如何在Kubernetes容器环境下部署Spinnaker?-创新互联
如果你关注Docker,想了解基于Kubernetes的CD实践。那么,Spinnaker可能是多云平台部署工具的最佳选择。本文重点介绍spinnaker的概念、安装与踩过的坑,spinnaker在kubernetes的持续部署,以及线上容器服务的选择与多区容灾。
1、关于Spinnaker
Spinnaker 是什么?我们先来了解下它的概念。
Spinnaker 是 Netflix 的开源项目,是一个持续交付平台,它定位于将产品快速且持续的部署到多种云平台上。Spinnaker 有两个核心的功能集群管理和部署管理。Spinnaker 通过将发布和各个云平台解耦,来将部署流程流水线化,从而降低平台迁移或多云品台部署应用的复杂度,它本身内部支持 Google、AWS EC2、Microsoft Azure、Kubernetes和 OpenStack 等云平台,并且它可以无缝集成其他持续集成(CI)流程,如 git、Jenkins、Travis CI、Docker registry、cron 调度器等。
spinnaker主要用于展示与管理你的云端资源。涉及Applications, clusters, and server groups等,并
通过Load balancers and firewalls 将服务展示给用户。
官方结构如下:
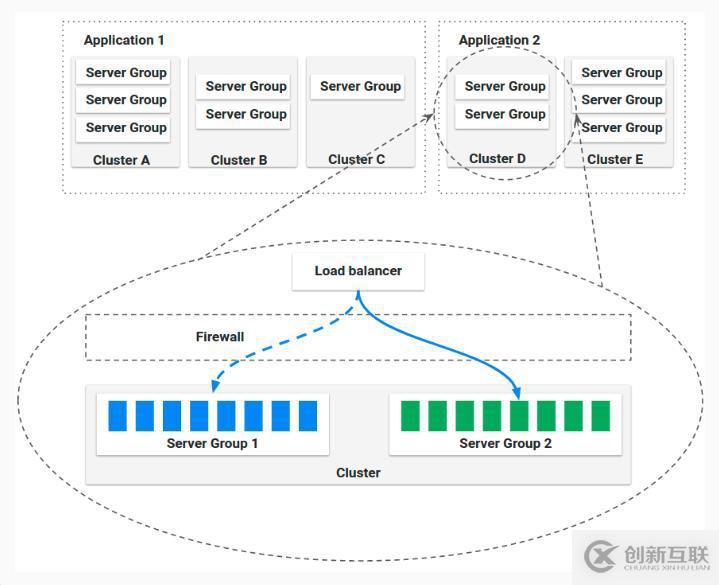
Application
定义了集群中一组的cluster的集合,也包括了firewalls 与 load balancers,存储了服务所有的部署相关的的信息。
Server Group
定义了一些基础的源比如(VM image, Docker image),以及一些基础的配置信息,一旦部署后,在容器中对应Kubernetes pods的集合。
Cluster
Server Groups的有关联的集合。(Cluster中可以按照dev,prod的去创建不同的服务组),也可以理解为对于一个应用存在多个分支的情况。
Load Balancer
他在实例之间做负载均衡流量。您还可以为负载均衡器启用健康检查,灵活地定义健康标准并指定健康检查端点,有点类似于kubernetes中ingress。
Firewall
防火墙定义了网络流量访问,定义了一些访问的规则,如安全组等等。
页面展示如下,还是比较精简的,可以在它的操作页面上看到项目以及应用的详细信息,还可以进行集群的伸缩,回滚,修改以及删除的操作。
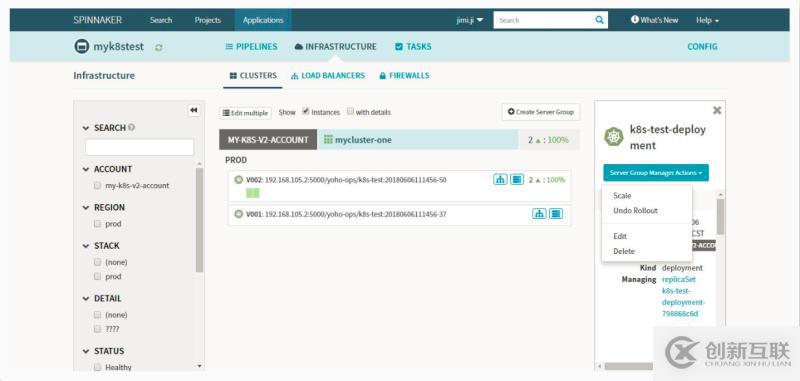
2、spinnaker的部署管理功能
上图中,infrastructure左侧为PIPELINE的设计:主要讲两块内容:pipeline的创建,与部署的策略。
Pipeline
1)、较强的 Pipeline 的能力:它的 Pipeline 可以复杂到无以复加,它还有很强的表达式功能(后续的操作中前面的参数均通过表达式获取)。
2)、触发的方式:定时任务,人工触发,jenkinsjob,docker images,或者其他的pipeline的步骤。
3)、通知方式:email, SMS or HipChat.
