6.824:Spanner详解-创新互联
Spanner能够在远地域数据分布的情况下,实现分布式事务。

首先是分布式事务,那么必然引入了二阶段提交的机制,同时为了避免二阶段提交机制中的短板,事务协调器崩溃导致参与者长时间阻塞占用锁的问题,spanner给事务协调器使用的paxos来提高可用性。但是,二阶段提交机制下的事务的处理性能存在巨大的问题,paper中提及到google的广告系统使用的数据库为参考,各种事务的占比中,只读型事务的数量有数十亿,而读写型事务却仅有数百万,关键在于提高只读型事务的性能。因此,spanner通过同步时钟来实现了只读事务的高效执行。
由于数据划分到多个服务器上进行分片,谷歌的数据中心遍布全球,自然这些服务器也遍布美国,每份数据都会在多个数据中心进行复制,这种冗余复制自然就是使用paxos来实现。为了让只读事务的高效处理,客户端每次向服务器请求数据时,都将选择距离自己最近的服务器请求,这有效降低地域距离带来的延迟,而非向leader请求,同时,这也使得冗余复制的那几个服务器将可以并行对只读事务处理,大大提高只读事务的性能,降低leader的负担。但是,数据的最新版本由leader同步给follower,存在少数replica的数据落后的情况,让客户端如读取当地的replica中的数据来提高速度的情况下,有可能客户端会读取到过时的数据。因此,需要外部一致性,确保每次读操作都能看到最新的数据。
简单来说,就是spanner针对占少数的读写型事务,侧重于避免事故带来的性能问题。spanner要求读写型事务通过二阶段提交来保证分布式上的原子提交,以及其中的二阶段锁也是确保了读写型事务间的隔离性,但是spanner用paxos解决了二阶段提交中的事务协调器崩溃阻塞的问题,后续将讲解如何引入paxos并进行结合。
