新手使用python采集数据的尴尬事之代理ip-创新互联
背景 , 原本不是爬虫的,因公司业务需求需要一些前程无忧的数据,被迫上岗,简单的学了些python。因为网站的特殊性,访问次数多了就要封ip,意味着还要找ip。所以在网上随便找了家代理叫亿牛云,然后跟客服沟通了下我这个小白的需求,客服跟我推介了他们家的爬虫动态转发代理,说适合我这样的小白使用,使用方式比较简单,我就抱着试试的想法接受了。客服给我发了一段关于python怎么使用他们家代理的代码示例,https://www.16yun.cn/help/ss_demo/#1python。打开看了之后我以为示例就是可以直接使用的,而且客服也说过代码示例可以直接复制使用,我就直接复制然后把目标网站改成了我自己的,代码如下

#! -*- encoding:utf-8 -*-
import requests
import random
# 要访问的目标页面
targetUrl = " www. mkt.51job.com"
# 要访问的目标HTTPS页面
# targetUrl = "https:// www. mkt.51job.com "
# 代理服务器(产品官网 www.16yun.cn)
proxyHost = "t.16yun.cn"
proxyPort = "31111"
# 代理隧道验证信息
proxyUser = "username"
proxyPass = "password"
proxyMeta = "http:// %(user)s : %(pass)s @ %(host)s : %(port)s " % {
"host" : proxyHost,
"port" : proxyPort,
"user" : proxyUser,
"pass" : proxyPass,
}
# 设置 http和https访问都是用HTTP代理
proxies = {
"http" : proxyMeta,
"https" : proxyMeta,
}
# 设置IP切换头
tunnel = random.randint( 1 , 10000 )
headers = { "Proxy-Tunnel" : str (tunnel)}
resp = requests.get(targetUrl, proxies=proxies, headers=headers)
print resp.status_code
print resp.text
然后就去运行,结果是这样
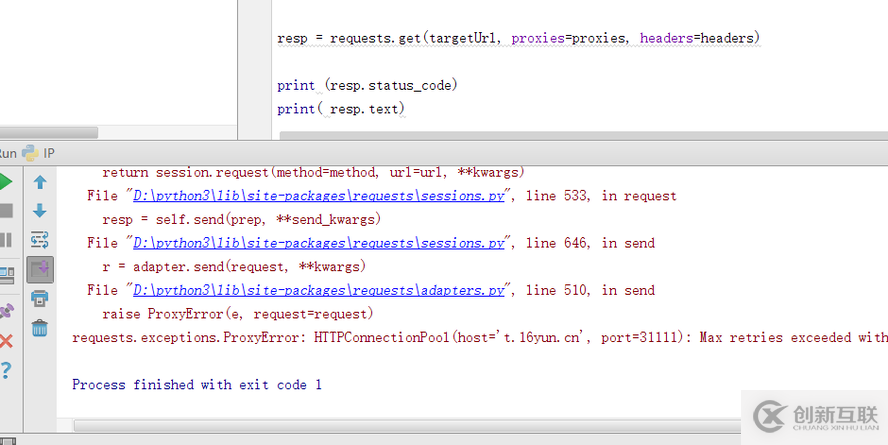
然后就去找客服,结果人家说那只是代码示例,里面的代理参数是需要他们提供重新配置才可以使用,顿时就觉得自己真的很小白,然后请客服开通了代理测试了下,结果运行起了,对我这样的小白来还好使用的方式简单,不然又要各种查资料了。我想很多人都是这样吧,刚开始的时候各种小白问题都有可能存在,看来不管是哪个领域,还是要深入的学习才好!
当前文章:新手使用python采集数据的尴尬事之代理ip-创新互联
分享链接:https://www.cdcxhl.com/article21/dodcjd.html
成都网站建设公司_创新互联,为您提供手机网站建设、品牌网站建设、网站收录、网页设计公司、建站公司、品牌网站制作
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 创新互联网站改版的重点是什么 2022-06-02
- 【网站优化】百度网站改版已成为必然,如何避免网站SEO优化受影响? 2021-09-30
- 网站改版专题:网站改版费用几何? 2023-02-25
- 网站改版怎么做才能减少网站排名影响? 2020-06-20
- 网站改版要注意什么呢? 2016-09-26
- 为什么在建设企业网站的时候要考虑到网站改版的问题? 2016-11-06
- 企业网站改版需要注意什么问题? 2016-10-12
- 如何通过seo技术解决网站改版出现的死链问题 2014-10-26
- 北京网站优化,网站改版之后如何恢复排名? 2021-04-13
- 企业网站改版该如何做优化处理? 2016-06-02
- 网站改版的常见误区与设计技巧 2017-03-06
- 集团公司网站建设方案 网站改版有哪些 2021-05-13