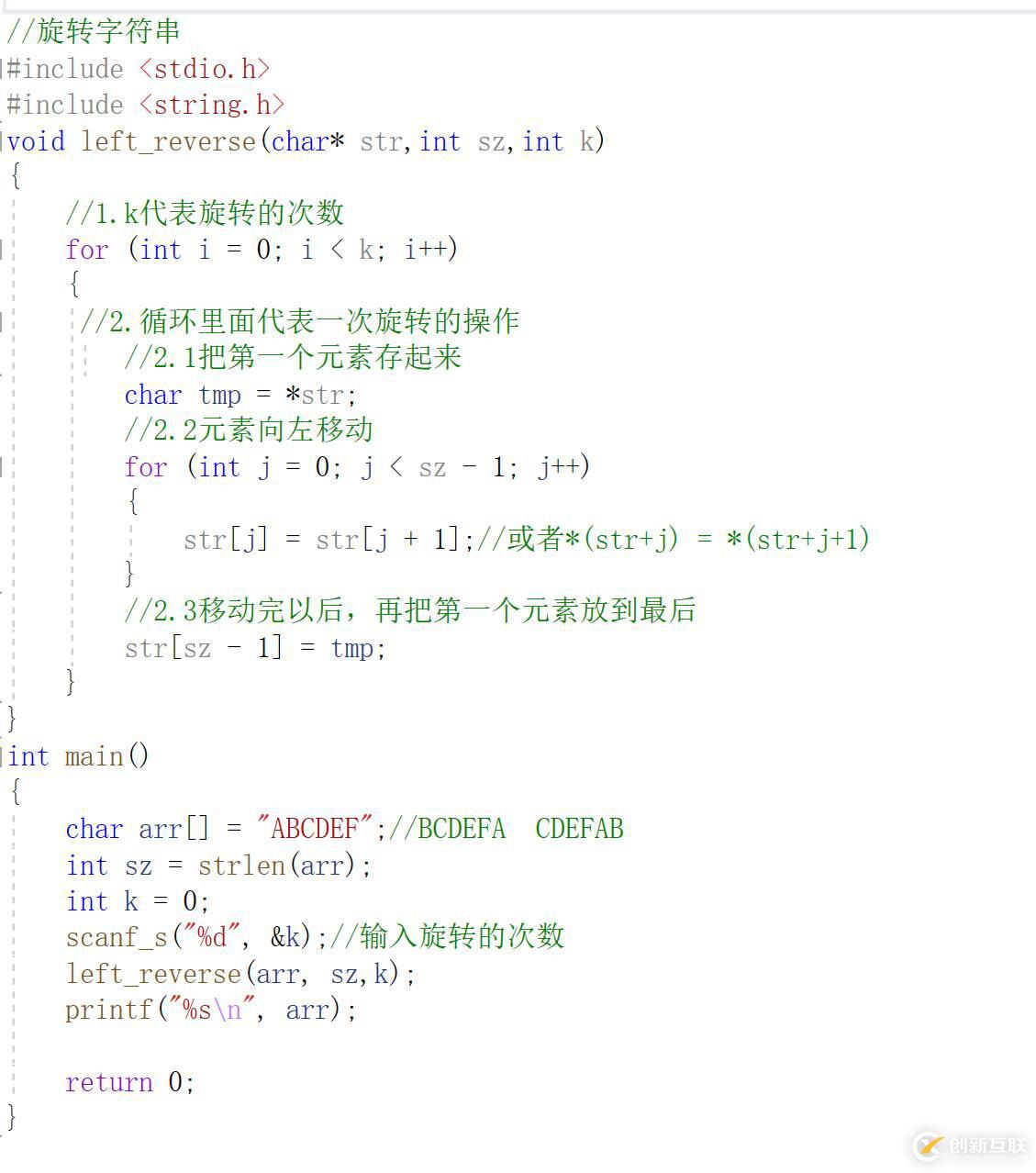
所谓三步三步翻转法就是:翻转字符串三次,每次在那个位置翻转?下面我们通过一个例子的形式来解读一下:

至于代码我们可以写成两种形式,觉得哪一种好理解就用哪一种:
第一种形式:

第二种形式:


补充例题3:字符串旋转结果对于右旋和左旋代码几乎是一样的;大的区别就是三步旋转的函数里传的参数不同;我们只要理解其中的原理:无论是左旋转还是右旋转都是小case了!
方法1:暴力求解这道例题实际是例题2的延伸:写一个函数,判断一个字符串是否为另外一个字符串旋转之后的字符串,例如:给定s1=AABCD和s2=BCDAA,返回1,给定s1=abcd和s2=ABCD,返回0
我们就按照例题2的思路去求解;就让他旋转n次,每旋转一次我们就对比一下字符串是否相等!

在利用这种方法之前,我们先要先了解一下strncat和strstr:
1、strcat是字符串追加函数:
strcat是长度不受限制的追加,但是不能自己追加自己;使用格式为strcat(数组1,数组2)
strncat是长度受限制的追加,可以自己追加自己;使用格式为strncat(数组1,数组2,n)
2、strstr是判断是不是子串的函数:
对于一个字符串是不是另一个字符串的子串;找到返回一个地址,找不到它会返回一个空指针NULL;所以要用一个指针接收

这段代码我只说两点:
1、我们既然需要利用strncat把str1进行追加,例如:AABCD追加成 AABCDAABCD,所以arr1数组肯定要给足够的大小,我们是给的20!2、利用strstr判断一个字符串是不是另一个字符串的子串,我们会发现它的子串有很多;比如: AABCDAABCD,AA是它的子串,BCD等也是它的子串;但实际上我们要的是AABCD,是它追加之前的字符串长度;所以我们要加一个限制条件,先判断两个字符串长度是否相等!
结束语
今天的分享就到这里啦!快快通过下方链接注册加入刷题大军吧!各种大厂面试真题在等你哦!
💬刷题神器,从基础到大厂面试题👉点击跳转刷题网站
你是否还在寻找稳定的海外服务器提供商?创新互联www.cdcxhl.cn海外机房具备T级流量清洗系统配攻击溯源,准确流量调度确保服务器高可用性,企业级服务器适合批量采购,新人活动首月15元起,快前往官网查看详情吧
本文题目:C语言指针习题-创新互联
标题路径:https://www.cdcxhl.com/article26/hpcjg.html
成都网站建设公司_创新互联,为您提供网站营销、全网营销推广、营销型网站建设、品牌网站制作、做网站、网站策划
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 如果移动网站建设没有注意这七点后果会是? 2022-05-27
- 浅析移动网站建设的发展趋势 2023-03-27
- 如何提高移动网站建设应用程序的保留率? 2022-08-24
- 看完这7点,写出有销售力的电商文案 2022-06-10
- 移动网站建设中有哪些设计重点 2023-01-29
- 移动网站建设有哪些要点? 2021-11-29
- 深圳移动网站建设需要注意的问题 2022-05-03
- 移动网站建设需要注意的问题 2022-12-17
- 移动网站建设不可忽视的两个功能 2021-07-25
- 移动网站建设的四个设计基本要求 2017-01-25
- 移动网站建设时要注意视觉的设计及优化 2016-10-05
- 移动网站建设排版应注意哪些问题? 2016-11-07