spannere针对只读型事务,侧重于提高事务的执行性能,要求这些事务能够就近读取本地数据中心的数据,并要求这个过程是外部一致性的。后续将优化只读事务将其和二阶段提交机制解绑,其中的隔离性和外部一致性都通过引入快照隔离机制和安全时间机制来保证,同时快照隔离机制需要时钟的同步,时钟同步是难以保证的,这将引入start rule、commit wait机制来解决时钟同步的问题。
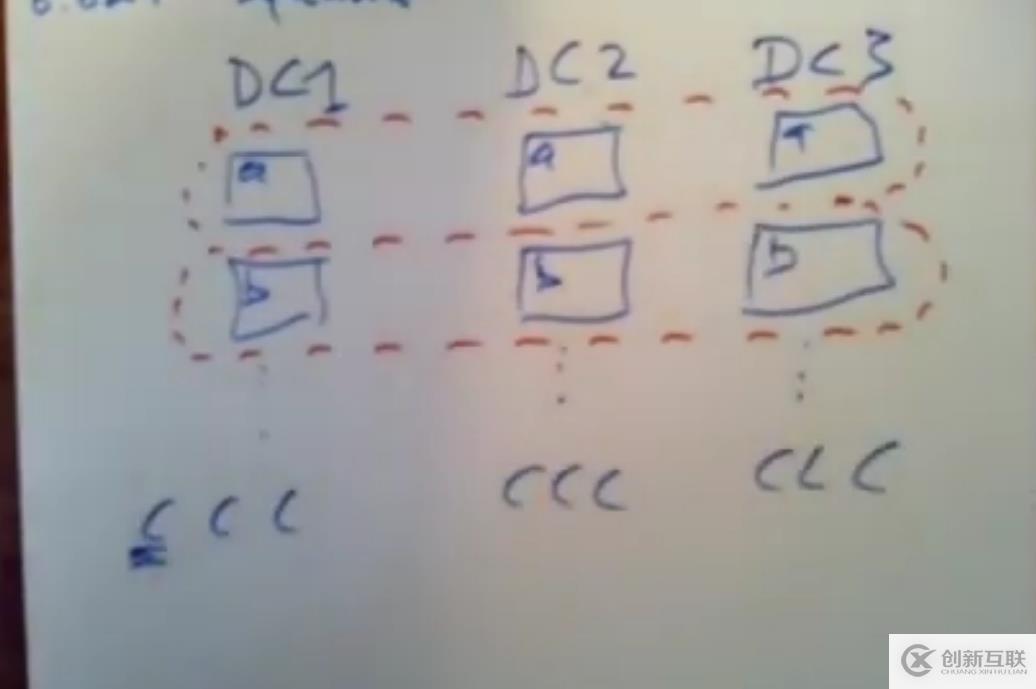
针对读写型事务的优化spanner使用场景下,数据被分片到不同服务器中,每份数据也通过paxos冗余复制到多台服务器上。下面通过一个例子来讲解:

一个读写型事务,一个银行的转账事务,账户Y转账给账户X一块钱,X账户的数据和Y账户的数据分别保存在不同的服务器上,但是这些数据都会经过复制到多台服务器上。
服务器2号为X数据所属分片的leader,服务器1号为Y数据所属分片的leader
这个转账事务的步骤为先读取x和y的值,后续再对x和y进行修改值
客户端先向leader发起一个DC2和DC1发起GET读取数据的请求,此时这两个leader也会分别对x和y数据上一个读锁
客户端后续在本地进行计算,得出更新的值,向DC2和DC1发起PUT更新数据的请求。由于需要进行原子性提交,因此需要事务协调器,客户端从与本事务相关的那些分片的leader中选择一台服务器作为事务协调器。被选中的服务器作为事务协调器,因为本身作为leader有follower进行复制数据,因此即使发生了崩溃,follower也会立刻顶替变为leader,同时也会接替事务协调器的工作。
