百万级高并发mongodb集群性能数十倍提升优化实践-创新互联
背景
线上某集群峰值TPS超过100万/秒左右(主要为写流量,读流量很低),峰值tps几乎已经到达集群上限,同时平均时延也超过100ms,随着读写流量的进一步增加,时延抖动严重影响业务可用性。该集群采用mongodb天然的分片模式架构,数据均衡的分布于各个分片中,添加片键启用分片功能后实现完美的负载均衡。集群每个节点流量监控如下图所示:
创新互联坚持“要么做到,要么别承诺”的工作理念,服务领域包括:成都网站设计、网站建设、企业官网、英文网站、手机端网站、网站推广等服务,满足客户于互联网时代的诸暨网站设计、移动媒体设计的需求,帮助企业找到有效的互联网解决方案。努力成为您成熟可靠的网络建设合作伙伴!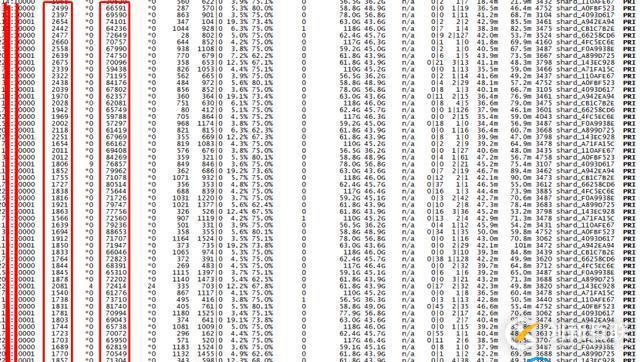
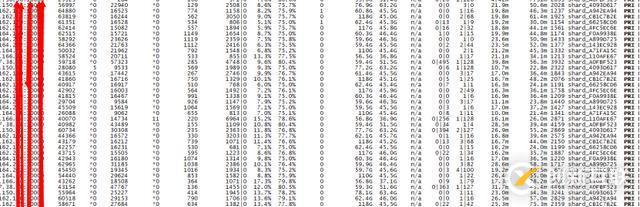
从上图可以看出集群流量比较大,峰值已经突破120万/秒,其中delete过期删除的流量不算在总流量里面(delete由主触发删除,但是主上面不会显示,只会在从节点拉取oplog的时候显示)。如果算上主节点的delete流量,总tps超过150万/秒。
软件优化
在不增加服务器资源的情况下,首先做了如下软件层面的优化,并取得了理想的数倍性能提升:
业务层面优化
Mongodb配置优化
存储引擎优化
2.1 业务层面优化
该集群总文档近百亿条,每条文档记录默认保存三天,业务随机散列数据到三天后任意时间点随机过期淘汰。由于文档数目很多,白天平峰监控可以发现从节点经常有大量delete操作,甚至部分时间点delete删除操作数已经超过了业务方读写流量,因此考虑把delete过期操作放入夜间进行,过期索引添加方法如下:
Db.collection.createIndex( { "expireAt": 1 }, { expireAfterSeconds: 0 } )
上面的过期索引中expireAfterSeconds=0,代表collection集合中的文档的过期时间点在expireAt时间点过期,例如:
db.collection.insert( {
//表示该文档在夜间凌晨1点这个时间点将会被过期删除
"expireAt": new Date('July 22, 2019 01:00:00'),
"logEvent": 2,
"logMessage": "Success!"
} )
通过随机散列expireAt在三天后的凌晨任意时间点,即可规避白天高峰期触发过期索引引入的集群大量delete,从而降低了高峰期集群负载,最终减少业务平均时延及抖动。
Delete过期Tips1: expireAfterSeconds含义
1. 在expireAt指定的绝对时间点过期,也就是12.22日凌晨2:01过期
Db.collection.createIndex( { "expireAt": 1 }, { expireAfterSeconds: 0 } )
db.log_events.insert( { "expireAt": new Date(Dec 22, 2019 02:01:00'),"logEvent": 2,"logMessage": "Success!"})
在expireAt指定的时间往后推迟expireAfterSeconds秒过期,也就是当前时间往后推迟60秒过期
db.log_events.insert( {"createdAt": new Date(),"logEvent": 2,"logMessage": "Success!"} )
Db.collection.createIndex( { "expireAt": 1 }, { expireAfterSeconds: 60 } )
