spark分布式集群安装-创新互联
第一步:版本的选择:

spark-0.x spark-1.x(主流:Spark-1.3 和 Spark-1.6) spark-2.x(最新 Spark-2.4) 下载地址:http://spark.apache.org/downloads.html(官网) 其他镜像网站:https://mirrors.tuna.tsinghua.edu.cn/apache/spark/ https://www.apache.org/dyn/closer.lua/spark/spark-2.3.0/ https://www.apache.org/dyn/closer.lua/spark/ 注意这里我选择是:spark-2.3.0-bin-hadoop2.7.tgz。 |
第二步:关于搭建spark集群的环境:
spark底层是使用scala语言编写的,所有这里需要安装scala的环境,并且配置scala的环境变量。
scala和spark也都需要jdk,所以我们还需要配置jdk的环境以及环境变量,关于jdk的版本最好是java 8+。
这里我们用spark-2.3
注意:由于安装比较简单,此时略过java以及scala的安装。
转载:https://www.cnblogs.com/liugh/p/6623530.html(Linux下安装java)
转载:https://www.cnblogs.com/freeweb/p/5623795.html(Linux下安装scala)
第三步:spark集群的规划:
Server | Master | Worker |
hostname01 | √ | |
hostname02 | √ | |
hostname03 | √ |
第四步:具体的集群安装:
| ①上传下载好的spark安装包到集群的任意一个节点(由于个人品味不一,这里上传软件的方式也不同,作者使用的是Xshell) ②解压,并放置到统一管理的目录下(注意这个目录一定要有读写的权限):tar zxvf spark-2.3.2-bin-hadoop2.7.tgz -C /application/ ③进入相应的spark的conf目录:cd $SPARK_HOME/conf: [user01@hostname01 ~]$ mv spark-env.sh.template spark-env.sh [user01@hostname01 conf]$ vim spark-env.sh(加入以下配置) export JAVA_HOME=/application/jdk1.8.0_73 export SPARK_MASTER_HOST=hostname01 export SPARK_MASTER_PORT=7077 ④修改$SPARK_HOME/conf/slaves(在其中加入集群的从节点的主机或者IP,这里我将hostname02、hostname03当做从节点) hostname02 hostname03 注意:这里的配置,不要用任何多余的空格和空行!!! ⑤将spark安装包copy到集群的其他节点上 scp -r /application/spark-2.3.2-bin-hadoop2.7 hostname02: /application scp -r /application/spark-2.3.2-bin-hadoop2.7 hostname03: /application 注意:由于这里集群的节点不是很多,所以在分发安装包的时候,可以手动输入密码,个人建议还是配置一下ssh面秘钥登录。 转载:https://blog.csdn.net/furzoom/article/details/79139570 ⑥配置spark的环境变量:(注意这里需要所有的集群节点都要配置,当然配置的地方,根据不同要求而定) 我这里配置在/etc/profile : (由于提前做了sudo的权限设置,所以在普通用户下依然可以修改/etc/profile) export SPARK_HOME=/application/spark-2.3.2-bin-hadoop2.7 PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin #注意这里的bin和sbin都要配置 ⑦最终启动集群: [user01@hostname01 ~]$ /application/spark-2.3.2-bin-hadoop2.7/sbin/start-all.sh 切记:如果集群有hadoop集群,那么在hadoop的sbin目录下也有start-all.sh的命令,所以这里只能使用全路径 |
第五步:测试是否启动成功
第一种方法:
使用jps命令查看进程:master是集群的主节点,worker是集群的从节点:



第二种方法:查看web UI界面:
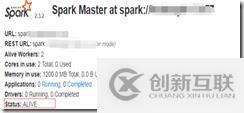
最终出现上述情况任意一个,说明集群搭建成功。这里分享的是分布式集群,HA集群,需要步骤比较复杂
并且需要zookeeper组件。
另外有需要云服务器可以了解下创新互联scvps.cn,海内外云服务器15元起步,三天无理由+7*72小时售后在线,公司持有idc许可证,提供“云服务器、裸金属服务器、高防服务器、香港服务器、美国服务器、虚拟主机、免备案服务器”等云主机租用服务以及企业上云的综合解决方案,具有“安全稳定、简单易用、服务可用性高、性价比高”等特点与优势,专为企业上云打造定制,能够满足用户丰富、多元化的应用场景需求。
当前名称:spark分布式集群安装-创新互联
分享链接:https://www.cdcxhl.com/article26/ddjocg.html
成都网站建设公司_创新互联,为您提供品牌网站建设、标签优化、动态网站、虚拟主机、手机网站建设、品牌网站制作
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 合格的建站公司能提供的服务 2021-11-22
- 创新互联建站公司说说网站上传图片为什么不要太大 2015-06-25
- 在选择建站公司做网站如何选择模板还是定制开 2021-08-15
- 上海建站公司那么多,谁家好啊 2020-11-11
- 你知道如何选择网站建站公司吗 2021-11-08
- 网站建设哪家公司做的好,专业建站公司 2022-12-17
- 如何衡量建站公司的好坏 2017-12-21
- 建站公司的优劣性从哪些方面考虑? 2014-05-01
- 深圳建站公司浅谈网站的运营模式 2022-05-26
- 企业网站建设需要向建站公司提供哪些资料 2015-09-26
- 成都建站公司做网站的价钱一般在是多少? 2016-09-10
- 成都建站公司的“追风史” 2023-02-14