4)、将所有的操作都融合到pipeline中,比如回滚、金丝雀分析、关联CI等等。
3、spinnaker安装踩过的坑
很多人都是感觉这个很难安装,其实主要的原因还是墙的问题,只要把这个解决了就会方便很多,官方的文档写的很详细,而且spinnaker的社区也非常的活跃,有问题均可以在上面进行提问。
安装提供的方式:
1)、Halyard安装方式(官方推荐安装方式)
>>我采用Halyard安装方式,因为后期我们会集成很多其他的插件,类似于gitlab,ldap,kayenta,甚至多个jenkins,kubernetes服务等等,可配置性较强
2)、Helm搭建Spinnaker平台
3)、Development版本安装
>>helm方式若是需要自定义一些个性化的内容会比较复杂,完全依赖于原始镜像,而Development需要对spinnaker非常的熟悉,以及每个版本之间的对应关系均要了解。
Halyard方式安装注意点:
Halyard代理的配置
```
vim /opt/halyard/bin/halyard
DEFAULT_JVM_OPTS='S='-Dhttp.proxyHoxyHost=st=192.168.102.10 -Dh 10 -Dhttps.proxyPoxyPort=3128'
```
部署机器配置
由于spinnaker涉及的应用较多,下面会单独的介绍,需要消耗比较大的内存,官方推荐的配置如下:
```
18 GB of RAM
A 4 core CPU
Ubuntu 14.04, 16.04 or 18.0
```
4、spinnaker安装步骤
1)、Halyard下载以及安装
2)、选择云提供者:我选择的是Kubernetes Provider V2 (Manifest Based),需要在部署spinnaker的机器上完成K8S集群的认证,以及权限管理。