本次客户端将DC1作为事务协调器,此时DC1不仅作为paxos中的一个leader,还作为当前事务的事务协调器,并将该paxos组的id发送出去。
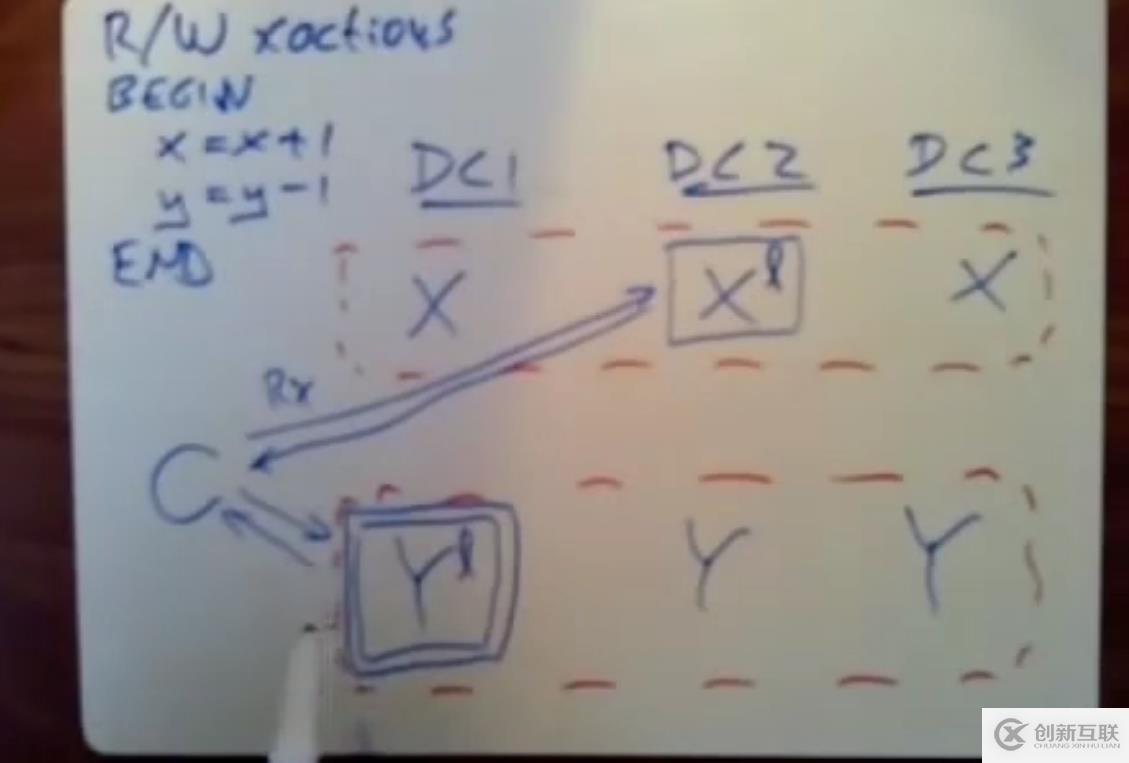
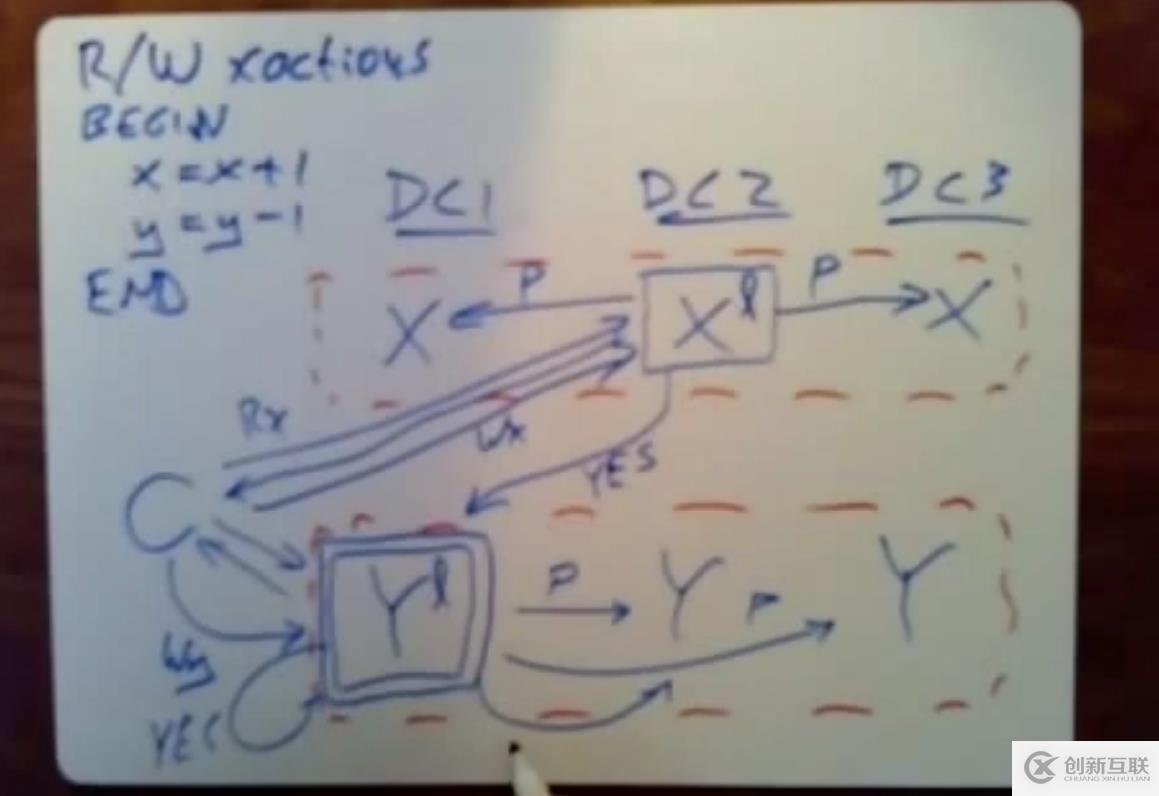
后续客户端将PUT请求,将更新的值发送给X和Y的leader
X和Y的leader接受到PUT请求后,就会立刻进行log replication,将prepare消息同步到日志中。当log replicaition到大多数节点后,leader即可确保该事务能够不受故障影响,确保被执行,便可回复yes给事务协调器,而DC1本身作为事务协调器,就是发送给自身一个yes回复。
此外客户端也会给DC1发送一个yes回复,因为DC1作为事务协调器。
当事务协调器收到了全部的yes回复后,即可进行commit该事务,但是事务协调器会先将该commit消息在本paxos组中进行log replication,后续再发送commit消息给其他参与者。我们需要确保事务协调器不会忘记它所做的决定。当这些commit消息被提交到了不同的shard paxos的日志中后,每个shard即可执行这些写操作,并将数据写入,并释放锁。
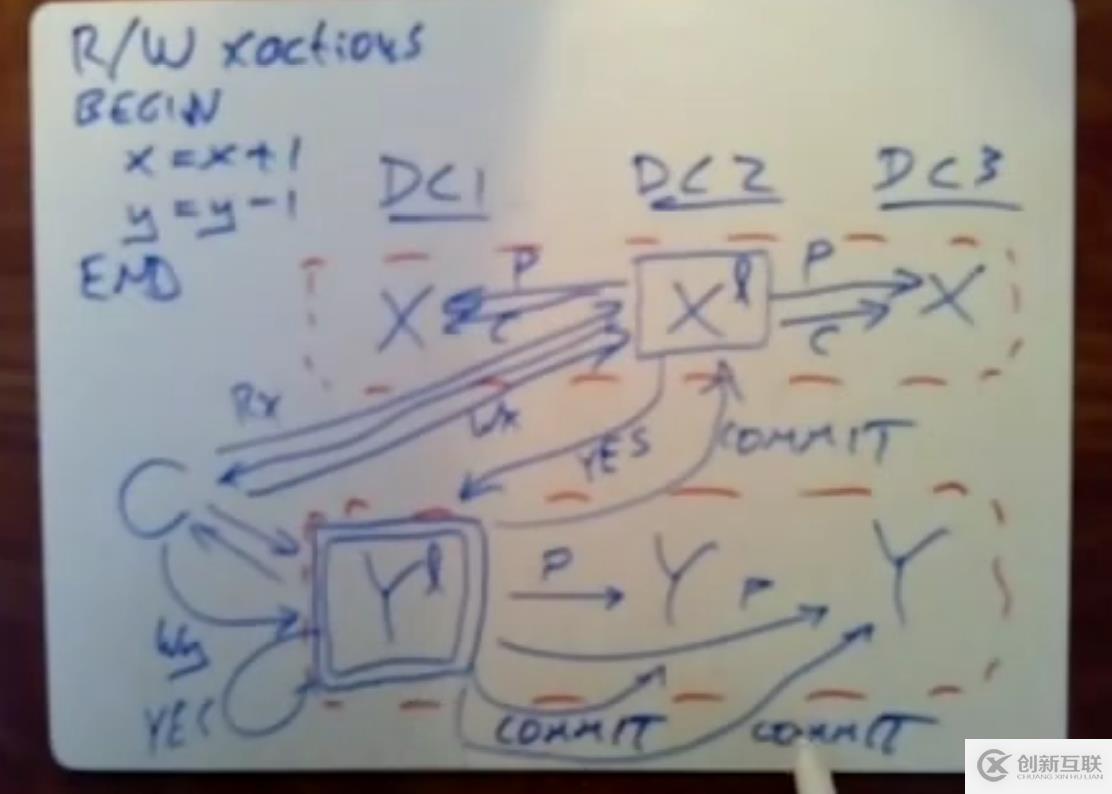
