java--那些事-创新互联
1、为什么Controller层注入的是Service接口,而不是ServiceImpl实现类
Controller层
@Autowired
private TestImpl testImpl; //注入了实现类
面向接口编程
(1)注入的就是实现类,只不过拿接口来接收,接收的类型为接口,面向接口编程,那么为何要面向接口编程?这就涉及到使用接口做代理,因为通过@autowired的对象是通过接口的方式会使用jdk动态代理,jdk动态代理只能对实现接口的类生成代理,而不能针对类。
(2)注入的是实现类对象,接收的是接口;理解为多态;
要遵循Controller–Service接口–ServiceImpt实现类–Mapper接口模式;
2、分布式锁三种实现方式
(1)、 基于数据库实现分布式锁;
(2)、基于缓存(Redis等)实现分布式锁;
(3)、 基于Zookeeper实现分布式锁;
一、基于数据库实现分布式锁
1. 悲观锁
利用select … where … for update 排他锁
注意: 其他附加功能与实现一基本一致,这里需要注意的是“where name=lock ”,name字段必须要走索引,否则会锁表。有些情况下,比如表不大,mysql优化器会不走这个索引,导致锁表问题。
2. 乐观锁
所谓乐观锁与前边大区别在于基于CAS思想,是不具有互斥性,不会产生锁等待而消耗资源,操作过程中认为不存在并发冲突,只有update version失败后才能觉察到。我们的抢购、秒杀就是用了这种实现以防止超卖。
通过增加递增的版本号字段实现乐观
3:分布式锁三种实现方式对比:
数据库分布式锁实现
缺点:
1.db操作性能较差,并且有锁表的风险
2.非阻塞操作失败后,需要轮询,占用cpu资源;
3.长时间不commit或者长时间轮询,可能会占用较多连接资源
Redis(缓存)分布式锁实现
缺点:
1.锁删除失败 过期时间不好控制
2.非阻塞,操作失败后,需要轮询,占用cpu资源;
ZK分布式锁实现
缺点:性能不如redis实现,主要原因是写操作(获取锁释放锁)都需要在Leader上执行,然后同步到follower。
总之:ZooKeeper有较好的性能和可靠性。
从理解的难易程度角度(从低到高)数据库 >缓存 >Zookeeper
从实现的复杂性角度(从低到高)Zookeeper >= 缓存 >数据库
从性能角度(从高到低)缓存 >Zookeeper >= 数据库
从可靠性角度(从高到低)Zookeeper >缓存 >数据库
4、Kafka、RocketMQ、RabbitMQ的对比
RabbitMq
- 由于erlang语言的特性,mq 性能较好,高并发;
- 吞吐量到万级,MQ功能比较完备;
- 健壮、稳定、易用、跨平台、支持多种语言、文档齐全;
- 开源提供的管理界面非常棒,用起来很好用;
- 社区活跃度高;
缺点
- erlang开发,很难去看懂源码,基本职能依赖于开源社区的快速维护和修复bug,不利于做二次开发和维护;
- RabbitMQ确实吞吐量会低一些,这是因为他做的实现机制比较重;
