Zookeeper的基础原理及应用场景
本篇内容介绍了“Zookeeper的基础原理及应用场景”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
目前创新互联已为超过千家的企业提供了网站建设、域名、虚拟主机、网站托管维护、企业网站设计、桓仁网站维护等服务,公司将坚持客户导向、应用为本的策略,正道将秉承"和谐、参与、激情"的文化,与客户和合作伙伴齐心协力一起成长,共同发展。
简单了解Zookeeper
Tips: 如果之前对Zookeeper不了解的话,这里大概留个印象就好了
Zookeeper是一个分布式协调服务,可以用于元数据管理、分布式锁、分布式协调、发布订阅、服务命名等等。
例如,Kafka中就是用Zookeeper来保存其集群中的相关元数据,例如Broker、Topic以及Partition等等。同时,基于Zookeeper的Watch监听机制,还可以用其实现发布、订阅的功能。
在平常的常规业务使用场景下,我们几乎只会使用到分布式锁这一个用途。
Zookeeper内部运行机制
Zookeeper的底层存储原理,有点类似于Linux中的文件系统。Zookeeper中的文件系统中的每个文件都是节点(Znode)。根据文件之间的层级关系,Zookeeper内部就会形成这个这样一个文件树。
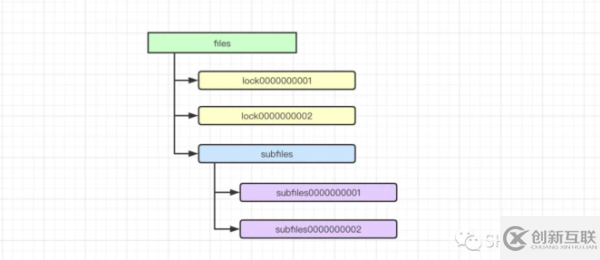
在Linux中,文件(节点)其实是分类型的,例如分为文件、目录。在Zookeeper中同理,Znode同样的有类型。在Zookeeper中,所有的节点类型如下:
持久节点(Persistent)
持久顺序节点(Persistent Sequential)
临时节点(Ephemeral)
临时顺序节点(Ephemeral Sequential)
所谓持久节点,就和我们自己在电脑上新建一个文件一样,除非你主动删除,否则一直存在。
而持久顺序节点除了继承了持久节点的特性之外,还会为其下创建的子节点保证其先后顺序,并且会自动地为节点加上10位自增序列号作为节点名,以此来保证节点名的唯一性。这一点上图中的subfiles已经给出了示例。
而临时节点,其生命周期和client的连接是否活跃相关,如果client一旦断开连接,该节点(可以理解为文件)就都会被删除,并且临时节点无法创建子节点;
PS:这里的断开连接其实不是我们直觉上理解的断开连接,Zookeeper有其Session机制,当某个client的Session过期之后,会将对应的client创建的节点全部删除
Zookeeper的节点创建方式
接下来我们来分别看看几种节点的创建方式,给出几个简单的示例。
创建持久节点
create /node_name SH的全栈笔记

这里需要注意的是,命令中所有的节点名称必须要以/开头,否则会创建失败,因为在Zookeeper中是不能使用相对路径,必须要使用绝对路径。

创建持久顺序节点
create -s /node_name SH的全栈笔记

可以看到,Zookeeper为key自动的加上了10位的自增后缀。
创建临时节点
create -e /test SH的全栈笔记
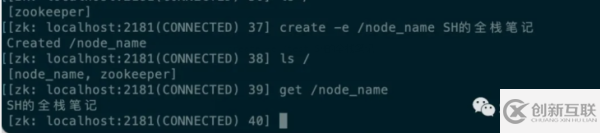
创建临时顺序节点
create -e -s /node_name SH的全栈笔记

