常用的字符串与内存操作函数(2)-创新互联
1. 

2.


1. C语言的库函数在运行的时候,如果发生错误,就会将错误码存在一个变量里面。这个变量就是:errno(全局变量)。
2. 这个函数的功能在于把错误码转化为对应的错误信息,错误信息说白了就是一个字符串,它返回错误信息所对应的地址(并不是直接打印出来), 这个函数其实就是你给我传一个数字,我把这个数字对应的错误信息的起始地址给你返回来。

正是因为电脑库函数运行一旦发生错误,计算机就会主动把错误码放到errno这个全局变量里面去,因此strerror的参数往往就是errno
3. 错误码是一些数字,比方说1.2.3.4.....我们需要将错误码翻译成错误信息,其实每一个这样的错误码都对应着一个错误信息
4. 这个函数其实就是你给我传一个数字,我把这个数字对应的错误信息的起始地址给你返回来。
5. 因为错误信息本质上也是一个字符串,所以这个函数就是把错误码对应的错误信息(其实也是一个字符串)首字符的地址给你返回来,所以printf%s直接可以打印出来
6. 实际上当C语言的库函数运行出错误的时候,我们会把错误码放到errno这样一个全局变量里面去,然后你去看这个变量里面的错误码,在翻译成错误信息。
7. 比方说要打开一个文件,打开文件在C语言里面用一函数fopen()。我要用这个函数的话,首先得提供一个文件名,在提供一个打开方式。这个函数会返回一个FILE*类型的指针,这个函数如果打开文件成功,就会返回一个有效非空指针;如果打开失败,返回NULL空指针。当我打开文件失败的时候,就很懵逼,到底是什么原因呢?怎么办呢?我就不打印什么“打开文件失败”,我直接用printf%s加上strerror(errno)打印错误信息

8. 用strerror要引用string.h,用errno要用errno.h
9. 你使用errno的前提是前面调用那个函数失败了,它把错误码放进全局变量errno里面去了,这时候你把错误码用strerror转化成错误信息可以看到
perror()

1. 还有一个函数perror,它其实是打印错误信息, 是更加直接直接打印错误信息。在打印错误信息之前,你可以自己先传一些自定义信息,它会先打印你给它的信息。
2. perror自己肯定会去捕获errno里面的错误码,然后自己转化为错误信息,直接给你打印出来,当然还可以加上你给的前缀。
3. perror = printf + strerror。
4. 它主动会去找错误信息。但它不管三七二十一直接打印错误信息,但如果我只是为了把错误码转化为错误信息,想获得错误信息的字符串,并不想打印,那么我还得回归到strerror去得到错误信息字符串首地址。
5. 


