Node.js中怎么使用URL模块解析地址
这篇文章给大家介绍Node.js中怎么使用URL模块解析地址,内容非常详细,感兴趣的小伙伴们可以参考借鉴,希望对大家能有所帮助。
在凭祥等地区,都构建了全面的区域性战略布局,加强发展的系统性、市场前瞻性、产品创新能力,以专注、极致的服务理念,为客户提供成都做网站、成都网站制作 网站设计制作按需网站建设,公司网站建设,企业网站建设,成都品牌网站建设,成都全网营销,外贸网站建设,凭祥网站建设费用合理。
url结构化/模块化/路径解析
结构化:
url.parse(urlString[, parseQueryString[, slashesDenoteHost]])模块化:
url.format(urlObject)路径解析:
url.resolve(from, to)
一个URL字符串是一个结构化的字符串包含多个有意义的组件。在解析时,返回一个URL对象包含每一个组件的属性。
官方手册上面的一张图是这样子的:
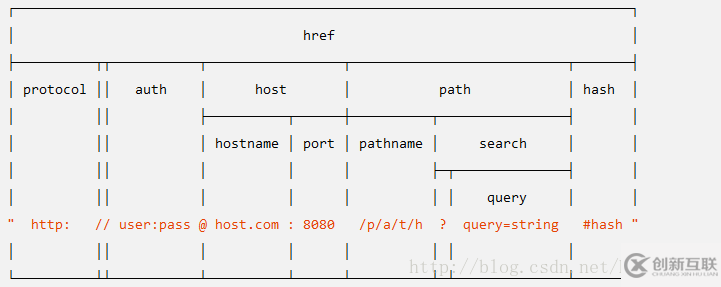
这张图解释了一个url结构化成哪些部分,哪些部分又包含哪些部分
protocol: 请求协议
host: URL主机名已全部转换成小写, 包括端口信息
auth:URL中身份验证信息部分
hostname:主机的主机名部分, 已转换成小写
port: 主机的端口号部分
pathname: URL的路径部分,位于主机名之后请求查询之前
search: URL 的“查询字符串”部分,包括开头的问号。
path: pathname 和 search 连在一起。
query: 查询字符串中的参数部分(问号后面部分字符串),或者使用 querystring.parse() 解析后返回的对象。
hash: URL 的 “#” 后面部分(包括 # 符号)
url结构化
将一个url地址结构化成为拥有上图属性的url对象。url.parse第二个和第三个参数默认为false。
第二个参数决定query属性值是字符串还是对象
第三个参数如果为true,//后的第一个令牌文字字符串和下一个/之间的文字字符串将被解释为主机
例子如下
const url = require("url");
var urlstr = "http://localhost:8888/bb?name=bigbear&memo=helloworld&memo=helloC";
var urlobj = url.parse(urlstr);
console.log(urlobj);
/*
Url {
protocol: 'http:',
slashes: true,
auth: null,
host: 'localhost:8888',
port: '8888',
hostname: 'localhost',
hash: null,
search: '?name=bigbear&memo=helloworld&memo=helloC',
query: 'name=bigbear&memo=helloworld&memo=helloC',
pathname: '/bb',
path: '/bb?name=bigbear&memo=helloworld&memo=helloC',
href: 'http://localhost:8888/bb?name=bigbear&memo=helloworld&memo=helloC' }
*/第二个参数为true时
query: { name: ‘bigbear', memo: [ ‘helloworld', ‘helloC' ] },例子如下:
const url = require("url");
var urlstr = "http://localhost:8888/bb?name=bigbear&memo=helloworld&memo=helloC";
console.log(
url.parse(urlstr, true)
)
/*
Url {
protocol: 'http:',
slashes: true,
auth: null,
host: 'localhost:8888',
port: '8888',
hostname: 'localhost',
hash: null,
search: '?name=bigbear&memo=helloworld&memo=helloC',
query: { name: 'bigbear', memo: [ 'helloworld', 'helloC' ] },
pathname: '/bb',
path: '/bb?name=bigbear&memo=helloworld&memo=helloC',
href: 'http://localhost:8888/bb?name=bigbear&memo=helloworld&memo=helloC' }
*/第三个参数对比
例子如下:
const url = require("url");
var urlstr = "//foo/bar ";
console.log(
url.parse(urlstr, true,true)
)
/*
输出:Url {
protocol: null,
slashes: true,
auth: null,
host: 'foo',
port: null,
hostname: 'foo',
hash: null,
search: '',
query: {},
pathname: '/bar',
path: '/bar',
href: '//foo/bar' }
*/
const url = require("url");
var urlstr = "//foo/bar ";
console.log(
url.parse(urlstr)
)
/*
输出:
Url {
protocol: null,
slashes: null,
auth: null,
host: null,
port: null,
hostname: null,
hash: null,
search: null,
query: null,
pathname: '//foo/bar',
path: '//foo/bar',
href: '//foo/bar' }
*/url模块化
将一个url对象转换成一个url字符串,url对象中的属性为url.parse()产生的对象的属性。
url.parse()和url.format()互为逆操作。
例子如下:
const url = require("url");
var Urlobj = {
protocol: 'http:',
slashes: true,
auth: null,
host: 'localhost:8888',
port: '8888',
hostname: 'localhost',
hash: null,
search: '?name=bigbear&memo=helloworld&memo=helloC',
query: { name: 'bigbear', memo: [ 'helloworld', 'helloC' ] },
pathname: '/bb',
path: '/bb?name=bigbear&memo=helloworld&memo=helloC',
}
console.log(
url.format(Urlobj)
)
//输出:http://localhost:8888/bb?name=bigbear&memo=helloworld&memo=helloC路径解析:url.resolve(from, to)
url.resolve()方法解决了目标URL相对于基本URL的方式类似于Web浏览器解决锚标记href。
官方手册例子:
url.resolve('/one/two/three', 'four');
// '/one/two/four'
url.resolve('http://example.com/', '/one');
// 'http://example.com/one'
url.resolve('http://example.com/one', '/two');
// 'http://example.com/two'关于Node.js中怎么使用URL模块解析地址就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
标题名称:Node.js中怎么使用URL模块解析地址
文章网址:https://www.cdcxhl.com/article24/iehije.html
成都网站建设公司_创新互联,为您提供网站设计公司、网站建设、微信小程序、虚拟主机、网站设计、微信公众号
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 网站内链如何优化 2021-09-29
- SEO分析网站内链如何进行优化 2020-12-09
- 企业网站内链优化要怎样做才有排名? 2023-04-05
- 三种方法让你网站内链迅速增长 2015-05-05
- 网站内链与网站优化之间有什么关系 2013-12-17
- 网站内链优化怎么做,营销型网站内链怎么做 2016-11-03
- 网站内链SEO优化的4个技巧 2021-12-11
- 建设网站内链有哪些窍门? 2022-10-19
- 可以做好网络网站内链优化的五种方法 2021-08-19
- 网站内链锚文本布局方法有哪些? 2020-07-31
- 网站内链的常见展现方式 2022-05-26
- 浅谈网站内链布局的作用 2021-12-13