mongodb安全和优化-创新互联
提高mongodb的安全性:

MongoDB默认没有密码,且只允许本地访问。如果开放外网访问,就一定要设置密码,而且要配置好防火墙,指定只允许哪些ip访问mongodb端口,否则会有安全隐患。
配置权限管理机制:
RBAC机制涉及三个关键定义:角色(Roles)、特权(Privileges)和用户(Users) 。
• 特权是指一些资源和能够在资源上进行的操作。
• 一个角色可以有多种特权。
• 一个用户可以有被赋予不同的角色。
1.创建管理员用户:
在Linux或者macOS中,执行命令“mongo”打开MongoDB 命令行客户端:
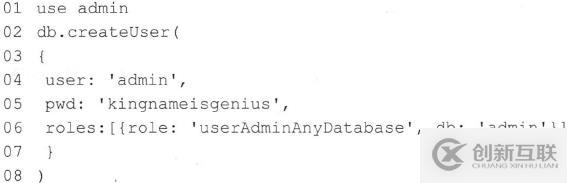
• 第1行代码:切换到admin数据库。admin数据库是MongoDB自带的数据库。
• 第3~9行代码:创建管理员,账号名称为admin,密码为kingnameisgenius ,角色为userAdminAnyDatabase , 控制的数据库为admin
创建好管理员账户以后,在MongoDB命令行客户端中直接输入“ exit ”后按回车键,即可退出MongoDB 命令行客户端。
修改创建的配置文件mongodb.conf,添加如下两行内容:
security :
authorization : enabled
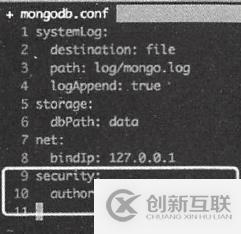
保存配置文件并重启MongoDB数据库。再次执行“mongo”命令,发现虽然能够连上数据库,但是已经不能执行常规操作了

要正常使用命令行客户端,必需把mongo 的启动命令修改为:
mongo -u 'admin' -p 'kingnameisgenius' --authenticationDatabase 'admin'
2.创建普通用户:
管理员账户是没有权限操作普通数据库的。要操作普通数据库,还需要创建普通用户。
使用管理员账户登录命令行客户端后,执行以下命令创建一个对chapter_8数据库有读写权限,对chapter_4只有读权限的普通用户。

3.创建能操作数据库的管理员用户:
管理员(admin账号)能创建其他用户, 看似权限非常大,但它不能访问任何一个数据库。所以,如果有必要,还需要创建一个能对所有数据库都有全部权限的用户。
(1).在MongoDB 的命令行客户端中,使用管理员C admin )连接MongoDB,然后执行以下命令创建一个对所有数据库有完全控制权限的用户。


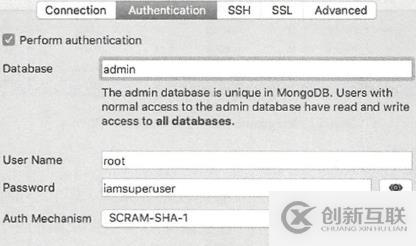
(2).在可视化连接程序中使用root用户连接数据库,并把数据库设定为admin:
批量插入与逐条插入的性能对比:
一条插入语句可能好事几毫秒,但这过程中网络传输的时间占了很大比例。IO(输入/输出)操作总是最耗费时间的,无论是硬盘IO还是网络IO。现在的宽带技术,上下行速度动辄每秒几百兆字节。如果使用MangoDB插入数据还在逐条插入,每一条几个字节,那可真是白白浪费了网络带宽。
• 如果写到本地的MongoDB ,数据会在网卡中转一圈再存入硬盘。
• 如果写到远程的MongoDB ,数据会先从本地网卡出去,然后经过网线,在电磁波、光信号、电信号之间进行转换,中间通过一层一层的交换机路由器,甚至海底光缆,绕地球一圈再进入目标服务器的网卡最后存入数据库。
当然,批量插入要考虑多方面:
1.(从redis等中)要插入的数据量非常大,全部丢到内存里超出了内存空间咋办?
2.(redis中的)数据暂停添加,要过好长一阵才会继续添加咋办?
3.假设redis中有1亿数据,读到第99999999条数据时,突然断电咋办?
......
如果Redis中的数据是持续性数据,则会有新数据源源不断被加入到Redis中,每次添加之间的时间间隔从几毫秒到几小时不等。代码可以如下(python):
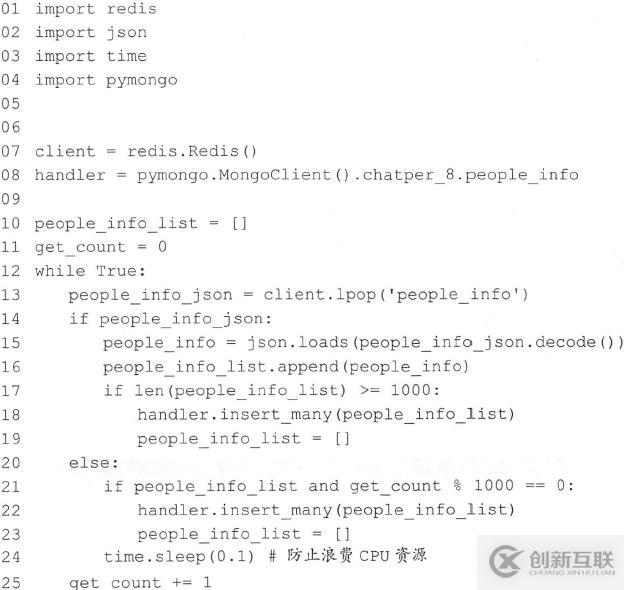
• 第11行代码:增加了一个计数变量,通过第25行代码实现每获取一次Redis中的数据就让变量加1。
•
第21行代码:在Redis为空的情况下,如果people_info_list中有数据,不论有多少数据,只要请求Redis的次数为1000的倍数,那么就批量插入数据库。这样做的好处是,保证people_info_list中的数据最多等待100秒就会被插入数据库。这里使用了“%”实现取余操作,“
get_count % 100。”的结果为get_count除以1000的余数。如果结果为0则表示get_count 正好是1000
的整数倍。
• 第24行代码: 在本次发现Redis为空的情况下,暂停0.1秒,这样做可以显著降低CPU的占用。
插入与更新的性能对比:
(注意:salary字段是字符串,不是整型)
逐条更新代码如下(python):