Delete过期Tips2: 为何mongostat只能监控到从节点有delete操作,主节点没有?
原因是过期索引只在master主节点触发,触发后主节点会直接删除调用对应wiredtiger存储引擎接口做删除操作,不会走正常的客户端链接处理流程,因此主节点上看不到delete统计。
主节点过期delete后会生存对于的delete oplog信息,从节点通过拉取主节点oplog然后模拟对于client回放,这样就保证了主数据删除的同时从数据也得以删除,保证数据最终一致性。从节点模拟client回放过程将会走正常的client链接过程,因此会记录delete count统计,详见如下代码:
官方参考如下: https://docs.mongodb.com/manual/tutorial/expire-data/
2.2 Mongodb配置优化(网络IO复用,网络IO和磁盘IO做分离)
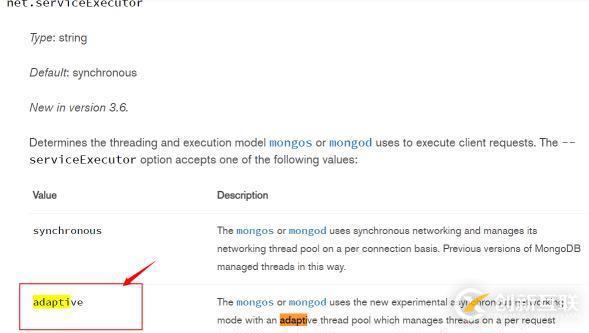
由于集群tps高,同时整点有大量推送,因此整点并发会更高,mongodb默认的一个请求一个线程这种模式将会严重影响系统负载,该默认配置不适合高并发的读写应用场景。官方介绍如下:
2.2.1 Mongodb内部网络线程模型实现原理
mongodb默认网络模型架构是一个客户端链接,mongodb会创建一个线程处理该链接fd的所有读写请求及磁盘IO操作。
Mongodb默认网络线程模型不适合高并发读写原因如下:
1. 在高并发的情况下,瞬间就会创建大量的线程,例如线上的这个集群,连接数会瞬间增加到1万左右,也就是操作系统需要瞬间创建1万个线程,这样系统load负载就会很高。
2. 此外,当链接请求处理完,进入流量低峰期的时候,客户端连接池回收链接,这时候mongodb服务端就需要销毁线程,这样进一步加剧了系统负载,同时进一步增加了数据库的抖动,特别是在PHP这种短链接业务中更加明显,频繁的创建线程销毁线程造成系统高负债。
3. 一个链接一个线程,该线程除了负责网络收发外,还负责写数据到存储引擎,整个网络I/O处理和磁盘I/O处理都由同一个线程负责,本身架构设计就是一个缺陷。
2.2.2 网络线程模型优化方法
为了适应高并发的读写场景,mongodb-3.6开始引入serviceExecutor: adaptive配置,该配置根据请求数动态调整网络线程数,并尽量做到网络IO复用来降低线程创建消耗引起的系统高负载问题。此外,加上serviceExecutor: adaptive配置后,借助boost:asio网络模块实现网络IO复用,同时实现网络IO和磁盘IO分离。这样高并发情况下,通过网络链接IO复用和mongodb的锁操作来控制磁盘IO访问线程数,最终降低了大量线程创建和消耗带来的高系统负载,最终通过该方式提升高并发读写性能。
2.2.3 网络线程模型优化前后性能对比
在该大流量集群中增加serviceExecutor: adaptive配置实现网络IO复用及网络IO与磁盘IO做分离后,该大流量集群时延大幅度降低,同时系统负载和慢日志也减少很多,具体如下:
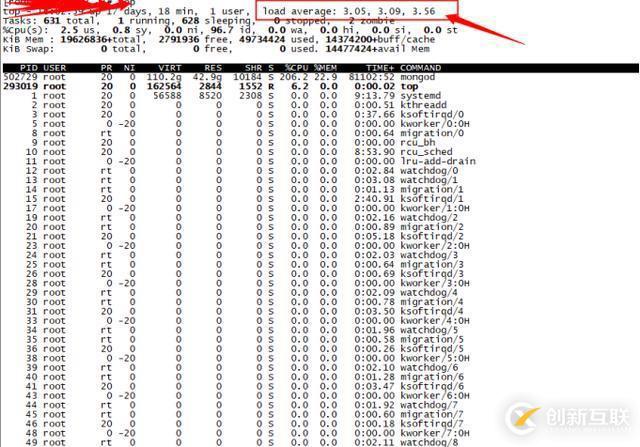
2.2.3.1 优化前后系统负载对比
验证方式:
该集群有多个分片,其中一个分片配置优化后的主节点和同一时刻未优化配置的主节点load负载比较:
未优化配置的load
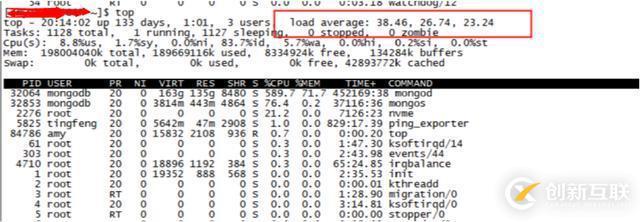
优化配置的load
2.2.3.2 优化前后慢日志对比
验证方式:
该集群有多个分片,其中一个分片配置优化后的主节点和同一时刻未优化配置的主节点慢日志数比较:
同一时间的慢日志数统计:
未优化配置的慢日志数(19621):

