关于项目自动化测试架构的改良计划-解析XInclude标记
因为在test_suite.xml中,我们多处使用了XInclude标记,他们会被申明在一个叫"http://www.w3.org/2001/XInclude" 的名字空间中,并且引入部分用xi:include来声明,我们这个类的作用就是把这些所有的<xi:include>的部分,都用被引入的文件插入和替换掉。
创新互联是专业的文山州网站建设公司,文山州接单;提供做网站、成都网站设计,网页设计,网站设计,建网站,PHP网站建设等专业做网站服务;采用PHP框架,可快速的进行文山州网站开发网页制作和功能扩展;专业做搜索引擎喜爱的网站,专业的做网站团队,希望更多企业前来合作!
/**
* This class will handle converting a xinclude+xpointer marked xml file to a normal xml file
* Because of the shortage of the current jdk ,it only support the xPointer with element instead of NCName
*@author cwang58
*@created date: Jun 10, 2013
*/
public class XIncludeConverter {
/**
* this method will handle change the XInclude+XPointer marked xml as normal xml
* @param origialXML the original xml which has the xInclude feature
* @return the parsedXML without the xInclude feature
*/
public static String convertXInclude2NormalXML(String originalXML)
throws SAXException,ParserConfigurationException,TransformerConfigurationException,IOException,TransformerException{
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
//open up the namespace aware so that it can recognize the "xi" namespace
factory.setNamespaceAware(true);
//let this SAXParser support XInclude
factory.setXIncludeAware(true);
//factory.setValidating(true);
//ignore all the comments added in the source document
factory.setIgnoringComments(true);
DocumentBuilder docBuilder = factory.newDocumentBuilder();
Document doc = docBuilder.parse(new InputSource(new ByteArrayInputStream(originalXML.getBytes("utf-8"))));
Transformer transformer = TransformerFactory.newInstance().newTransformer();
//format the output xml string so it support indent and more readable
transformer.setOutputProperty(OutputKeys.INDENT, "yes");
//initialize StreamResult with File object to save to file
StreamResult result = new StreamResult(new StringWriter());
DOMSource source = new DOMSource(doc);
transformer.transform(source, result);
return result.getWriter().toString();
}
这里讲一个小插曲,其实,W3C中,XInclude经常和Xpointer联合起来应用的,xpointer可以帮助来定位目标文件的某个小片段而不是整个目标文件,定位方法可以用element(),或者xpointer(),如果element的话,可以用(/1/2/3)这种方式来定位DOM,或者基于 id,对应java的解析框架是xerce,但是非常不幸运的是,最新版本的xerce框架只支持element(/1/3/4/5)这种定位,而对于基于schema-id的方式,也就是某个element声明了id的情况,它没办法定位,但是未来可能会支持这个功能。
http://xerces.apache.org/xerces2-j/faq-xinclude.html#faq-8
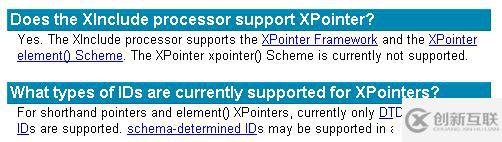
基于上述的局限性,我决定只采用xi:include来包含全部文件,然后局部调整的做法,并且绕过xpointer。
所以实现代码如上所示,事实上从JDK 1.6开始,他已经提供了对XInclude的支持,内部是委托给xerce来实现的,这是对应架构图的第3-4步骤。
当前名称:关于项目自动化测试架构的改良计划-解析XInclude标记
本文URL:https://www.cdcxhl.com/article2/jodpic.html
成都网站建设公司_创新互联,为您提供软件开发、ChatGPT、企业建站、定制开发、域名注册、App开发
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 影响服务器托管价格有哪些? 2022-10-07
- 为什么要进idc数据中心服务器机房托管? 2015-03-10
- 美国服务器托管怎么样?有什么要留意? 2022-10-04
- 什么是独享服务器托管? 2022-10-06
- 站群服务器托管服务商都有哪些特性? 2022-10-03
- 中小企业福音:郑州bgp多线服务器托管 2021-03-15
- IDC服务器托管有什么作用? 2022-10-10
- 服务器托管的好处有什么呢? 2022-10-02
- 创新互联服务器托管,为您的跨境电商保驾护航 2021-03-10
- 服务器托管收费标准 2021-03-20
- 服务器托管是什么?为什么要托管? 2022-10-03
- 香港服务器托管费用贵吗?香港服务器托管有哪些优势? 2022-10-12