3)、部署的时候选择安装环境:我选择的是Debian包的方式。
4)、选择存储:官方推荐使用minio,我选择的是minio的方式。
5)、选择安装的版本:我当时最新的是V1.8.0
6)、接下来进行部署工作,初次部署时间较长,会连接代理下载对应的包。
7)、全部下载与完成后,查看对应的日志,即可使用localhost:9000访问即可。
完成以上的步骤则可以在kubernetes上面部署对应的应用了。
下图是spinnaker的各个组件之间的关系。
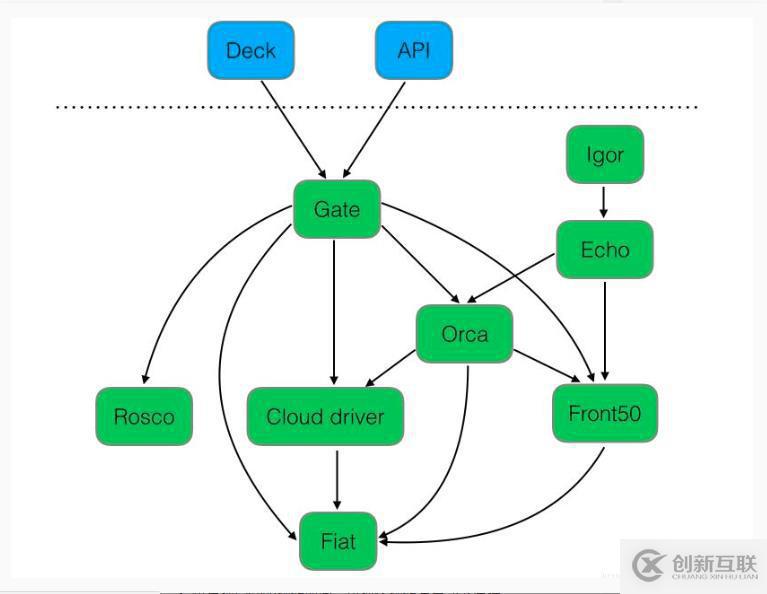
下面介绍一下每个组件在spinnaker中作用
Deck:面向用户 UI 界面组件,提供直观简介的操作界面,可视化操作发布部署流程。
API: 面向调用 API 组件,我们可以不使用提供的
UI,直接调用 API 操作,由它后台帮我们执行发布等任务。
Gate:是 API 的网关组件,可以理解为代理,所有请求由其代理转发。
Rosco:是构建 beta 镜像的组件,需要配置 Packer 组件使用。
Orca:是核心流程引擎组件,用来管理流程。
Igor:是用来集成其他 CI 系统组件,如 Jenkins 等一个组件。
Echo:是通知系统组件,发送邮件等信息。
Front50:是存储管理组件,需要配置 Redis、Cassandra 等组件使用。
Cloud driver 是它用来适配不同的云平台的组件,比如 Kubernetes,Google、AWS EC2、Microsoft Azure 等。
Fiat 是鉴权的组件,配置权限管理,支持 OAuth、SAML、LDAP、GitHub teams、Azure groups、 Google Groups 等。
5、spinnaker在kubernetes的持续部署