Zookeeper的用途
我们通过一些具体的例子,来了解Zookeeper的详细用途,它不仅仅只是被当作分布式锁使用。
元数据管理
我们都知道,Kafka在运行时会依赖一个Zookeeper的集群。Kafka通过Zookeeper来管理集群的相关元数据,并通过Zookeeper进行Leader选举。
Tips: 但是即将发布的Kafka 2.8版本中,Zookeeper已经不是一个必需的组件了。这块我暂时还没有时间去细看,不过我估计可能会跟RocketMQ中处理的方式差不多,将其集群的元数据放到Kafka本身来处理。
分布式锁
基于Zookeeper的分布式锁其实流程很简单。首先我们需要知道加分布式锁的本质是什么?
答案是创建临时顺序节点
当某个客户端加锁成功之后,实际上则是成功的在Zookeeper上创建了临时顺序节点。我们知道,分布式锁能够使同一时间只能有一个能够访问某种资源。那这就必然会涉及到分布式锁的竞争,那问题来了,当前这个客户端是如何感知抢到了锁呢?
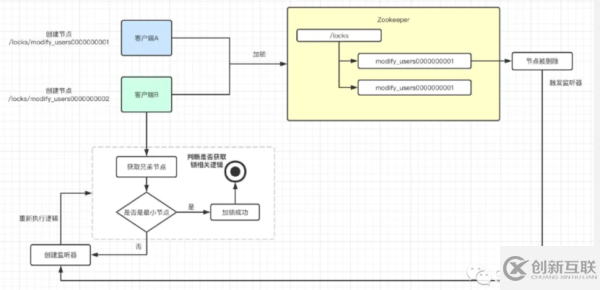
其实在客户端侧会有一定的逻辑,假设加锁的key为/locks/modify_users。
首先,客户端会发起加锁请求,然后会在Zookeeper上创建持久节点locks,然后会在该节点下创建临时顺序节点。临时顺序节点的创建示例,如下图所示。
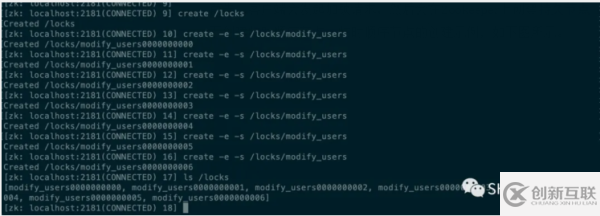
当客户端成功创建了节点之后,还会获取其同级的所有节点。也就是上图中的所有modify_users000000000x的节点。
此时客户端会根据10位的自增序号去判断,当前自己创建的节点是否是所有的节点中最小的那个,如果是最小的则自己获取到了分布式锁。
你可能会问,那如果我不是最小的怎么办呢?而且我的节点都已经创建了。如果不是最小的,说明当前客户端并没有抢到锁。按照我们的认知,如果没有竞争到分布式锁,则会等待。等待的底层都做了什么?我们用实际例子来捋一遍。
假设Zookeeper中已经有了如下的节点。
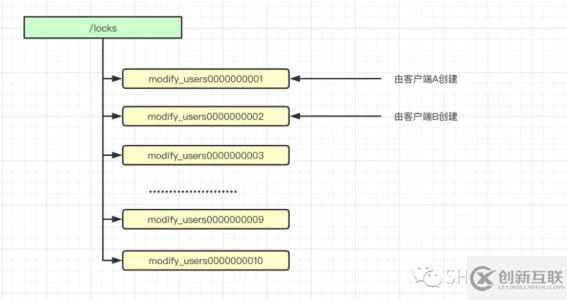
例如当前客户端是B创建的节点是modify_users0000000002,那么很明显B没有抢到锁,因为已经有比它还要小的由客户端A创建的节点modify_users0000000001。
此时客户端B会对节点modify_users0000000001注册一个监听器,对于该节点的任意更新都将触发对应的操作。
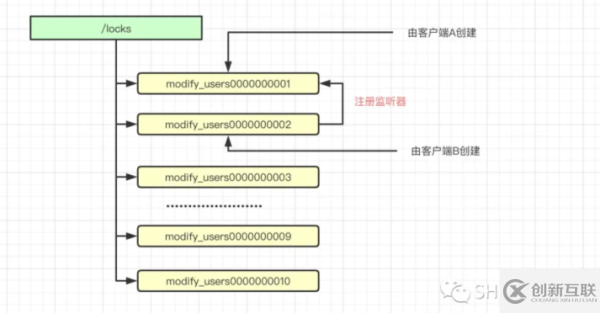
当其被删除之后,就会唤醒客户端B的线程,此时客户端B会再次进行判断自己是否是序号最小的一个节点,此时modify_users0000000002明显是最小的节点,故客户端B加锁成功。
为了让你更加直观的了解这个过程,我把流程浓缩成了下面这幅流程图。
分布式协调
我们都知道,在很多场景下要保证一致性都会采用经典的2PC(两阶段提交),例如MySQL中Redo Log和Binlog提交的数据一致性保障就是采用的2PC,详情可以看基于Redo Log和Undo Log的MySQL崩溃恢复流程。
在2PC中存在两种角色,分别是参与者(Participant)和协调者(Coordinator),协调者负责统一的调度所有分布式节点的执行逻辑。具体协调啥呢?举个例子。
例如在2PC的Commit阶段,两个参与者A、B,A的commit操作成功了,但不幸的是B失败了。此时协调者就需要向A发送Rollback操作。Zookeeper大概就是这样一个角色。
发布订阅
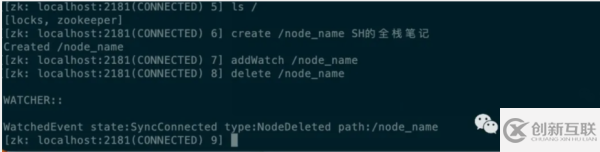
由于Zookeeper自带了监听器(Watch)的功能,所以发布订阅也顺理成章的成为了Zookeeper的应用之一。例如在某个配置节点上注册了监听器,那么该配置一旦发布变更,对应的服务就能实时的感知到配置更改,从而达到配置的动态更新的目的。
给个简单的Watch使用示例。
命名服务
用大白话来说,命名服务主要有两种。
单纯的利用Zookeeper的文件系统特性,存储结构化的文件
利用文件特性和顺序节点的特性,来生成全局的唯一标识
前者可以用于在系统之间共享某种业务上的特定资源,后者则可以用于实现分布式锁。
“Zookeeper的基础原理及应用场景”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注创新互联网站,小编将为大家输出更多高质量的实用文章!
当前标题:Zookeeper的基础原理及应用场景
网页链接:https://www.cdcxhl.com/article22/jdcjjc.html
成都网站建设公司_创新互联,为您提供服务器托管、搜索引擎优化、面包屑导航、动态网站、微信小程序、网站策划
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 高端定制网站建设的好处有哪些呢? 2023-03-12
- 张家界网站定制-定制网站建设重点5步骤 2021-11-06
- 企业定制网站建设对排名和效果哪些帮助? 2020-12-15
- 成都网站建设-定制网站开发流程 2018-06-04
- 成都定制网站的效果有多重要? 2022-07-31
- 定制网站建设有什么优势? 2022-05-02
- 定制网站建设 拒绝模板 定制网站 拒绝千篇一律 2022-06-19
- 定制网站建设必须注意的四点关键问题! 2022-10-26
- 定制网站建设都有哪些特点? 2022-12-11
- 怎样定制网站内容? 2022-05-08
- 定制网站需要注意那些问题 2022-05-12
- 模板网站和定制网站的区别在哪里 2021-04-18