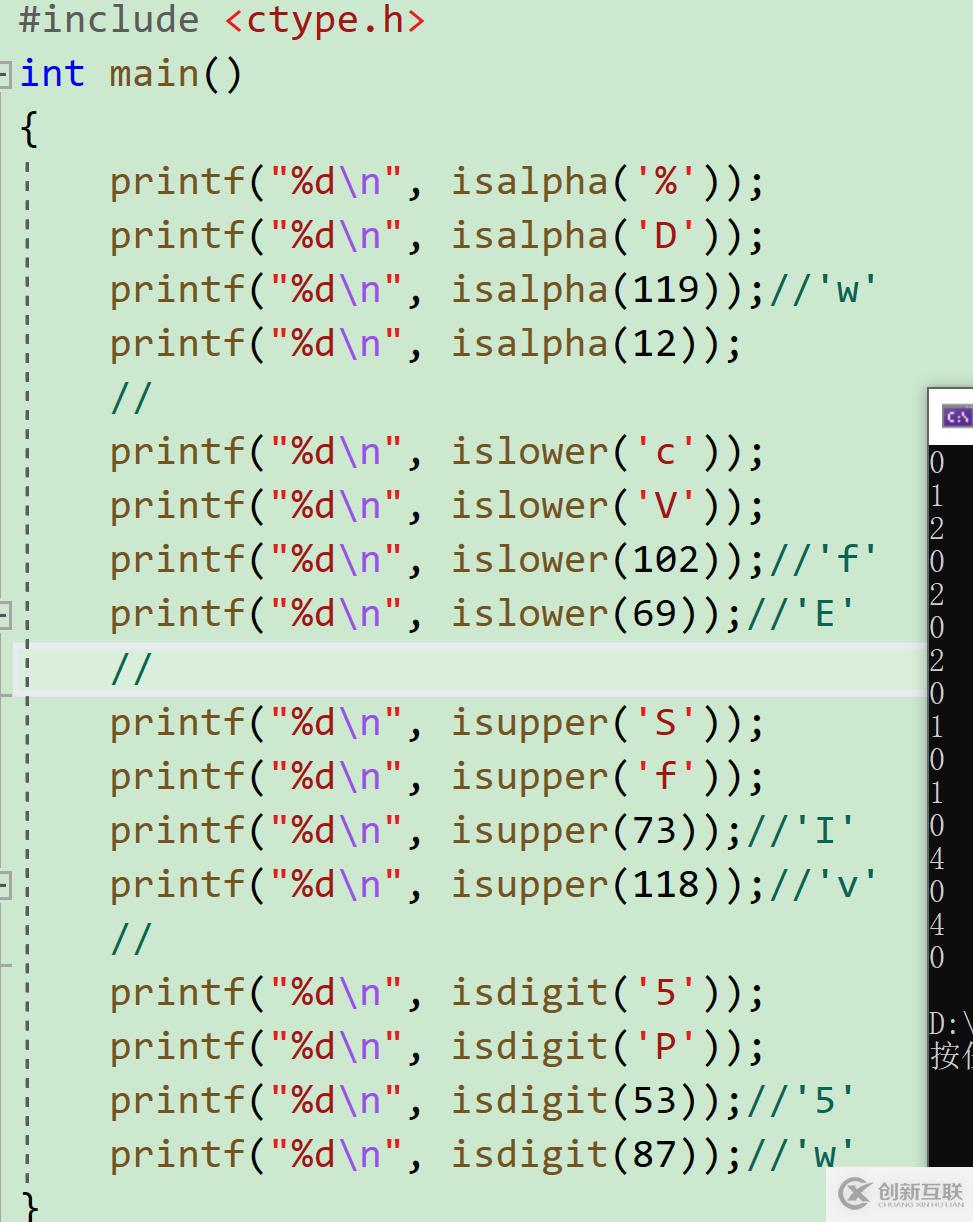
1. 之前这些都是与字符串相关的函数,而我们现在这些是与字符相关的
2. 这些is...字符分类函数的设计全都是一样的,如果是,返回一个非0数字,不是的话就返回0。
参考:

3. 都是需要引用头文件的 ctype.h
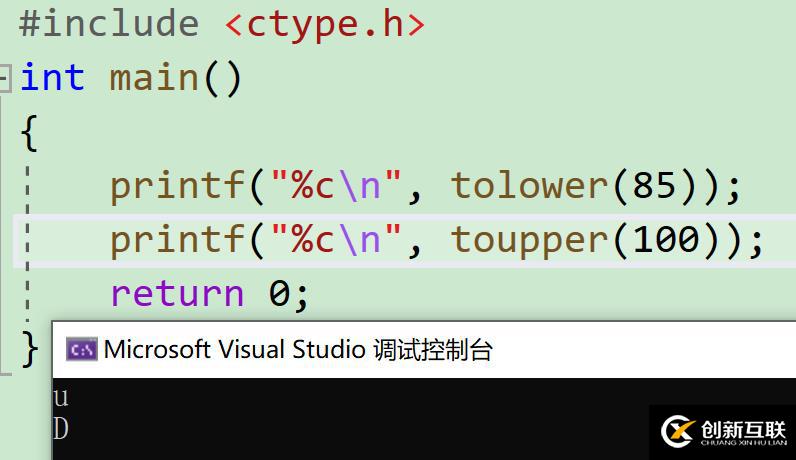
1. 还有一种是字符转换函数tolower()与toupper()。注意在上述这些函数里面,字符与ACSII码两者不用太过于纠结,两者是很灵活地可以自由根据情况转化的
例: 将单词首字母改成大写的
#include#includeint main()
{
char arr[20] = { 0 };
gets(arr);
int sz = strlen(arr);
if (islower(*arr))
*arr = toupper(*arr);
int i = 0;
for (i = 1; i< sz - 1; i++)
{
if (islower(*(arr + i)) && *(arr + i - 1) == ' ')
{
*(arr + i) = toupper(*(arr + i));
}
}
printf("%s\n",arr);
} 
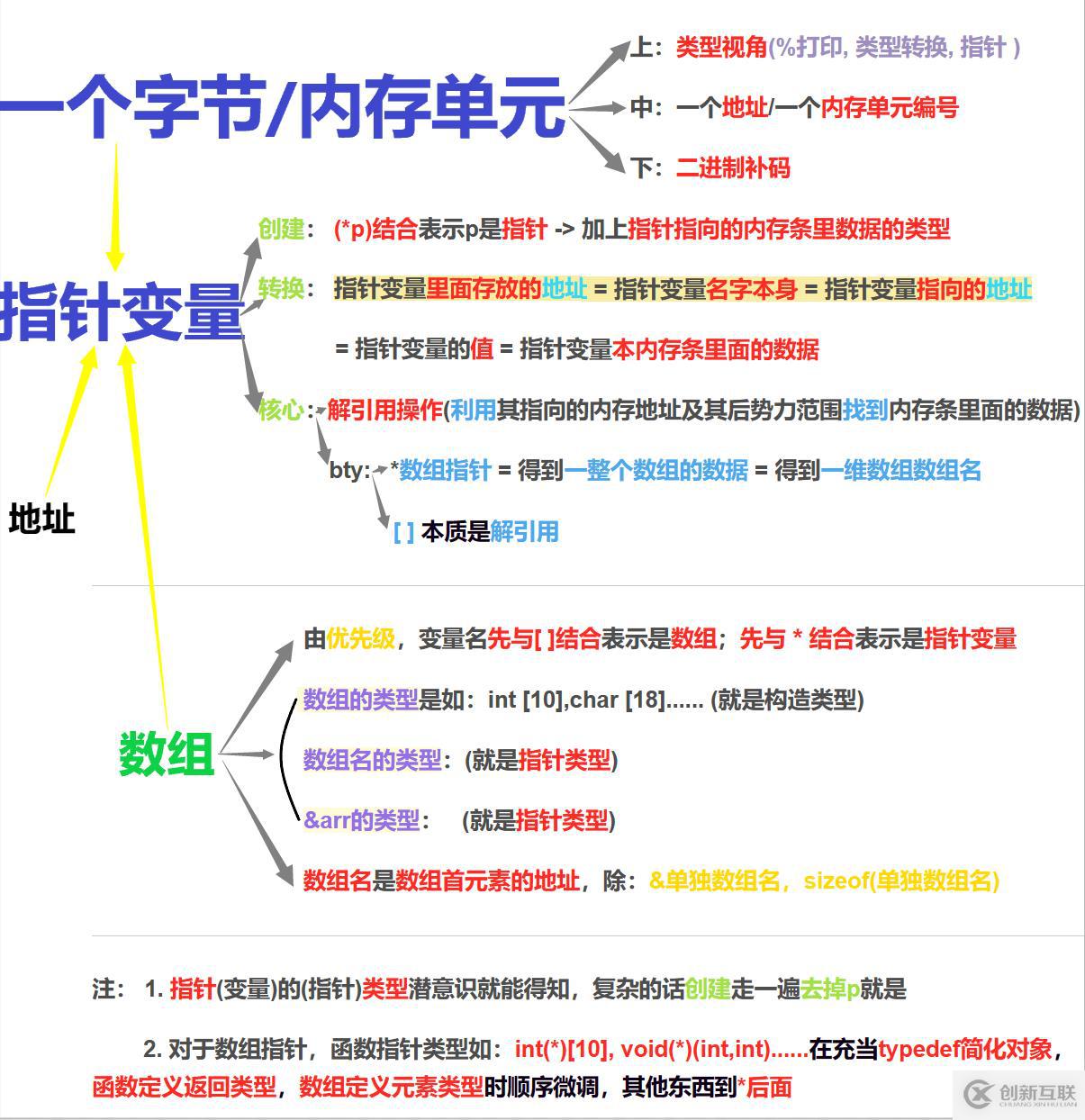
1. 为什么有了字符串的拷贝之后,还需要内存的拷贝呢?因为字符串的拷贝只针对字符串,而我如果想要两个整型数组拷贝则束手无策。
2. 拷贝其他东西,那么只能通过内存拷贝函数了。
3. 你会发现它的参数是void*,为啥呢?因为这个是内存拷贝,你内存条里的数据类型可能是整数(拷贝整型数组),可能是结构体(拷贝结构体数组),可能是浮点数.....为了使得该函数有良好的兼容性,用瞎子垃圾桶void*可以接受任何类型,也正是因为是瞎子void*因为我得指定第三个参数,你要拷贝几个字节得给我传过来。
4.
1. 拷贝多少个字节,你要自己去算的。而且你的目标指针与源头指针得自己看好,想怎么搞就怎么搞
2. void*接受完后,这个参数指针就是void*了,就是瞎子,但好在你指定了多少个字节拷贝数。
3. 拷贝多少个字节不一定要凑好,它不挑剔的,这时候就需要涉及到大小端字节序存储了,自己看着办。大小端字节序存储对指针解引用与内存操作函数都可能有影响。