一个优美的PIPELINE,部署示例。
如下pipeline设计就是开发将版本合到某一个分支后,通过jenkins镜像构建,发布测试环境,进而自动化以及人工验证,在由人工判断是否需要发布到线上以及回滚,若是选择发布到线上则发布到prod环境,从而进行prod自动化的CI。若是选择回滚则回滚到上个版本,从而进行dev自动化的CI。
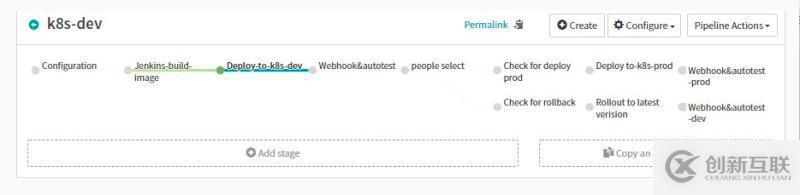
我们针对如上的pipeline的每个stage进行分析:
Stage-configuration具有如下的配置
Automated Triggers
设置触发的方式,定义全局变量,执行报告的通知方式,是pipeline的起点
这里我们可以指定多种触发的方式:定时任务corn,git,jenkins,docker Registry,travis,pipeline,webhook等
Parameters
此处定义的全局变量会在整个PIPELINE中使用${ parameters[‘branch’]}得到,这样大大的简化了我们设计pipeline的通用性
Notifications
这里通知支持:SMS,EMAIL,HIPCHAT等等的方式
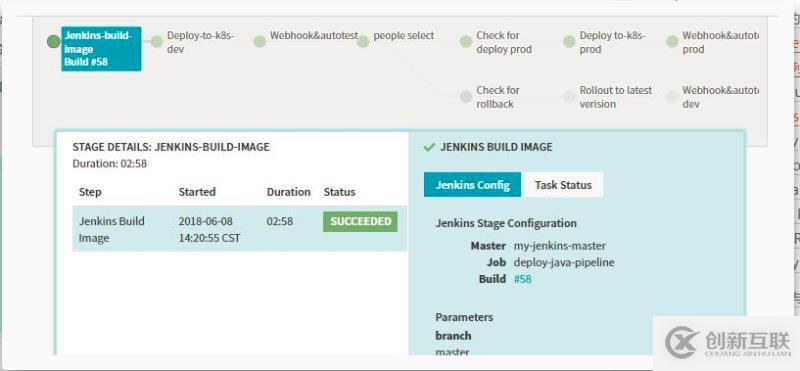
运行完成后展示如下,我们可以查看相关的build的信息,以及此stage执行的相关信息,点击build可以跳到对应的jenkins的job查看相关的任务信息。
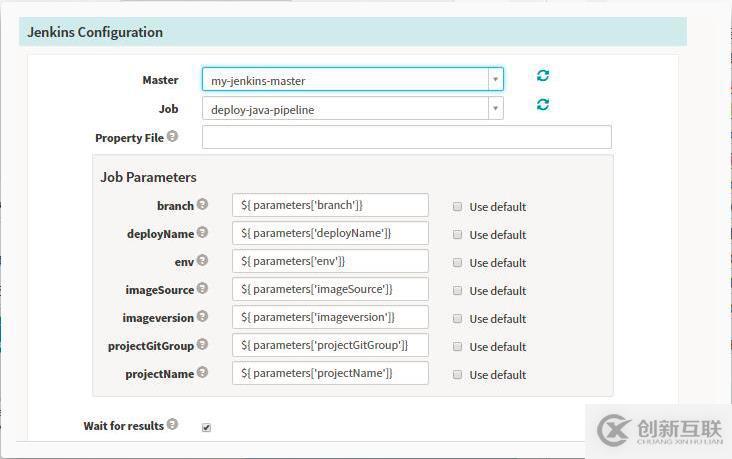
Stage-jenkins这个就很厉害了,完美的与jenkins结合,