可以看到读写型事务涉及到大量的跨数据中心沟通,而谷歌的数据中心分布在全球各地,较远的数据中心的消息来往沟通会耗费大量的时间,因此这一个事务的执行开销一般就会比较大。但是数据被大量分片,因此只要事务之间没有数据冲突的存在,那么就可以并行执行大量的无冲突事务,这样也弥补了性能的问题,但是单个读写型事务的延迟还是没法解决的,因此一般来说spanner方案下,所有的replica一般也都是放在同个城市内或者是跨镇的,paper中也展示了邻近的数据中心完成事务的执行时间仅需14毫秒左右。这个性能凑活,但还是十分慢。
性能优化这块,spanner针对占据事务比例绝大多数的只读型事务进行了特别的优化,大大提高了处理速度。
针对只读型事务的优化spanner对只读型事务,消除了两个会带来巨大开销的问题。
1、消除了客户端和数据中心的远距离带来的通信延迟,spanner使得客户端仅需向本地数据中心读取数据即可;
2、只读事务执行过程中,无需使用二阶段提交机制和二阶段锁,从而避免了繁杂的跨数据中心的网络通信沟通,以及避免了占用锁对读写型事务造成处理速度上的影响。
从paper中的结果可以看到,这使得只读事务的延迟相比读写型事务快了10倍多。
由于只读事务并不会对数据进行修改,因此无需要求它和读写型事务一样遵守严格的有序性。
只读型事务的正确执行有两个约束:
1、只读型事务和读写型事务并行执行的执行结果必须是有序、线性一致性的,即执行的结果就和事务有序执行的结果一样,即只读型事务能够看到在该事务之前的读写型事务的结果,但不能看到后续读写型事务的结果。例如,一个只读型事务夹在两个读写型事务之间,这个只读事务应该能够看到第一个读写型事务的结果,但不应该看到第二读写型事务的执行结果,由于只读型事务并不会占据锁,因此有可能第二个读写型事务虽然开始比只读型事务慢,但是并行执行下,有可能第二个读写型事务反而先完成执行,此时,需要确保只读型事务读取不到第二个读写型事务的结果。