- 需要学习比较复杂的接口和协议,学习和维护成本较高;
RocketMQ:
优点:
- 单机吞吐量:十万级;
- 可用性:非常高,分布式架构;
- 消息可靠性:经过参数优化配置,消息可以做到0丢失;
- 功能支持:MQ功能较为完善,还是分布式的,扩展性好;
- 支持10亿级别的消息堆积,不会因为堆积导致性能下降;
- 源码是java,我们可以自己阅读源码,定制自己公司的MQ,可以掌控;
缺点
- 支持的客户端语言不多,目前是java及c++,其中c++不成熟;
- 社区活跃度一般;
- 没有在 mq 核心中去实现JMS等接口,有些系统要迁移需要修改大量代码;
Kafka:
优点:
- 性能卓越,单机写入TPS约在百万条/秒,大的优点,就是吞吐量高;
- 时效性:ms级;
- 可用性:非常高,kafka是分布式的,一个数据多个副本,少数机器宕机,不会丢失数据,不会导致不可用;
- 消费者采用Pull方式获取消息, 消息有序, 通过控制能够保证所有消息被消费且仅被消费一次;
- 有优秀的第三方Kafka Web管理界面Kafka-Manager;
- 在日志领域比较成熟,被多家公司和多个开源项目使用;
- 功能支持:功能较为简单,主要支持简单的MQ功能,在大数据领域的实时计算以及日志采集被大规模使用;
缺点:
- Kafka单机超过64个队列/分区,Load会发生明显的飙高现象,队列越多,load越高,发送消息响应时间变长;
- 使用短轮询方式,实时性取决于轮询间隔时间;
- 消费失败不支持重试;
- 支持消息顺序,但是一台代理宕机后,就会产生消息乱序;
- 不支持延迟队列
- 不支持死信队列
- 社区更新较慢;
三者主要区别:
| 产品 | 建议 |
|---|---|
| Kafka | Kafka主要特点是基于Pull的模式来处理消息消费,追求高吞吐量,一开始的目的就是用于日志收集和传输,适合产生大量数据的互联网服务的数据收集业务。 大型公司建议可以选用,如果有日志采集功能,肯定是选kafka了。 |
| RocketMQ | 天生为金融互联网领域而生,对于可靠性要求很高的场景,尤其是电商里面的订单扣款,以及业务削峰,在大量交易涌入时,后端可能无法及时处理的情况。 RoketMQ在稳定性上可能更值得信赖,这些业务场景在阿里双11已经经历了多次考验,如果你的业务有上述并发场景,建议可以选择RocketMQ。 |
| RabbitMQ | 结合erlang语言本身的并发优势,性能较好,社区活跃度也比较高,但是不利于做二次开发和维护。不过,RabbitMQ的社区十分活跃,可以解决开发过程中遇到的bug。 如果你的数据量没有那么大,小公司优先选择功能比较完备的RabbitMQ。 |
5、分布式事务--》CAP理论和BASE理论
1)CAP理论
1998年,加州大学的计算机科学家 Eric Brewer 提出,分布式系统有三个指标:
- Consistency(一致性)
- Availability(可用性)
- Partition tolerance (分区容错性)
CAP定理- Consistency
