MySQL中如何分区已经存在大量数据的表
下文给大家带来有关MySQL中如何分区已经存在大量数据的表内容,相信大家一定看过类似的文章。我们给大家带来的有何不同呢?一起来看看正文部分吧,相信看完MySQL中如何分区已经存在大量数据的表你一定会有所收获。
创新互联公司主营企业营销型网站建设,为众多企业提供了品牌网站建设服务,建网站哪家好?拥有多年的全网整合营销推广流程,能够为企业定制化制作网站服务,在公司网站建设维护方面成绩突出。
环境:
数据库版本:5.6
系统环境:CentOS 6.8
复制架构:
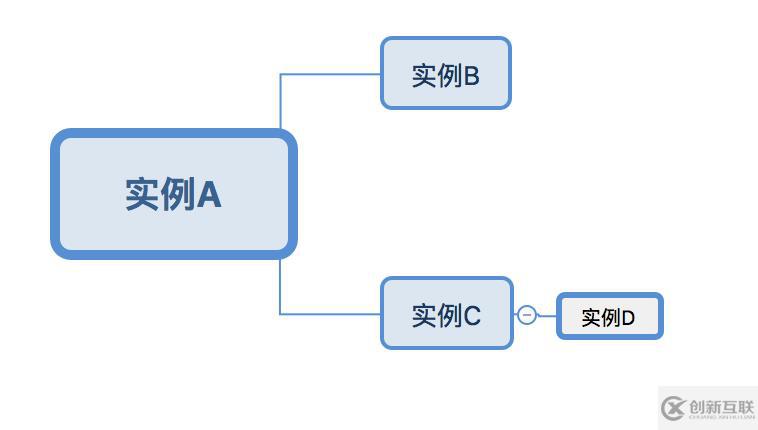
需求:
需要将实例C上面一个2500万行数据的Innodb引擎的表table进行分区,但是在实例A上面表table不做任何的修改。
思考的问题:
在实例C上面的表table做分区,分区之后会不会影响实例A和实例C之间表table的传输,会不会造成数据不一致或者插入失败,或者分区之后插入的数据会比较慢。
实际操作:都是在实例C上面的操作
1. stop slave IO_THREAD 停掉IO_THREAD并且等待实例C重放relay log完毕。
Master_Log_File == Relay_Master_Log_File and Read_Master_Log_Pos == Exec_Master_Log_Pos 当这俩个表达式成立的时候表明本地的relay log已经重做完毕。
2.逻辑备份表table的数据:
mysqldump -S /var/lib/mysql/mysql.sock -uroot -p --single-transaction --master-data=2 -t --skip-add-drop-table sbtest sbtest1 > sbtest1.sql 参数解释: -t:不创建table --skip-add-drop-table:不做drop table操作
在备份的时候不需要drop table 和 create table操作写入备份的SQL语句中
3.更改表名
更改旧表的表名 rename table sbtest1 to sbtest2; 这样做的目的是为了在做备份导入的时候不需要更改备份SQL语句,并且万一分区失败或者其他的原因至少也有表的备份存在。
4.创建空表并且进行分区:
CREATE TABLE `sbtest1` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `k` bigint(20) NOT NULL, `c` varchar(20) NOT NULL, `pad` varchar(50) COLLATE utf8mb4_bin NOT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin PARTITION BY KEY (id) PARTITIONS 64
新表的表结构要和旧表的表结构一致,唯一不同就是提前分好区。
5.导入逻辑备份语句
mysql -uroot -p sbtest < sbtest1.sql
6.导入完毕之后开启slave并且观察一段时间
start slave IO_THREAD
7.pt-table-checksum数据一致性检测(可做可不做)
http://seanlook.com/2015/12/29/mysql_replica_pt-table-checksum/
8.建议:
因为2500万行的数据的备份会花费比较长的时间,所以在备份的时候建议使用screen,那怕在你远程回话断开之后进程还是存在的。
对于上文关于MySQL中如何分区已经存在大量数据的表,大家觉得是自己想要的吗?如果想要了解更多相关,可以继续关注我们的行业资讯板块。
本文标题:MySQL中如何分区已经存在大量数据的表
浏览地址:https://www.cdcxhl.com/article20/ghopco.html
成都网站建设公司_创新互联,为您提供电子商务、域名注册、品牌网站设计、外贸建站、服务器托管、建站公司
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 同行网站同样做seo优化推广,为什么同行站点关键词排名较好? 2016-11-13
- 企业网站空间应注意哪些事项 2016-11-03
- 菏泽网络推广为什么网站优化排名需要高配处事器与空间的支持? 2023-01-08
- 成都提高企业转化应从建网站的哪些角度切入 2023-03-27
- 为什么网站有收录却没有排名 2021-08-04
- 企业外贸网站推广方法汇总 2022-06-20
- 找准适合做站外SEO的方法 2023-04-07
- 网页设计:装修公司如何进行网站建设 2023-10-20
- 从网络营销与网络"赢"销 2023-03-30
- 如何建造一个高端模板网站? 2022-07-12
- 服务器租用过程中网站被黑,怎么解决这种情况? 2023-12-08
- 定制化网站建设,满足您的特殊需求与功能要求 2023-11-16