如图所示的情况下,T1和T2为读写型事务,T3为只读型事务,如果不采取措施,那么T3事务读取返回的结果为,x为T1事务修改的结果,而y为T2事务修改的结果,然而正确的返回结果应该读取T1事务修改的x、y值。

2、外部一致性,要求一个只读事务能够看到正确的最新版本的数据,需要避免只读事务看到的是过时的数据。
快照隔离(Snapshot Isolation)该机制建立在所有的机器都有一个同步的时钟的前提条件下,每个机器根据这个同步时钟给每个事务都分配了一个时间戳。
读写型事务的时间戳就是提交的时间,只读型事务的时间戳就是事务开始的时间
所有的事务的执行顺序应该严格按照这个时间戳的顺序来执行,因此,如果每台服务器能够按照遵守时间戳,并给出时间戳顺序的执行结果,那就是正确的。
每个replica在处理读写型事务时,进行数据保存时,都应该保存了该数据的多个版本,这个版本是以时间戳来标识。
因此,只读事务在进行处理时,即便碰到了上面图片的问题,T1事务提交时间假设为10,T3只读事务的开始时间假设为15,T2事务的提交时间为20,但是T3事务执行Ry操作的时间为21,在21这个时间,T3事务在读取y的数值时,看到有时间戳为10和20两个版本的结果,根据T3事务的时间戳为15,会读取时间戳为10的那个版本的数值并返回。
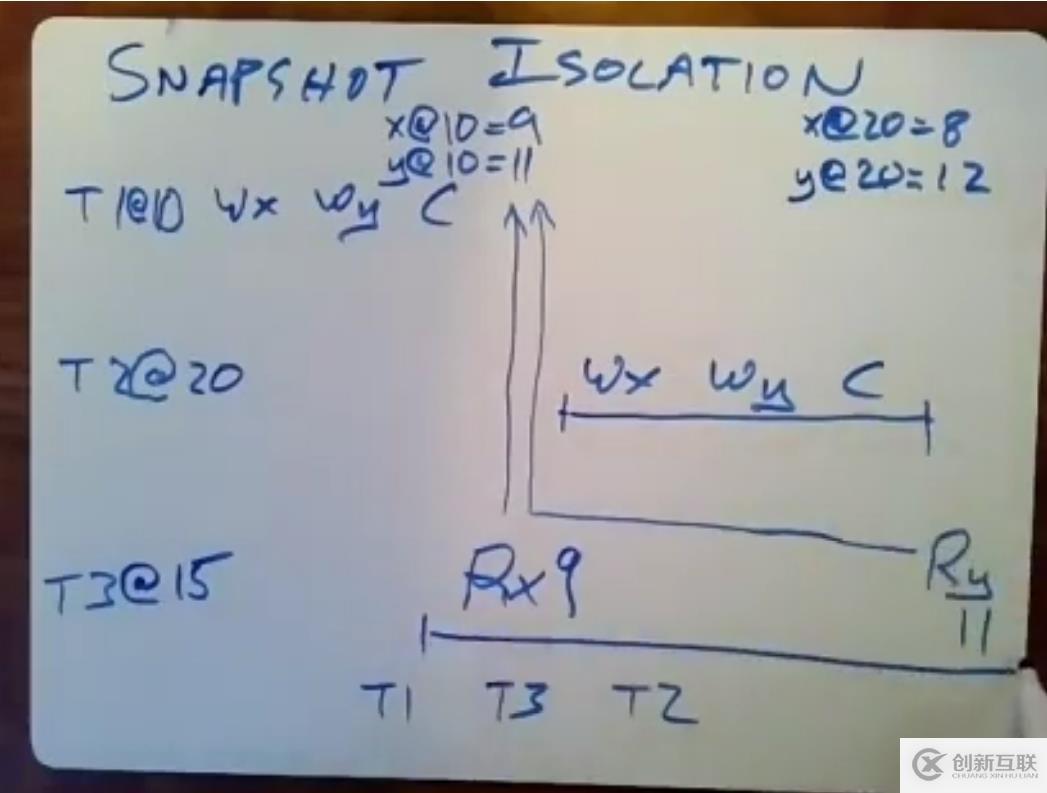
只读型事务被发起的时候,应该提前携带一个时间戳,此时这个只读事务执行的时候,应该去找在这个时间戳之前的最新的数据。
可见图中,事务的执行顺序为T1、T3、T2,但是T2和T3的事务是并发执行,在T3执行的时候甚至已经可以看到最新版本的数据,但是依旧返回旧的数据,这样是否合理呢?
