hadoop1.xMapReduce工作原理-创新互联
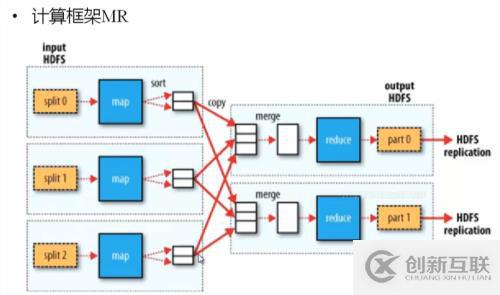

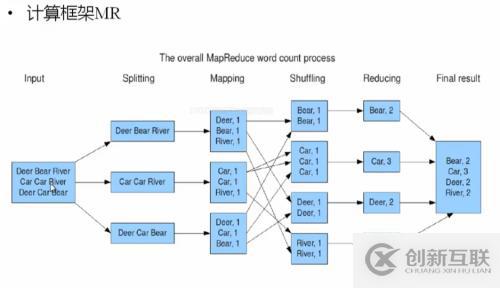

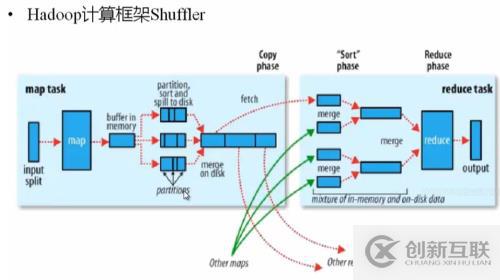
MapReduce 如何解决负载均衡和数据倾斜:
阶段主要出在Map作业结束后,shuffer(洗牌)过程中,如何将map处理后的结果分成多少份,交由Reduce作业,使得每部分reduce作业尽可能均衡处理数据计算。
系统默认将partitions 按照Hash模运算分割(存储对象的hash值与reduce的个数取模),这样很容易出现数据倾斜,导致其中一个reduce作业分得大量数据计算,另一个ruduce作业基本上没有任何数据处理。如何,解决的这种事情,就需要靠程序控制partitions的值
Sort:默认排序是按照字典排序的(按ASCII)
Shuffer阶段比较的操作要执行两次,一次是map task之后的sort另一次是在从本次磁盘将partition数据拷贝到指定reduce 之前的合并,将符合统一范围的key的数据归并


面试:
1.partition:将map输出的数据,按照某种规则将数据划分,分给哪一个reduce,默认使用hash模运算执行
2.spill:
过程:map的内存缓存区数据填满时,启动一个单独的线程,将数据按照一定比例写入本地磁盘。
Sort:将数据按照大小排序(可自定义)默认字典排序
Combiner:(可有可无)将相同的K_V中的value加起来,减少溢写磁盘的数据
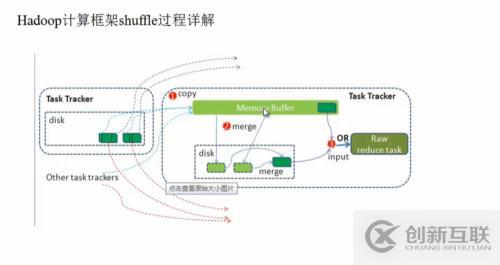
Shuffer的后半过程:
将map处理后放入map节点的本地磁盘的数据拷贝到rudece节点的内存中 去,数据量少的话,直接交由reduce处理。数据量大的时候,同样需要溢写到磁盘中,按照K值相同的方法进行merge,然后在交由指定的reduce执行

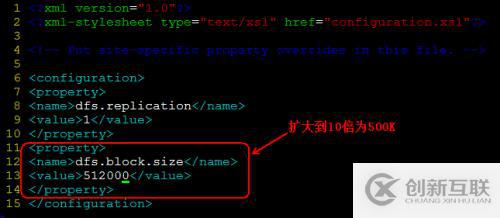
修改默认hdfs的block大小:
这个需要修改hdfs-site.conf配置文件,增加全局参数dfs.block.size。
如下:
修改后参数,
把配置同步到其它节点,并重启hdfs。

另外有需要云服务器可以了解下创新互联scvps.cn,海内外云服务器15元起步,三天无理由+7*72小时售后在线,公司持有idc许可证,提供“云服务器、裸金属服务器、高防服务器、香港服务器、美国服务器、虚拟主机、免备案服务器”等云主机租用服务以及企业上云的综合解决方案,具有“安全稳定、简单易用、服务可用性高、性价比高”等特点与优势,专为企业上云打造定制,能够满足用户丰富、多元化的应用场景需求。
本文题目:hadoop1.xMapReduce工作原理-创新互联
文章地址:https://www.cdcxhl.com/article20/dsjijo.html
成都网站建设公司_创新互联,为您提供自适应网站、全网营销推广、品牌网站制作、标签优化、网站维护、网站建设
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 手机网站建设这些小技巧要掌握 2023-02-21
- 手机端网站建设有什么规定 2013-12-19
- 成都婚庆类手机网站建设注意事项 2016-09-22
- 手机网站建设主要是优化哪些地方 2016-10-13
- 成都手机网站建设需要了解的问题 2017-11-01
- 广州手机网站建设需要多少钱呢? 2022-05-12
- 如何使用手机做好移动互联网营销 2016-11-16
- 手机网站建设给企业带来的优势 2022-12-31
- pc端与手机端在网站建设中的区别是什么? 2015-07-14
- 南充企业手机网站建设,您是否找到合适的网站建设公司? 2021-01-11
- 手机网站建设找创新互联,值得您信赖 2022-06-10
- 奉贤手机网站建设要满足哪些需求? 2020-12-18