Consistency(一致性):用户访问分布式系统中的任意节点,得到的数据必须一致 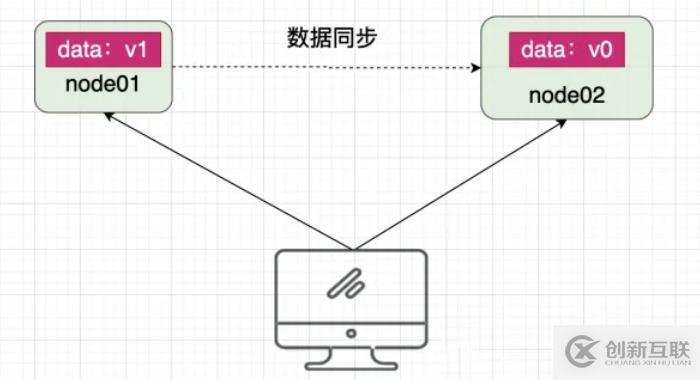
CAP定理- Availability
Availability (可用性):用户访问集群中的任意健康节点,必须能得到响应,而不是超时或拒绝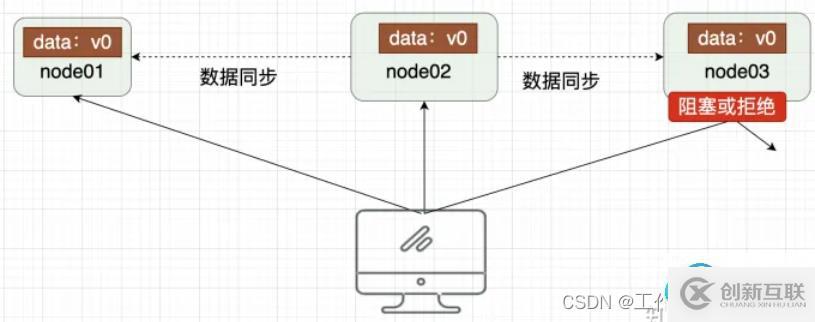
CAP定理-Partition tolerance
- Partition(分区):因为网络故障或其它原因导致分布式系统中的部分节点与其它节点失去连接,形成独立分区。
- Tolerance(容错):在集群出现分区时,整个系统也要持续对外提供服务
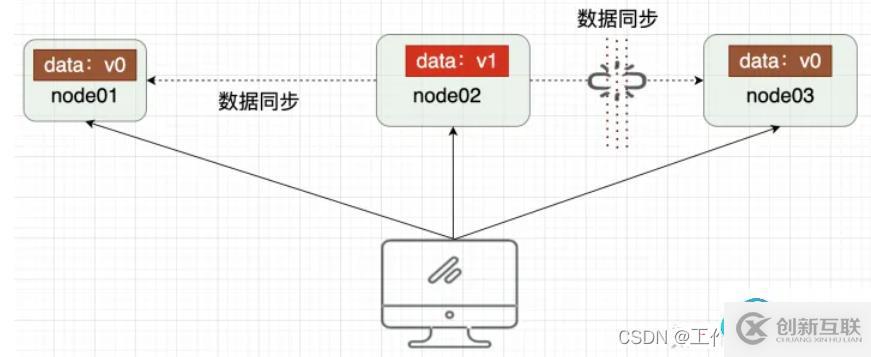
2)BASE理论
BASE理论是对CAP的一种解决思路,包含三个思想:
- Basically Available (基本可用):分布式系统在出现故障时,允许损失部分可用性,即保证核心可用。
- Soft State(软状态):在一定时间内,允许出现中间状态,比如临时的不一致状态。
- Eventually Consistent(最终一致性):虽然无法保证强一致性,但是在软状态结束后,最终达到数据一致。
而分布式事务大的问题是各个子事务的一致性问题,因此可以借鉴CAP定理和BASE理论:
- AP模式:各子事务分别执行和提交,允许出现结果不一致,然后采用弥补措施恢复数据即可,实现最终一致。
- CP模式:各个子事务执行后互相等待,同时提交,同时回滚,达成强一致。但事务等待过程中,处于弱可用状态
你是否还在寻找稳定的海外服务器提供商?创新互联www.cdcxhl.cn海外机房具备T级流量清洗系统配攻击溯源,准确流量调度确保服务器高可用性,企业级服务器适合批量采购,新人活动首月15元起,快前往官网查看详情吧
新闻标题:java--那些事-创新互联
分享链接:https://www.cdcxhl.com/article26/cecgcg.html
成都网站建设公司_创新互联,为您提供小程序开发、外贸建站、微信小程序、静态网站、ChatGPT、App开发
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 虚拟主机与独立IP网站优化所需要的SEO技巧 2021-11-09
- 网站空间(云虚拟主机)与域名报价参考 2015-03-25
- 创新互联谈网站优化要更换虚拟主机吗 2022-07-08
- 做网站选择虚拟主机还是服务器好? 2022-10-05
- 网站建设如何选择虚拟主机 2015-08-26
- 选择正确的虚拟主机服务商应该看哪几个方面 2014-03-30
- 什么是虚拟主机以及如何租用 2022-10-07
- 服务器、虚拟主机、虚拟空间的含义和关系 2013-06-30
- 满足公司网站运行的虚拟主机应具备的基础配置 2022-05-21
- 为什么云服务器比虚拟主机贵?贵在哪? 2022-10-03
- 虚拟主机如何建站? 2016-09-29
- 大数据帮助选择理想虚拟主机的10种方法 2021-02-09