合理的,因为两个事物的并发执行,那么数据库可以允许这两个事务以任意的顺序执行,只要是结果是有序执行的结果即可,要么返回T3、T2顺序的结果,要么返回T2、T3顺序的结果,但是Spanner的机制下,需要严格按照时间戳来执行,因此返回T3、T2顺序的执行结果。
可见,Spanner使用快照隔离能够成功解决了只读型事务在没有锁协调下,和读写型事务达成有序执行,但是还是无法实现外部一致性。
此外,快照隔离需要记录多个版本的数据,这会给磁盘和内存带来额外的开销,但是存储成本并不昂贵,同时这些多版本的数据,我们仅需保存近期的版本数据即可,超过一定时间范围的记录均可丢弃,因此这其实也不算是一个特别的问题。
安全时间(Safe Time)快照隔离机制能够保证事务的有序执行,但是还是无法解决外部一致性的问题,有可能发起的只读事务到达本地的replica时,这个replica处于落后状态,还没同步到最新的读写型事务的提交,那么这个只读事务无法读取到该事务时间戳前的最新版本的数据。
针对上面的问题,Spanner提出了安全时间机制,由于Leader会严格按照Log Index的顺序给follower进行log replication并进行提交,因此日志中的事务按照Index来看,时间戳也是严格递增的。follower收到时间戳为15的事务的提交,那么表明时间戳15之前的事务都已经接受完毕。
因此,当本地replica收到一个时间戳为15的只读型事务,但是本地只从leader处拿到了时间戳为13的事务的日志,那么本地的replica就会推迟回复这个只读事务,直到它从leader处拿到了时间戳大于或等于15的事务日志。当然这会带来一点小延迟。
时钟同步问题的解决在只读型事务的优化中,提出的快照隔离和安全时间机制发挥作用的前提都是所有机器的时钟都是同步的,但是在分布式系统中,想要实现所有机器的时钟完美同步是不可能的。
时间是由政府实验室里的那些价格昂贵的高精度时钟定义,我们只能从那儿获取时间,而获取这些时间的数值需要通过一定途径传输获取,但是这个数据传输的过程必然需要花费一定的时间,并且这个传输过程的延迟对于不同服务器也是不同的。
对于读写型事务而言,这类事务采用了二阶段锁和二阶段提交机制,根本无需时钟同步来解决什么问题。
因此,我们这里需要针对只读型事务来考虑,因为时间戳时为了优化只读型事务才引入的。
时钟不同步会发生的两种情况如果只读型事务碰到时钟不同步的情况会发生什么,我们需要设想以下两种情况。
1、时钟不同步导致只读型事务上携带的时间戳大于实际时间,那么replica收到这个只读事务后就会因为安全时间机制等待leader发来的事务的时间戳赶上这个只读事务的时间戳。这种情况看起来不算特别糟糕,顶多就是需要等待一段时间,但是返回的结果是正确的。但是如果只读型事务的时间戳偏差大到离谱的时候,那么就可能会发生等待超时的情况,当然服务器会定期获取高精度时间,不至于会有这么大的偏差。
2、时钟不同步导致只读型事务上携带的时间戳小于实际时间,此时就会违反正确性,因为本地的replica根据这个过小的时间戳会返回一个过时版本的数据,并且时钟不同步的偏差越大,只读事务的时间戳越小,那么返回的数据的版本就越老。这显然是违反了之前讲的外部一致性,因此,我们需要针对只读型事务被分配比真实时间要小的时间戳的情况下的外部一致性问题。