调用jenkins来执行相关的任务,其中jenkins的服务信息存在放hal的配置文件中(如下展示),spinnaker可自动以同步jenkins的job以及参数等等的信息,运行后能够看到对应的JOB ID以及状态:
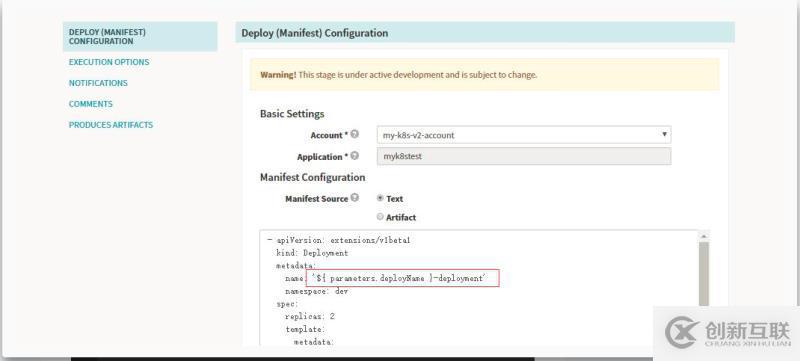
Stage-deploy
由于我们配置spinnaker的时候采用的是Kubernetes Provider V2方式,我们的发布均采用yaml的方式来实现,可以将文件存放在github中或者直接在页面上进行配置,同时yaml中文件支持了很多的参数化,这样大大的方便了我们日常的使用。
halyard关联KUBERNETES的配置信息
由于我们采用的云服务是KUBERNETES,配置的时候需要将部署spinnaker的机器对KUBERNETES集群做认证。
spinnaker发布信息展示:
此处Manifest Source支持参数化形式,类似于我们写入的yaml部署文件,但是这里支持参数化的方式。
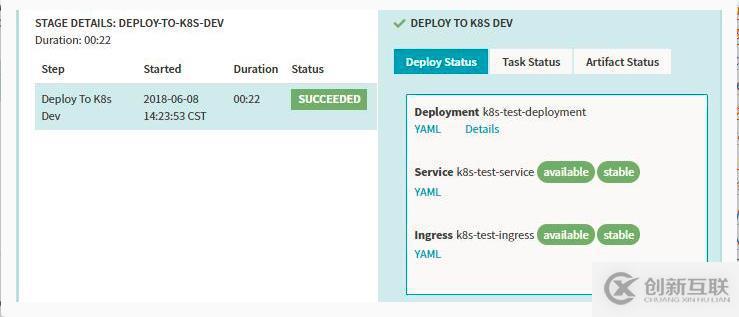
Stage-Webhook
webhook
我们可以做一些简单的环境验证以及去调用其他的服务的功能,它自身也提供了一些结果的验证功能,支持多种请求的方式。
Stage-Manual Judgment
用于人工的逻辑判断,增加pipeline的控制性(比如发布到线上需要测试人员认证以及领导审批),内容支持多种语法表达的方式。
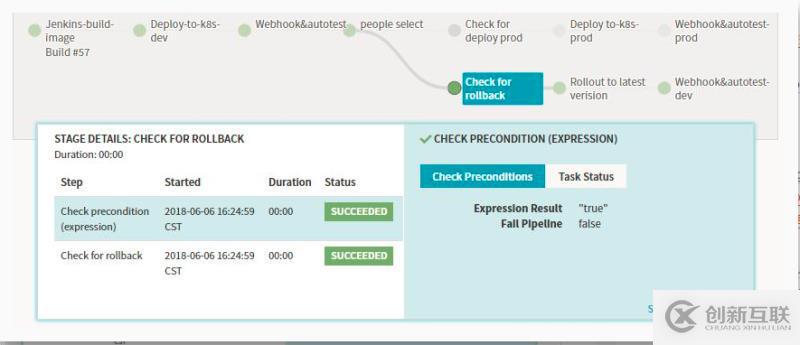
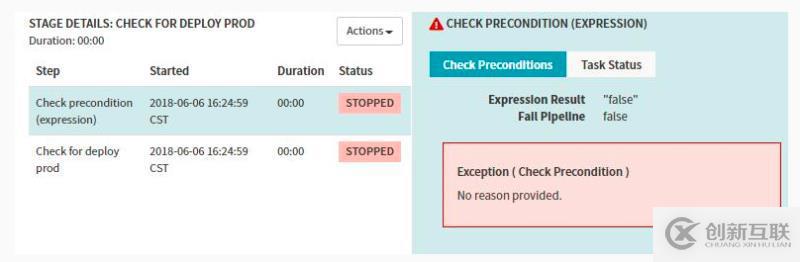
Stage-Check Preconditions