优化配置后的慢日志数(5222):

2.2.3.3 优化前后平均时延对比
验证方式:
该集群所有节点加上网络IO复用配置后与默认配置的平均时延对比如下:

从上图可以看出,网络IO复用后时延降低了1-2倍。
2.3 wiredtiger存储引擎优化
从上一节可以看出平均时延从200ms降低到了平均80ms左右,很显然平均时延还是很高,如何进一步提升性能降低时延?继续分析集群,我们发现磁盘IO一会儿为0,一会儿持续性100%,并且有跌0现象,现象如下:

从图中可以看出,I/O写入一次性到2G,后面几秒钟内I/O会持续性阻塞,读写I/O完全跌0,avgqu-sz、awit巨大,util次序性100%,在这个I/O跌0的过程中,业务方反应的TPS同时跌0。
此外,在大量写入IO后很长一段时间util又持续为0%,现象如下:
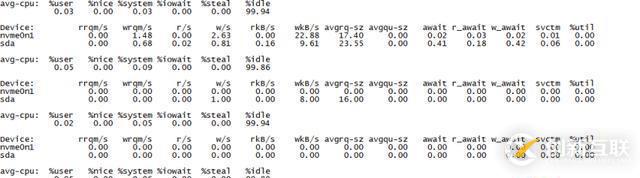
总体IO负载曲线如下:

从图中可以看出IO很长一段时间持续为0%,然后又飙涨到100%持续很长时间,当IO util达到100%后,分析日志发现又大量满日志,同时mongostat监控流量发现如下现象:
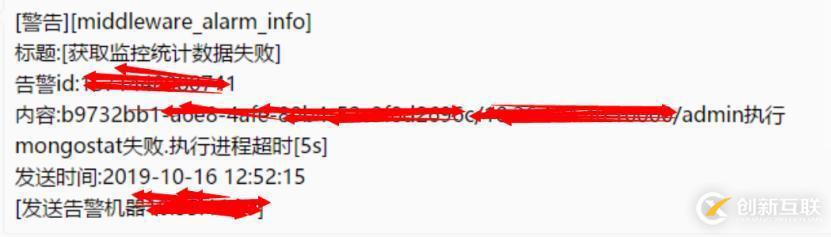
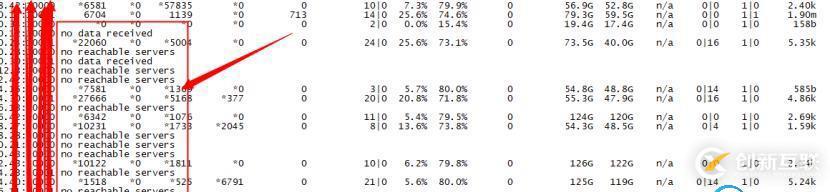
从上可以看出我们定时通过mongostat获取某个节点的状态的时候,经常超时,超时的时候刚好是io util=100%的时候,这时候IO跟不上客户端写入速度造成阻塞。
有了以上现象,我们可以确定问题是由于IO跟不上客户端写入速度引起,第2章我们已经做了mongodb服务层的优化,现在我们开始着手wiredtiger存储引擎层面的优化,主要通过以下几个方面:
cachesize调整
脏数据淘汰比例调整
checkpoint优化
2.3.1 cachesize调整优化(为何cacheSize越大性能越差)
前面的IO分析可以看出,超时时间点和I/O阻塞跌0的时间点一致,因此如何解决I/O跌0成为了解决改问题的关键所在。
找个集群平峰期(总tps50万/s)查看当时该节点的TPS,发现TPS不是很高,单个分片也就3-4万左右,为何会有大量的刷盘,瞬间能够达到10G/S,造成IO util持续性跌0(因为IO跟不上写入速度)。继续分析wiredtiger存储引擎刷盘实现原理,wiredtiger存储引擎是一种B+树存储引擎,mongodb文档首先转换为KV写入wiredtiger,在写入过程中,内存会越来越大,当内存中脏数据和内存总占用率达到一定比例,就开始刷盘。同时当达到checkpoint限制也会触发刷盘操作,查看任意一个mongod节点进程状态,发现消耗的内存过多,达到110G,如下图所示:
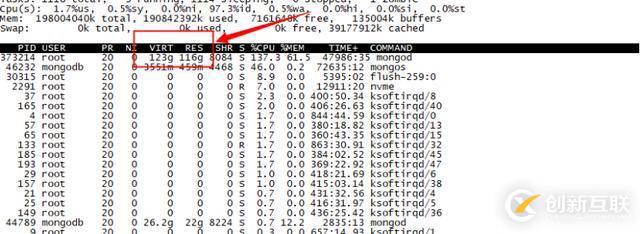
于是查看mongod.conf配置文件,发现配置文件中配置的cacheSizeGB: 110G,可以看出,存储引擎中KV总量几乎已经达到110G,按照5%脏页开始刷盘的比例,峰值情况下cachesSize设置得越大,里面得脏数据就会越多,而磁盘IO能力跟不上脏数据得产生速度,这种情况很可能就是造成磁盘I/O瓶颈写满,并引起I/O跌0的原因。
此外,查看该机器的内存,可以看到内存总大小为190G,其中已经使用110G左右,几乎是mongod的存储引起占用,这样会造成内核态的page cache减少,大量写入的时候内核cache不足就会引起磁盘缺页中断,引起大量的写盘。