显然,如果时钟不完美同步的话,那么spanner的只读型事务将会发生错误。后续讲解为什么不能完美同步,以及如何解决这个问题。
时间是由政府的实验室中的高精度时钟来决定的,这个时间的数值的广播也是需要使用特定的协议,例如雷达协议(Spanner中GPS就是扮演雷达广播的角色,接受高精度时钟的正确时间然后通过GPS卫星发送给google机房中的GPS接收器),还有一些比较新的协议NTP协议(基于网络的一个时间协议)
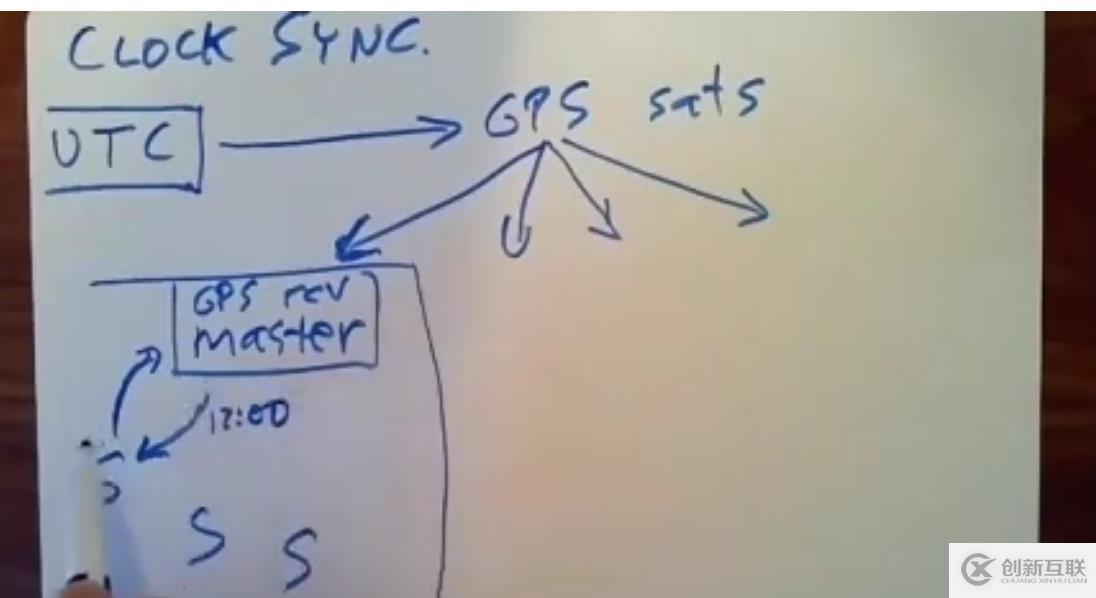
如图演示了服务器获取时间的原理图,UTC是指政府实验室中定义的高精度时间,政府实验室通过GPS卫星将时间进行广播给GPS接收器。每个数据中心都会有一个GPS接收器,它可以对GPS信号中的时间戳进行解密并修正各种传播延迟带来的偏差,让时间值保持是正确的,但是这个误差的修正显然不是绝对准确的,修正后的时间和真实的时间还是存在微小的偏差。这个GPS接收器会和数据中心中的time master进行连接,由于整个数据中心的时间戳都由这time master来决定,避免唯一故障点发生故障的严重事故,time master也将会有多个存在,提高可用性。
每个数据中心的数百台服务器,部分作为spanner server,部分作为spanner client,它们都会定期向这些time master获取正确的时间,这里spanner机器和time master的交互也会让引入新的时间误差,time master在获取时间值后回复给spanner机器,回复过程是存在延迟的,这个延迟相比上面的延迟是巨大的。因此,误差始终存在,始终是无法获取绝对精准的时间,这些误差都是毫秒级的,是十分严重的。
此外,spanner机器是每隔一定时间向time master获取正确的时间,但是间隔期间的时间值是通过本地时钟来计算时间,这种方式带来的结果也是十分糟糕,误差很大。
True Time方案因此,时间的不准确性是必然存在的,如果解决这个问题,Spanner使用了True Time方案。当机器向time master询问时间时,并不会返回一个时间值,而是返回一直TT区间的值,这个区间由一个earliest time和latest time组成,精准的时间必然处在这个TT区间内。
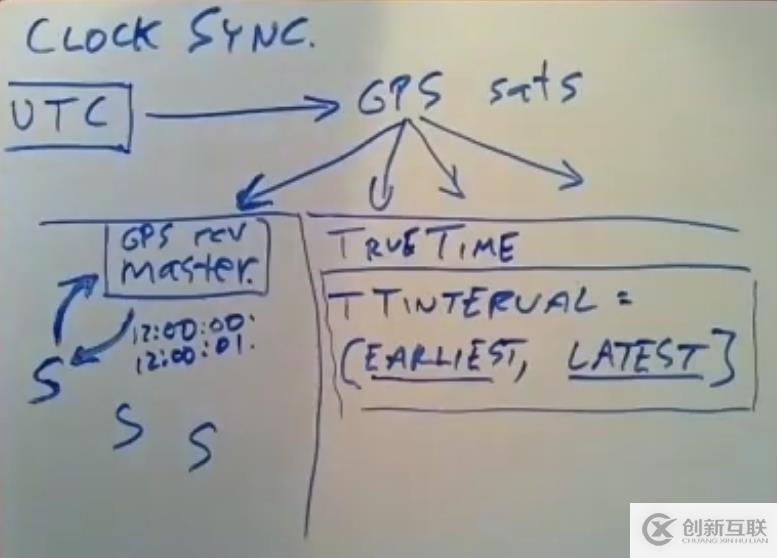
上面,我们提及到的只读型事务被分配偏小的时间戳导致外部一致性被破坏的问题,通过两条规则来解决了,分别为Start Rule和Commit Wait Rule。
Start Rule:为事务分配时间戳就是返回的TT区间中的latest time来赋值,用TT.now().latest赋值,这确保事务被赋值的时间戳是比真实的时间要大一些。对于只读型事务而言,时间戳应该在开始的时候就赋予;对于读写型事务而言,时间戳应该在提交的时候再赋予。
Commit Wait Rule:这个规则只针对于读写型事务,由于事务被分配的时间戳为TT区间中的latest,实际是要大于真实时间的,后续则需要等待真实时间大于这个时间戳后才能提交该读写型事务。这确保了读写型事务被提交的那个时间的数值是比被分配的时间戳要大。
