DataPipeline丨新型企业数据融合平台的探索与实践-创新互联


一、关于数据融合和企业数据融合平台
数据融合是把不同来源、格式、特点性质的数据在逻辑上或物理上有机地集中,从而为企业提供全面的数据共享。
企业数据融合平台,通常的表现形态为运行着大量数据同步和转换任务的分布式系统。其源端一般为各类偏实时的业务数据存储系统,目的端为各类数据仓库/对象存储。
二、企业数据融合平台的典型架构
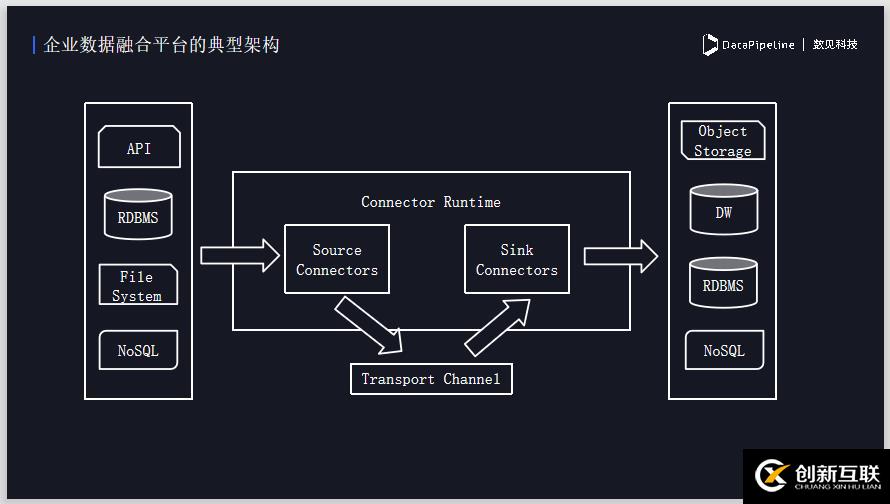
下图为数据融合平台的典型架构,源端是不同的数据存储系统,另一端是各种类型的数据仓库,关系型数据库或者文件存储等。中间为数据融合平台的简单架构,组件Source connectors负责做数据的采集。
将数据采集之后,会将其做成格式化数据放到Transport Channel,Transport Channel一般会用Source队列或其它流式数据框架,负责做中间的缓存,包括分布式的支持,数据的分发, sink connectors去负责把数据分别写入不同的数据目的地。
三、企业数据融合需要解决的关键问题
- 数据异构问题
面临繁琐的数据源和目的地适配以及异构数据源的转换问题。
- 随时变化的数据结构
数据源结构会随时发生变化,造成下游写入失败。当数据结构发生改变时,需要保证数据像正常一样,不会出现任何问题。
- 数据平台的扩展性
需要根据业务驱动做水平拓展,甚至需应对一对多的分发要求,另外也需要处理和解决多任务并行的QoS。
- 数据一致性
在任何情况下都需要保证数据是一致的,这也是在生产过程中需要保证的问题。
四、消息队列在数据融合平台的作用
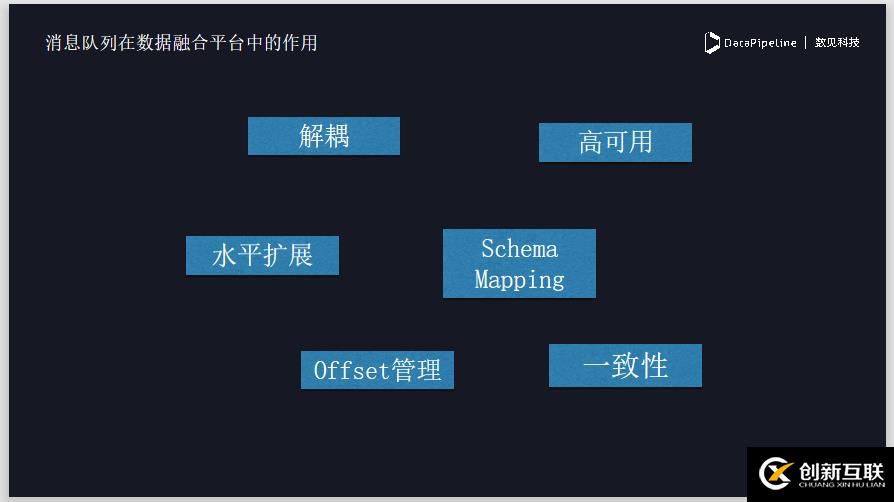
首先是解耦,消息队列可以将源端的数据采集跟移动端的数据完全进行解耦。如果数据写入端出现任何问题,不会影响数据采集的稳定型。
Schema Mapping帮助我们做到了数据源和目的地结构的解耦,减少开发新的connector的复杂度。
同时消息队列提供了水平拓展和高可用的性质,当需要接入更多数据且系统不能支撑时,我们可以轻易的做水平拓展,支持更大的数据量。
另外,对消息队列和数据同步一致性的问题做了保证,至少能保证数据同步的顺序性。
五、DataPipeline现有架构
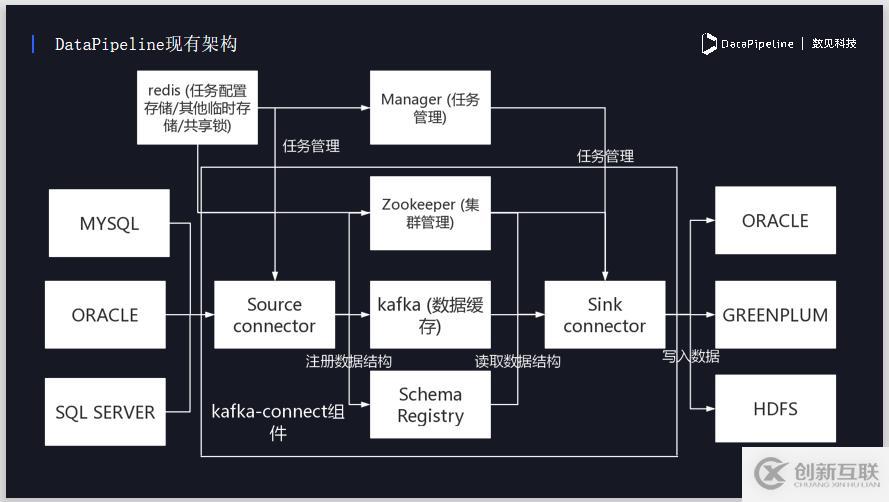
下图为DataPipeline基于Kafka connect消息队列所做的架构,Kafka本身是一个非常成熟的消息队列,Kafka connect是其下面的一个子项目,相当于给kafka consumer 和 kafka producer提供了一个封装,它实现了分布式和高可用,同时帮助我们负责和kakfa进行交互。
六、Kafka connect-offset管理
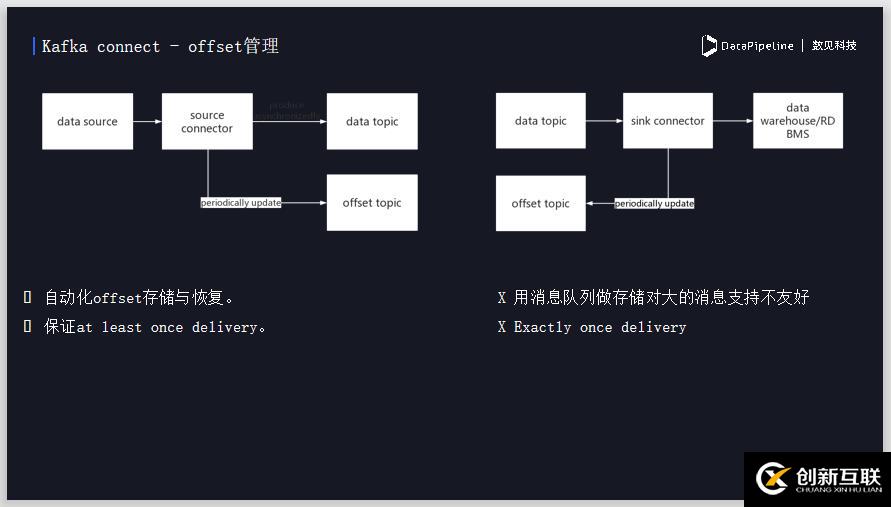
消费者会有一个offset的概念,用来记录消费进度,Kafka connect会自动化地做消息offset的管理,它可以等我们消费完一些数据之后,自动提交消费进度,然后在Kafka中做存储。