• 第7行代码:读取所有数据,并只输出“_id ”字段(默认输出〕和“ salary ”字段。
• 第8行代码: 把“ salary ” 字段转换为整型数据。
• 第10行代码: 根据“_id ”宇段把新的“ salary ”字段更新到数据库中。
逐条更新19808条数据耗时68.7 秒,比逐条插入数据的时间还长!!!
用插入数据代替更新数据:
对于必需逐条更新大量数据的情况,也可以使用插入代替更新来提高性能。
基本逻辑是: 把数据插入到另一个集合中, 然后删除原来的集合,再把新集合改名为原来的集合。

• 第6~8行代码: 初始化两个连接,分别指向batch集合和update by _insert集合。
• 第14行代码: 把更新以后的数据添加到新的列表中。
• 第15行: 把新的列表批量插入数据库。
更新119808条数据并插入新的集合中,耗时3秒。
更新完成以后,删除原来的batch集合,再把新的集合update _by_insert改名为“ batch ”,就变相完成了数据的批量更新。
使用索引提高查询速度:
在一个集合的数据量到达千万量级以后,查询速度会变得非常缓慢, 这时就需要使用索引来加快查询速度。
索引是一种特殊的数据结构,它使用了能够快速遍历的形式记录了集合中数据的位置。
如果不使用索引,则每一次查询数据MongoDB都会遍历整个集合;而如果使用了索引,则MongoDB会直接根据索引快速找到需要的内容。
1. 索引的创建
mongodb采用ensureIndex来创建索引,如:
db.user.ensureIndex({"name":1})
表示在user集合的name键创建一个索引,这里的1表示索引创建的方向,可以取值为1和-1
在这里面,我们没有给索引取名字,mongodb会为我们取一个默认的名字,规则为keyname1_dir1_keyname2_dir2...keynameN_dirN
keyname表示键名,dir表示索引的方向,例如,上面的例子我们创建的索引名字就是name_1
索引还可以创建在多个键上,也就是联合索引,如:
> db.user.ensureIndex({"name":1,"age":1})
这样就创建了name和age的联合索引
除了让mongodb默认索引的名字外,我们还可以去一个方便记的名字,方法就是为ensureIndex指定name的值,如:
> db.user.ensureIndex({"name":1},{"name":"IX_name"})
这样,我们创建的索引的名字就叫IX_name了
2. 唯一索引
与RDB类似,我们也可以定义唯一索引,方法就是指定unique键位true:
>db.user.ensureIndex({"name":1},{"unique":true})
3.查看我们建立的索引
索引的信息存在每个数据库的system.indexes集合里面,对这个集合只能有ensureIndex和dropIndexes进行修改,不能手动插入或修改集合。
通过> db.system.indexes.find()可以找到数据库中多有的索引:
> db.system.indexes.find()
{ "v" : 1, "key" : { "_id" : 1 }, "ns" : "test.entities", "name" : "_id_" }
{ "v" : 1, "key" : { "_id" : 1 }, "ns" : "test.blog", "name" : "_id_" }
{ "v" : 1, "key" : { "_id" : 1 }, "ns" : "test.authors", "name" : "_id_" }
{ "v" : 1, "key" : { "_id" : 1 }, "ns" : "test.papers", "name" : "_id_" }
{ "v" : 1, "key" : { "_id" : 1 }, "ns" : "test.analytics", "name" : "_id_" }
{ "v" : 1, "key" : { "_id" : 1 }, "ns" : "test.user", "name" : "_id_" }
{ "v" : 1, "key" : { "_id" : 1 }, "ns" : "test.food", "name" : "_id_" }
{ "v" : 1, "key" : { "_id" : 1 }, "ns" : "test.user.info", "name" : "_id_" }