上边 Manual Judgment Stage 配置了两个 Judgment Inputs 判断项,接下来我们建两个 Check Preconditions Stage 来分别对这两种判断项做条件检测,条件检测成功,则执行对应的后续 Stage 流程。比如上面的操作,若是选择发布到prod,则执行发布到线上的分支,若是选择执行回滚的操作则进行回滚相关的分支。
如上图中我选择了rollback,则prod分支判断为失败,会阻塞后面的stage运行。
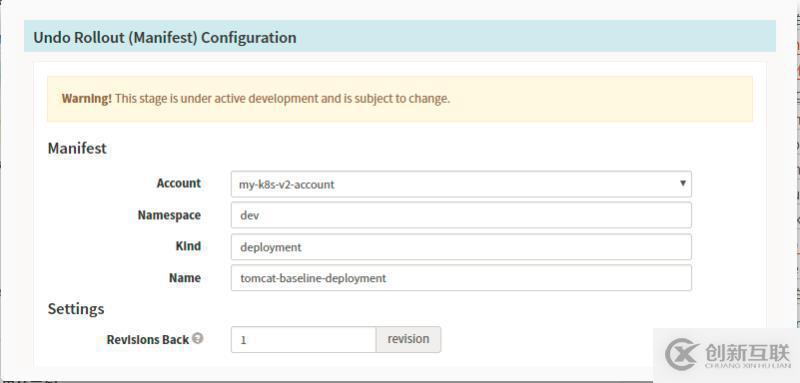
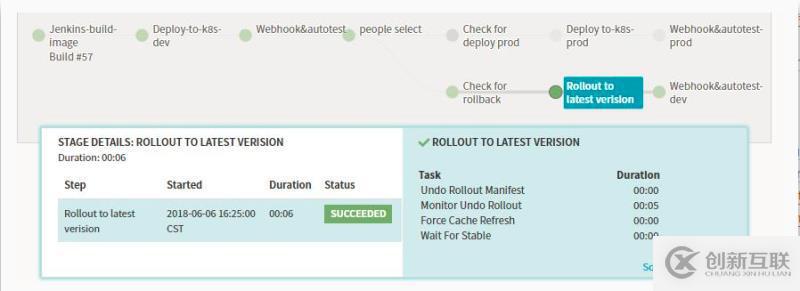
Stage-Undo Rollout (Manifest)
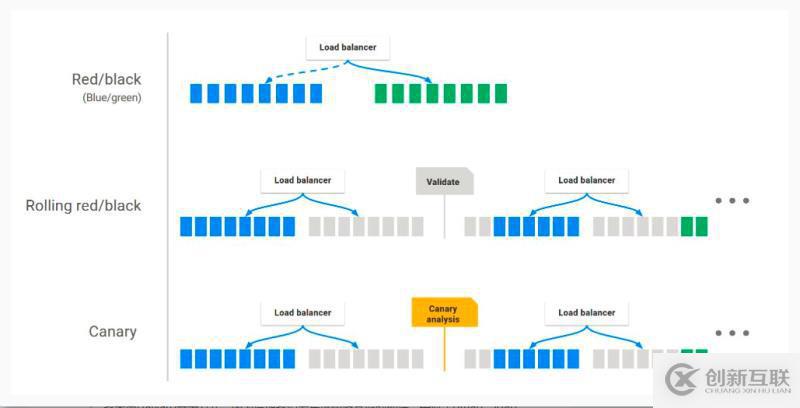
若是我们发布发现出现问题,也可以设计回滚的stage,spinnaker的回滚极其的方便,在我们的日常部署中,每个版本都会存在对应的部署记录。
回滚的pipeline描述中我们需要选择对应的deployment的回滚信息,以及回滚的版本数量。
运行结果的示例
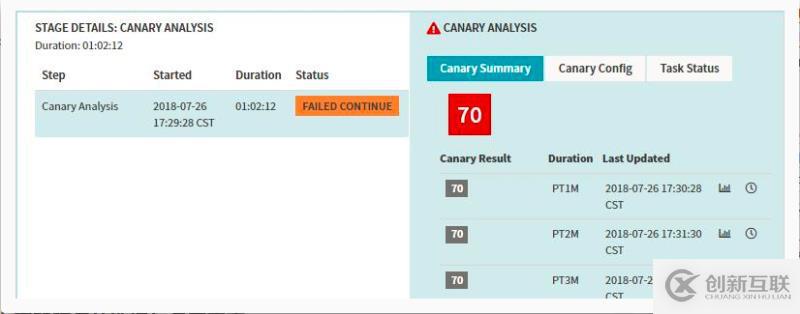
Stage-Canary Analysis
金丝雀部署方式:在我们发布新版本时引入部分流量到canary的服务中,kayenta会读取spinnaker中配置的prometheus中收集的指标,比如内存,CPU,接口超时时间,失败率等等通过kayenta中NetflixACAJudge来进行分析与判断,将分析的结果存于S3中,最终会给出这段时间的最终结果。
6、运行结果的设计与展示
1)、我们需要对应用开启canary的配置。
2)、创建出baseline与canary的deployment由同一个service指向这两个deployment。
3)、我们这里采用读取prometheus的指标,需要在hal中增加prometheus配置。Metric可以直接匹配prometheus的指标。