5. 模拟实现memcpy()
#include
void* my_memcpy(void* dest, const void* src, size_t num)
{
assert(dest && src);
void* ret = dest;
while (num--)
{
*(char*)dest = *(char*)src;
dest = (char*)dest + 1;
src = (char*)src + 1;
}
return ret;
}注:
1. 参数是void*,无法解引用,需要强制类型转换。这时候你思考的纬度是一个字节/内存单元。而且计算机里面也是以字节为基本单位。强制类型转换为char*这样子你这个指针的势力范围与步长都与基本单位匹配了。
2. 强制类型转换是临时的
3. 返回一个void*指针,回头你要用自己转换成要想的类型

1. 这边主要是涉及到要拷贝的内存空间与目标内存空间重叠的一个问题,那么这时候该怎么去拷贝呢
2. 总原则:源头指针指向的要拷贝的内容不要被覆盖与破坏3. 模拟实现memmove()
#include
void* my_memcpy(void* dest, const void* src, size_t num)
{
void* ret = dest;
assert(dest && src);
while (num--)
{
if (src >dest)
{
*((char*)dest) = *((char*)src);
dest = (char*)dest + 1;
src = (char*)src + 1;
}
else
{
*((char*)dest + num) = *((char*)src + num);
}
}
return ret;
}附:

1. 如同strcmp()一样,memcmp也是对应位置一对字节一对字节依次这么去比较
2. 一个字节其实里面就是八位二进制数,当然可以比较了
3. 再次说明,大小端字节序存储对于指针解引用操作与内存操作函数都是有影响的
4. 返回类型与strcmp一个道理
memset() (内存放置函数)
1. 其实就是将内存设置成我们想要的内容,是以字节为基本单位,以字节为单位来设置内存中的数据的。
2. 返回的是参数指针ptr
3. 
你是否还在寻找稳定的海外服务器提供商?创新互联www.cdcxhl.cn海外机房具备T级流量清洗系统配攻击溯源,准确流量调度确保服务器高可用性,企业级服务器适合批量采购,新人活动首月15元起,快前往官网查看详情吧
当前文章:常用的字符串与内存操作函数(2)-创新互联
链接地址:https://www.cdcxhl.com/article24/djedje.html
成都网站建设公司_创新互联,为您提供小程序开发、ChatGPT、软件开发、外贸网站建设、电子商务、标签优化
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 想做微信小程序代理赚钱?选对领域是关键! 2016-10-01
- 对话微信小程序行业负责人:坚持做去中心化 2022-04-27
- 你做微信小程序这么久,为什么没能留住用户? 2021-02-13
- 微信小程序成了大新闻,它会改变什么? 2022-06-20
- 微信小程序正式发布,你想知道的都在这! 2022-08-22
- 为什么要制作小程序,怎么开发微信小程序比较赚钱? 2022-08-07
- 微信小程序怎样开发?来看详细的开发教程 2022-04-15
- 成都微信小程序开发公司哪家好?_成都创新互联 2021-12-26
- 微信小程序开发工具下载 2013-09-25
- 微信小程序开发需要注意哪些事项 2022-11-19
- 定制属于自己的微信小程序!需要投入多少费用 2022-05-27
- 微信小程序开发后应该如何运营? 2020-12-16