解决办法:通过上面的分析问题可能是大量写入的场景,脏数据太多容易造成一次性大量I/O写入,于是我们可以考虑把存储引起cacheSize调小到50G,来减少同一时刻I/O写入的量,从而规避峰值情况下一次性大量写入的磁盘I/O打满阻塞问题。
2.3.2 存储引擎dirty脏数据淘汰优化
调整cachesize大小解决了5s请求超时问题,对应告警也消失了,但是问题还是存在,5S超时消失了,1s超时问题还是偶尔会出现。
因此如何在调整cacheSize的情况下进一步规避I/O大量写的问题成为了问题解决的关键,进一步分析存储引擎原理,如何解决内存和I/O的平衡关系成为了问题解决的关键,mongodb默认存储因为wiredtiger的cache淘汰策略相关的几个配置如下:

调整cacheSize从120G到50G后,如果脏数据比例达到5%,则极端情况下如果淘汰速度跟不上客户端写入速度,这样还是容易引起I/O瓶颈,最终造成阻塞。
解决办法: 如何进一步减少持续性I/O写入,也就是如何平衡cache内存和磁盘I/O的关系成为问题关键所在。从上表中可以看出,如果脏数据及总内占用存达到一定比例,后台线程开始选择page进行淘汰写盘,如果脏数据及内存占用比例进一步增加,那么用户线程就会开始做page淘汰,这是个非常危险的阻塞过程,造成用户请求验证阻塞。平衡cache和I/O的方法: 调整淘汰策略,让后台线程尽早淘汰数据,避免大量刷盘,同时降低用户线程阀值,避免用户线程进行page淘汰引起阻塞。优化调整存储引起配置如下:
eviction_target: 75%
eviction_trigger:97%
eviction_dirty_target: %3
eviction_dirty_trigger:25%
evict.threads_min:8
evict.threads_min:12
总体思想是让后台evict尽量早点淘汰脏页page到磁盘,同时调整evict淘汰线程数来加快脏数据淘汰,调整后mongostat及客户端超时现象进一步缓解。
2.3.3 存储引擎checkpoint优化调整
存储引擎得checkpoint检测点,实际上就是做快照,把当前存储引擎的脏数据全部记录到磁盘。触发checkpoint的条件默认又两个,触发条件如下:
固定周期做一次checkpoint快照,默认60s
增量的redo log(也就是journal日志)达到2G
当journal日志达到2G或者redo log没有达到2G并且距离上一次时间间隔达到60s,wiredtiger将会触发checkpoint,如果在两次checkpoint的时间间隔类evict淘汰线程淘汰的dirty page越少,那么积压的脏数据就会越多,也就是checkpoint的时候脏数据就会越多,造成checkpoint的时候大量的IO写盘操作。如果我们把checkpoint的周期缩短,那么两个checkpoint期间的脏数据相应的也就会减少,磁盘IO 100%持续的时间也就会缩短。
checkpoint调整后的值如下:
checkpoint=(wait=25,log_size=1GB)
2.3.4 存储引擎优化前后IO对比
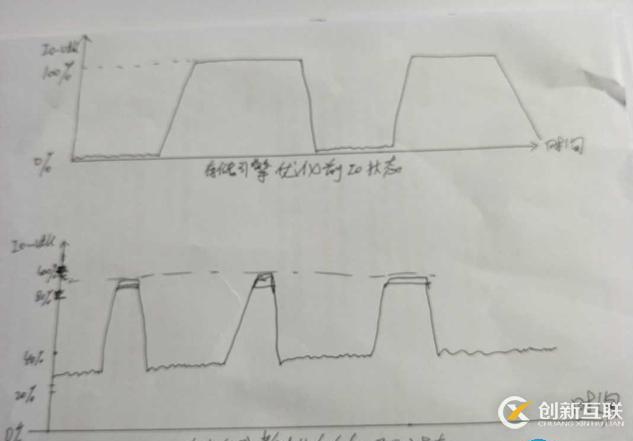
通过上面三个方面的存储引擎优化后,磁盘IO开始平均到各个不同的时间点,iostat监控优化后的IO负载如下:

从上面的io负载图可以看出,之前的IO一会儿为0%,一会儿100%现象有所缓解,总结如下图所示:
2.3.5 存储引擎优化前后时延对比
优化前后时延对比如下(注: 该集群有几个业务同时使用,优化前后时延对比如下):