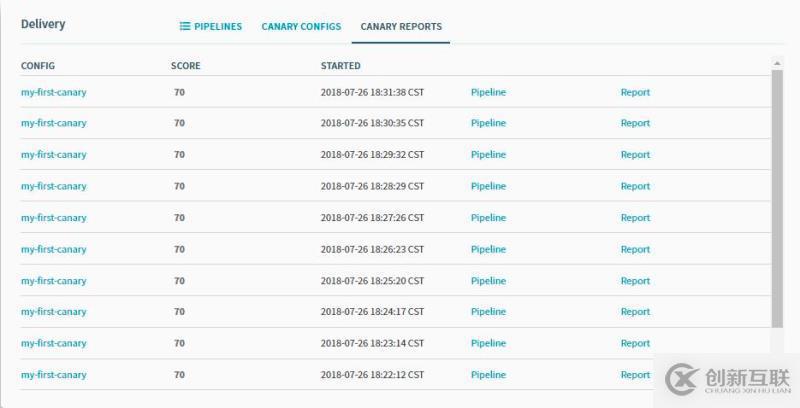
每次分析的执行记录:
结果展示如下,由于我们设置的目标是75,所以pipeline的结果判定为失败。
7、线上容器服务的选择与多区容灾
采用云容器服务主要看重以下几个方面:
1、Kubernetes在自搭建的集群中,要实现Overlay网络,在好的云平台环境里,它本身就是软件定义网络VPC,所以它在网络上的实现可以做到在容器环境里和原生的VM网络一样的快,没有任何的性能牺牲。
2、应用型负载均衡器和Kubernetes里的ingress相关联,对于需要外部访问的服务能够快速的创建。
3、云储存可以被Kubernetes管理,便于持久化的操作。
4、云部署以及告警也对外提供服务与接口,可以更好的查看与监控相关的node与pod的情况。
5、云日志服务很好的与容器进行融合,能够方便的收集与检索日志。
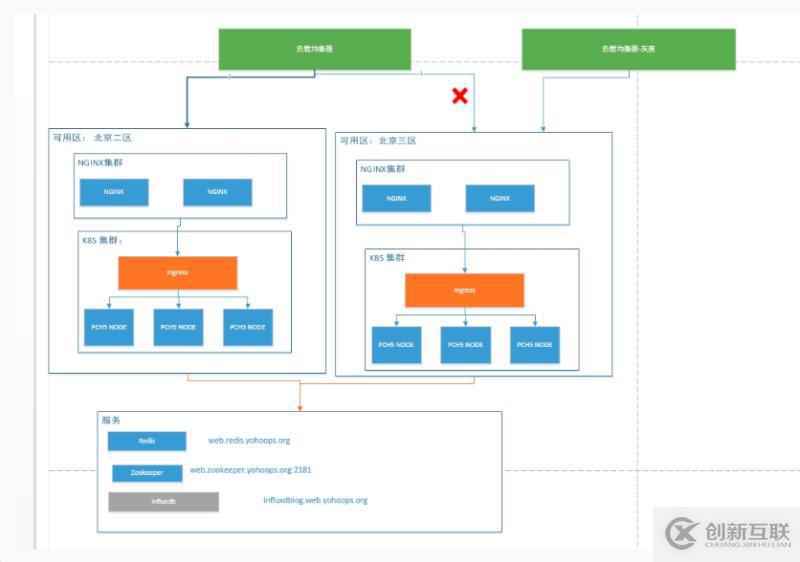
本文分享的案例中,为了容灾使用了北京二区与北京三区两个集群,若是需要灰度验证时,则将线上北京三区的权重修改为0,这样通过灰度负载均衡器即可到达新版本应用。日常使用中二区与三区均同时提供挂服务。设计的思路以及模型如下:
pipeline执行结果展示
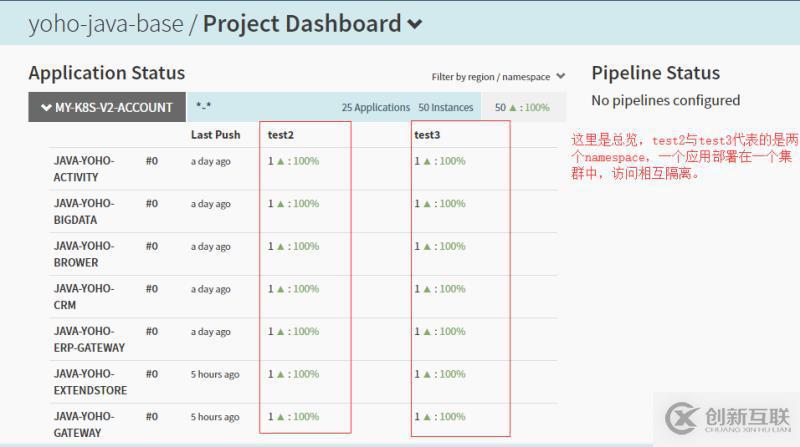
具体某个应用的展示:
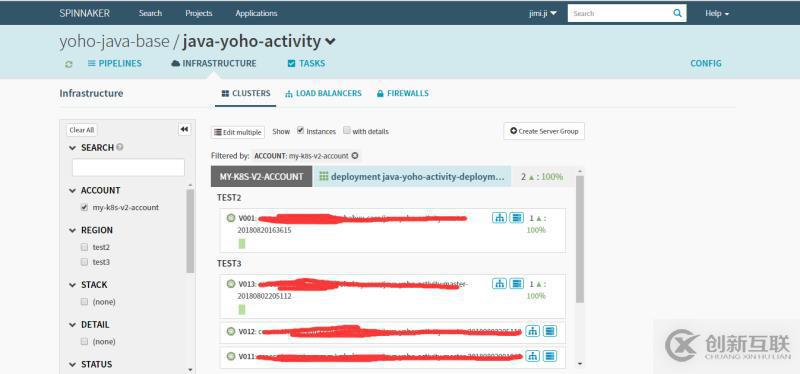 具体某个应用的展示:
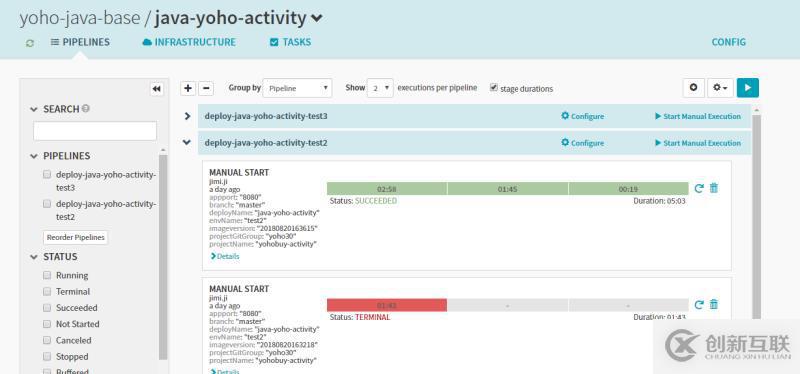
具体某个应用的展示:
8、相关问题
Q:为什么没有和CI结合在一起?使用这个比较重的spannaker有什么优势?