后续的等待如何判断真实时间已经大于这个时间戳了
服务器仅需循环调用TT.now()获取真实时间的情况,当获取的TT区间的earliest time都大于这个时间戳了,表明真实时间必然已经大于这个时间戳了。
我们需要解决的情况是,只读型事务被分配了相对于真实时间较小的时间戳,导致了只读型事务读取到的数据是过时的。而只读型事务被分配相对于真实时间较大的时间戳的情况,仅需等待一段时间,仍然会返回新版本的数据。因此,我们需要避免只读型事务被分配较小的时间戳。
Start Rule确保每个事务被分配的时间戳相对于真实时间都是偏大的,这确保只读型事务被分配了较大的时间戳。
但是Start Rule也使得读写型事务也被分配了较大的时间戳,因此Commit Wait Rule发挥了作用,它使得读写型事务即使被分配了时间戳也不能提交,需要等待一段时间,确保真实时间大于这个时间戳后再提交,这使得读写型事务的时间戳是小于提交时的真实时间,实际上是被分配了一个相对于真实时间较小的值。
读写型事务被分配相对于真实时间较小的时间戳,只读型事务被分配相对于真实时间较大的时间戳,那么就只会发生时钟不同步会发生的两种情况章节中的第一种情况,那种情况基本就是会导致只读型事务需要因为安全时间机制进行等待,但是只读型事务读取到的数值绝对是最新版本,正确的。
总结Spanner能够使得在世界范围内分布的数据中心实现了分布式事务的操作,并且性能也是可以忍受的,这真的十分神奇,而这神奇之处的关键就在于文章中的快照隔离和时间戳机制了。
你是否还在寻找稳定的海外服务器提供商?创新互联www.cdcxhl.cn海外机房具备T级流量清洗系统配攻击溯源,准确流量调度确保服务器高可用性,企业级服务器适合批量采购,新人活动首月15元起,快前往官网查看详情吧
名称栏目:6.824:Spanner详解-创新互联
文章源于:https://www.cdcxhl.com/article20/dshjjo.html
成都网站建设公司_创新互联,为您提供网站收录、动态网站、App设计、企业建站、商城网站、网站导航
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 网站改版也给网站带来很多致命伤,那么究竟是哪些致命伤,作为站长我们该如何规避呢? 2021-07-05
- 制定网站改版计划需要考虑的因素 2016-05-30
- 网站改版不降权的注意事项! 2023-05-04
- 浅析网站改版时需要遵循五个原则 2016-10-28
- 浅谈证券期货业纠纷调解中心网站改版的见解 2023-03-24
- 在成都网站改版要多少钱呢 2016-09-06
- 一般的企业网站改版哪些功能可以升级换代 2014-07-16
- 广州网站建设公司总述网站什么时候需要网站改版 2015-12-30
- 浅谈万仪科技网站改版的见解 2023-02-09
- 六年个人网站改版干货血泪总结 2022-11-21
- 企业网站改版制作需要多少钱? 2017-09-05
- 网站改版升级运营的建议 2022-12-20