怎么在python中使用pandas进行模糊匹配-创新互联
这期内容当中小编将会给大家带来有关怎么在python中使用pandas进行模糊匹配,文章内容丰富且以专业的角度为大家分析和叙述,阅读完这篇文章希望大家可以有所收获。
为东风等地区用户提供了全套网页设计制作服务,及东风网站建设行业解决方案。主营业务为成都网站建设、成都做网站、东风网站设计,以传统方式定制建设网站,并提供域名空间备案等一条龙服务,秉承以专业、用心的态度为用户提供真诚的服务。我们深信只要达到每一位用户的要求,就会得到认可,从而选择与我们长期合作。这样,我们也可以走得更远!python可以做什么
Python是一种编程语言,内置了许多有效的工具,Python几乎无所不能,该语言通俗易懂、容易入门、功能强大,在许多领域中都有广泛的应用,例如最热门的大数据分析,人工智能,Web开发等。
1.首先读取Excel文件
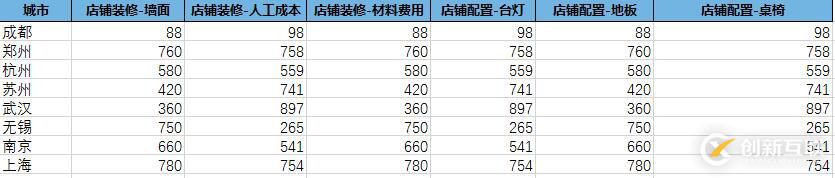
数据代表了各个城市店铺的装修和配置费用,要统计出装修和配置项的总费用并进行加和计算;
2.pandas实现过程
import pandas as pd #1.读取数据 df = pd.read_excel(r'./data/pfee.xlsx') print(df)
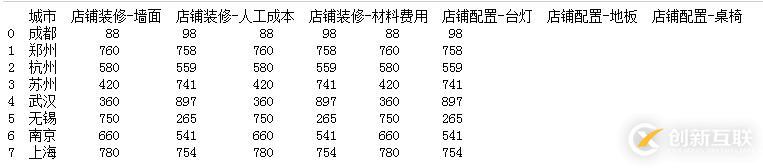
cols = list(df.columns) print(cols)

#2.获取含有装修 和 配置 字段的数据 zx_lists=[] pz_lists=[] for name in cols: if '装修' in name: zx_lists.append(name) elif '配置' in name: pz_lists.append(name) print(zx_lists) print(pz_lists)

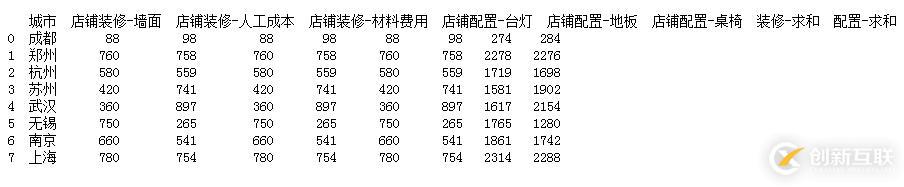
#3.对装修和配置项费用进行求和计算 df['装修-求和'] =df[zx_lists].apply(lambda x:x.sum(),axis=1) df['配置-求和'] = df[pz_lists].apply(lambda x:x.sum(),axis=1) print(df)
补充:pandas 中dataframe 中的模糊匹配 与pyspark dataframe 中的模糊匹配
1.pandas dataframe
匹配一个很简单,批量匹配如下
df_obj[df_obj['title'].str.contains(r'.*?n.*')] #使用正则表达式进行模糊匹配,*匹配0或无限次,?匹配0或1次
pyspark dataframe 中模糊匹配有两种方式
2.spark dataframe api, filter rlike 联合使用
df1=df.filter("uri rlike
'com.tencent.tmgp.sgame|%E8%80%85%E8%8D%A3%E8%80%80_|android.ugc.live|\
%e7%88f%e8%a7%86%e9%a2%91|%E7%%8F%E8%A7%86%E9%A2%91'").groupBy("uri").\
count().sort("count", ascending=False)注意点:
1.rlike 后面进行批量匹配用引号包裹即可
2.rlike 中要匹配特殊字符的话,不需要转义
3.rlike '\\\\bapple\\\\b' 虽然也可以匹配但是匹配数量不全,具体原因不明,欢迎讨论。
In [5]: df.filter("name rlike '%'").show()
+---+------+-----+
|age|height| name|
+---+------+-----+
| 4| 140|A%l%i|
| 6| 180| i%ce|
+---+------+-----+3.spark sql
spark.sql("select uri from t where uri like '%com.tencent.tmgp.sgame%' or uri like 'douyu'").show(5)如果要批量匹配的话,就需要在后面继续添加uri like '%blabla%',就有点繁琐了。
对了这里需要提到原生sql 的批量匹配,regexp 就很方便了,跟rlike 有点相似
mysql> select count(*) from url_parse where uri regexp 'android.ugc.live|com.tencent.tmgp.sgame'; +----------+ | count(*) | +----------+ | 9768 | +----------+ 1 row in set (0.52 sec)
于是这里就可以将sql中regexp 应用到spark sql 中
In [9]: spark.sql('select * from t where name regexp "%l|t|_"').show()
+---+------+------+
|age|height| name|
+---+------+------+
| 1| 150|Al_ice|
| 4| 140| A%l%i|
+---+------+------+上述就是小编为大家分享的怎么在python中使用pandas进行模糊匹配了,如果刚好有类似的疑惑,不妨参照上述分析进行理解。如果想知道更多相关知识,欢迎关注创新互联行业资讯频道。
网页标题:怎么在python中使用pandas进行模糊匹配-创新互联
本文来源:https://www.cdcxhl.com/article26/cojejg.html
成都网站建设公司_创新互联,为您提供品牌网站制作、网站建设、自适应网站、定制网站、手机网站建设、搜索引擎优化
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 上海响应式网站建设将是未来发展趋势(很重要) 2020-11-22
- 企业响应式网站建设要注意什么 2016-10-16
- 网站优化:响应式网站建设上线后还需做什么? 2014-04-08
- 营销型网站与响应式网站有哪些区别? 2022-05-03
- 邯郸响应式网站制作:手机网站给企业带来了什么机遇? 2021-11-24
- 响应式网站建设的优势是什么? 2022-12-29
- 响应式网站建设需要注意哪些细节 2016-07-08
- 响应式网站建设应该如何排版? 2015-08-01
- 响应式网站建设为什么深受企业的青睐? 2022-01-27
- 创新互联前端技术总监张春擂谈响应式网站建设 2022-07-04
- 响应式网站设计的一般流程是怎样的? 2013-07-27
- 为何越来越多的企业选择响应式网站建设? 2022-08-06