A:可以和CI进行结合,比如webhook的方式,或者采用jenkins调度的方式。
优势在于可以和很多云平台进行结合不仅仅支持容器,而且他的pipeline比较完美,参数化程度很高。
Q:spannaker的安全性方面怎么控制?
A:spinnaker中Fiat 是鉴权的组件,配置权限管理,Auth、SAML、LDAP、GitHub teams、Azure groups、 Google Groups,我们就采用ldap,登陆后会在上面显示对应的登陆人员。
Q:spinnaker能不能在pipeline里通过http api获取一个deployment yaml进行deploy,这个yaml可能是动态生成的
A:部署服务有两种方式:
1)、在spinnaker的UI中直接填入Manifest Source ,其实就是对应的deployment YAML,只不过这里可以写入pipeline的参数。
2)、可以从github中拉取对应的文件,来部署,前提是要配置好对应的git地址以及项目。
Q:目前IaaS只支持openstack和国外的公有云厂商,国内的云服务商如果要支持的话,底层需要怎么做呢(管理云主机而不是容器)?自己实现的话容易吗?怎么入手?
A:目前我们主要使用spinnaker用来管理容器这部分的内容,对于国内的云厂商spinnaker支持都不是非常的好,像lb,安全策略这些都不可在spinnaker上面控制。若是需要研究可以查看Cloud driver这个组件的功能。
Q:个人感觉还是需要结合Jenkins完成build,还有镜像仓库 etc。。。spinnaker只是完成了后面交付的部分,是这样吧?
A:对的,spinnaker是一个持续交付的工具,我们在使用中也是通过jenkins来完成镜像的制作以及推送到仓库。
Q: spannaker 之前的截图看到也有对部分用户开发的功能,用spannaker 之后 还需要Istio吗?
A:这两个有不同的功能,【对部分用户开发的功能】这个是依靠创建不同的service以及ingress来实现的,他的路由能力肯定没有istio强悍,而且也不具备熔断等等的技术,我们线下这么创建主要为了方便开发人员进行快速的部署与调试。
Q: deploy和test以及rollback可以跟helm chart集成吗?
A:我觉得是可以,很笨的方法最终都是可以借助于jenkins来实现,但是spinnaker的回滚与部署技术很强大,在页面上点击就可以进行快速的版本回滚与部署。
Q:最外层为何选择nginx集群而不是某云的负载均衡器?
A:我们流量的入口是某云的负载均衡器,但是接下来我们有一些策略在NGINX中实现。
(本文根据 季邦华 社群分享整理)
网站标题:如何在Kubernetes容器环境下部署Spinnaker?-创新互联
路径分享:https://www.cdcxhl.com/article20/cepejo.html
成都网站建设公司_创新互联,为您提供品牌网站制作、云服务器、响应式网站、域名注册、外贸网站建设、App设计
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 网站导航制作专题之导航的正确摆放位置 2022-09-19
- 网站导航设计指南:如何做一个有吸引力的网站? 2022-11-17
- 浅析网站导航结构优化的方法有那些 2016-08-04
- 在网站制作如何划分清晰的网站导航栏目 2022-11-24
- 网页设计公司网站导航重点放在哪? 2016-10-23
- 网站导航设计需要注意哪些问题? 2016-11-01
- 网站导航栏划分的策略 2016-10-31
- 网站导航设计需要重视哪些内容? 2020-08-15
- 良好的网站导航如何网站建设可用性 2016-08-23
- 湛江网站开发:网站导航怎么设计制作才够炫,更能吸引用户的! 2022-12-30
- 网站导航的类型都有哪些? 2020-07-12
- 成都网站建设中网站导航建设应该注意哪些事项 2023-03-10