从上图可以看出,存储引擎优化后时间延迟进一步降低并趋于平稳,从平均80ms到平均20ms左右,但是还是不完美,有抖动。
3 服务器系统磁盘IO问题解决
3.1 服务器IO硬件问题背景
如第3节所述,当wiredtiger大量淘汰数据后,发现只要每秒磁盘写入量超过500M/s,接下来的几秒钟内util就会持续100%,w/s几乎跌0,于是开始怀疑磁盘硬件存在缺陷。


从上图可以看出磁盘为nvMe的ssd盘,查看相关数据可以看出该盘IO性能很好,支持每秒2G写入,iops能达到2.5W/S,而我们线上的盘只能每秒写入最多500M。
3.2 服务器IO硬件问题解决后性能对比
于是考虑把该分片集群的主节点全部迁移到另一款服务器,该服务器也是ssd盘,io性能达到2G/s写入(注意:只迁移了主节点,从节点还是在之前的IO-500M/s的服务器)。 迁移完成后,发现性能得到了进一步提升,时延迟降低到2-4ms/s,三个不同业务层面看到的时延监控如下图所示:



从上图时延可以看出,迁移主节点到IO能力更好的机器后,时延进一步降低到平均2-4ms。
虽然时延降低到了平均2-4ms,但是还是有很多几十ms的尖刺,鉴于篇幅将在下一期分享大家原因,最终保存所有时延控制在5ms以内,并消除几十ms的尖刺。
此外,nvme的ssd io瓶颈问题原因,经过和厂商确认分析,最终定位到是linux内核版本不匹配引起,如果大家nvme ssd盘有同样问题,记得升级linux版本到3.10.0-957.27.2.el7.x86_64版本,升级后nvme ssd的IO能力达到2G/s以上写入。
4 总结及遗留问题
通过mongodb服务层配置优化、存储引擎优化、硬件IO提升三方面的优化后,该大流量写入集群的平均时延从之前的平均数百ms降低到了平均2-4ms,整体性能提升数十倍,效果明显。
但是,从4.2章节优化后的时延可以看出,集群偶尔还是会有抖动,鉴于篇幅,下期会分享如果消除4.2章节中的时延抖动,最终保持时间完全延迟控制在2-4ms,并且无任何超过10ms的抖动,敬请期待,下篇会更加精彩。
此外,在集群优化过程中采了一些坑,下期会继续分析大流量集群采坑记。
创新互联www.cdcxhl.cn,专业提供香港、美国云服务器,动态BGP最优骨干路由自动选择,持续稳定高效的网络助力业务部署。公司持有工信部办法的idc、isp许可证, 机房独有T级流量清洗系统配攻击溯源,准确进行流量调度,确保服务器高可用性。佳节活动现已开启,新人活动云服务器买多久送多久。
当前名称:百万级高并发mongodb集群性能数十倍提升优化实践-创新互联
文章路径:https://www.cdcxhl.com/article20/cspsjo.html
成都网站建设公司_创新互联,为您提供定制开发、域名注册、微信公众号、网站营销、网站内链、营销型网站建设
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- APP开发过程中用户体验设计需考虑的9大原则 2023-03-04
- 移动应用APP设计的关键:原型设计 2016-08-24
- UI不得不知的app设计布局之道 2022-11-21
- 品牌设计的植入-APP设计5 2022-05-30
- app设计技巧:国外大师教你四步设计框架 2022-05-29
- 小程序的设计,和App设计一样吗? 2022-08-31
- APP设计的五大特性! 2022-11-15
- APP设计常见分割方式 2021-05-20
- 登录框对于互联网APP设计而言是必不可少的 2017-01-23
- 电商APP设计时有哪些问题要注意 2016-11-05
- 24个容易忽略的APP设计细节 2022-05-14
- 毁掉APP设计的5个致命错误 2022-05-14