{ "v" : 1, "key" : { "_id" : 1 }, "ns" : "test.userinfo", "name" : "_id_" }
{ "v" : 1, "key" : { "name" : 1 }, "ns" : "test.user", "name" : "IX_name" }
4.删除索引
如果索引没有用了,可以使用dropIndexes将其删掉:
> db.runCommand({"dropIndexes":"user","index":"IX_name"})
{ "nIndexesWas" : 2, "ok" : 1 }
ok表示删除成功
引人Redis ,以降低MongoDB的读取频率:
使用Redis ,以降低MongoDB的查询频率, 从而提高新闻爬虫的爬取效率。
( 1 )读取MongoDB 的数据并存入Redis 集合中。
( 2 )使用Redis 集合的“sadd”命令,在判断数据是否存在的同时添加新的数据。
假设, 需要实现一个新闻网站的爬虫, 让它会去各个新闻网站爬取新闻, 然后存入MongoDB中。为了不存入重复的新闻,爬虫需要根据新闻标题来判断新闻是否已经在数据库中了。
如果每一条新闻标题去查询MongoDB 看是否己经重复, 这显然会严重影响性能。为了防止频繁读MongoDB ,则可以引入Redis 以降低MongoDB 的读取频率。
假设新闻保存在chapter_8 库中的news 集合中。一开始news 集合里面已经有不少新闻了。
当爬虫启动时,先读取一次news中的全部新闻标题,并把它们放在Redis中名为news title的集合中。接下来,就不需要读取MongoDB了。
爬虫每爬取到一条新的新闻,就先使用“ sadd ”命令将其添加到Redis的集合中:
• 如果返回1,则表示以前没有这条新闻,将其插入到MongoDB中。
• 如果返回0,则表示以前已经有这条新闻了,直接丢弃。

• 第2行代码:获取所有新闻标题。
• 第3行代码:把新闻标题全部添加到Redis中名为news_title的集合中。
• 第7行代码:添加并判断新闻标题是否己经在newstitle集合中。如果己经存在,则返回0;如果不存在,则返回1,并将其添加进入Redis集合中。
适当增加冗余信息,提高查询速度:
还是以one_by_one中的数据为例。假设定义一个身份"特殊人员"条件是: age小于10, salary大于10000
如果在插入数据库时就添加一个字段“special_person”,满足条件就是True,不满足条件就是False 。那查询时就简单了,直接查询所有special_person字段为True 的数据即可
另外有需要云服务器可以了解下创新互联scvps.cn,海内外云服务器15元起步,三天无理由+7*72小时售后在线,公司持有idc许可证,提供“云服务器、裸金属服务器、高防服务器、香港服务器、美国服务器、虚拟主机、免备案服务器”等云主机租用服务以及企业上云的综合解决方案,具有“安全稳定、简单易用、服务可用性高、性价比高”等特点与优势,专为企业上云打造定制,能够满足用户丰富、多元化的应用场景需求。
网页名称:mongodb安全和优化-创新互联
文章起源:https://www.cdcxhl.com/article26/gphcg.html
成都网站建设公司_创新互联,为您提供网站制作、面包屑导航、自适应网站、动态网站、响应式网站、全网营销推广
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 4个消费电子产品的品牌网站设计 2021-09-28
- 金融网站建设竞争力,品牌网站设计新趋势 2014-06-08
- 品牌网站设计的流程有哪些 2023-02-13
- 品牌网站设计如何在同行业中脱颖而出? 2016-01-18
- 品牌网站设计对企业来说有什么意义 2021-10-27
- 好的品牌网站设计两大要点必知 2022-06-10
- 吴江高端网站建设制作品牌网站设计如何布局 2020-11-23
- 深圳品牌网站设计公司 2014-05-13
- 成都企业品牌网站设计的常见布局方式 2023-03-25
- 品牌网站设计怎样做更加高端? 2022-11-15
- 网站制作专业公司更相符公司的成长请求 2022-06-04
- 理解透公司品牌内涵后才能做好品牌网站设计制作 2022-04-05