在读取数据的时候, connector会将数据从数据源抽取出来写到data topic,用来做数据中间的缓存。同时connector在同步过程中也会周期性的将offset提交到offset Topic,相当于每读取一段时间,存一个存档点。
周期性的offset提交如果失败的话,会导致数据任务重启恢复时无法完全恢复到最后写入的offset点。这种情况就会导致数据的重复读取和重复写入,会出现数据一致性的问题,以下解决方案可以从一定程度上避免这个问题:
依赖目的地的特性进行去重达到数据的最终一致性,例如: RDBMS用主键进行去重。
依赖消息队列的事务信息避免源端重复,保证数据写入和offset写入的事务性提交。
目的端在写入后记录单独的offset到redis缓存,并在任务恢复之后根据offset进行过滤,避免重复写入。减少offset rewind带来的数据重复,但是由于写入数据和记录offset并不是事务操作,所以也不保证exactly once delivery。
- 依赖目的地的事务性,在目的地建立临时空间记录写入的offset,并在任务恢复之后根据offset进行过滤,避免重复写入,可以保证exactly once delivery。但是要求目的地可以支持事务性,并且会在目的地有额外的数据存储。
另外有需要云服务器可以了解下创新互联scvps.cn,海内外云服务器15元起步,三天无理由+7*72小时售后在线,公司持有idc许可证,提供“云服务器、裸金属服务器、高防服务器、香港服务器、美国服务器、虚拟主机、免备案服务器”等云主机租用服务以及企业上云的综合解决方案,具有“安全稳定、简单易用、服务可用性高、性价比高”等特点与优势,专为企业上云打造定制,能够满足用户丰富、多元化的应用场景需求。
分享标题:DataPipeline丨新型企业数据融合平台的探索与实践-创新互联
分享网址:https://www.cdcxhl.com/article2/hcsic.html
成都网站建设公司_创新互联,为您提供外贸网站建设、静态网站、域名注册、品牌网站建设、网站内链、定制开发
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 定制网站建设-定制网站企业关系的只是价格吗? 2016-11-13
- 为什么定制网站比模板网站要贵 2017-08-08
- 合作伙伴定制网站好还是自主建站的好呢??两者间 2020-08-01
- 定制网站的优点在哪? 2016-08-10
- 定制网站有哪些优势? 2023-03-05
- SEO模板网站与定制网站的区分 2013-07-13
- 普宁定制网站建设有哪些环节? 2021-01-05
- 成都网站建设定制网站建设流程有哪些? 2016-09-26
- 企业做定制网站建设的优点是什么 2021-08-21
- 成都定制网站建设的未来发展趋势如何? 2022-07-11
- 企业定制网站建设的流程 2016-12-01
- 为什么要选择定制网站制作 2016-11-28