怎么使用Python3中的pathlib
这篇文章主要讲解了“怎么使用Python3中的pathlib”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“怎么使用Python3中的pathlib”吧!
创新互联建站专注于企业全网营销推广、网站重做改版、岱山网站定制设计、自适应品牌网站建设、HTML5、商城开发、集团公司官网建设、成都外贸网站建设公司、高端网站制作、响应式网页设计等建站业务,价格优惠性价比高,为岱山等各大城市提供网站开发制作服务。
使用pathlib处理更好的路径
pathlib 是 Python3 中的一个默认模块,可以帮助你避免使用大量的 os.path.join。
from pathlib import Path
dataset = 'wiki_images'
datasets_root = Path('/path/to/datasets/')
#Navigating inside a directory tree,use:/
train_path = datasets_root / dataset / 'train'
test_path = datasets_root / dataset / 'test'
for image_path in train_path.iterdir():
with image_path.open() as f: # note, open is a method of Path object
# do something with an image不要用字符串链接的形式拼接路径,根据操作系统的不同会出现错误,我们可以使用/结合 pathlib来拼接路径,非常的安全、方便和高可读性。
pathlib 还有很多属性,具体的可以参考pathlib的官方文档,下面列举几个:
from pathlib import Path
a = Path("/data")
b = "test"
c = a / b
print(c)
print(c.exists()) # 路径是否存在
print(c.is_dir()) # 判断是否为文件夹
print(c.parts) # 分离路径
print(c.with_name('sibling.png')) # 只修改拓展名, 不会修改源文件
print(c.with_suffix('.jpg')) # 只修改拓展名, 不会修改源文件
c.chmod(777) # 修改目录权限
c.rmdir() # 删除目录类型提示现在是语言的一部分
一个在 Pycharm 使用Typing的例子:
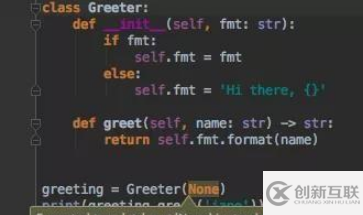
引入类型提示是为了帮助解决程序日益复杂的问题,IDE可以识别参数的类型进而给用户提示。
关于Tying的具体用法,可以参考:python类型检测最终指南--Typing的使用
运行时类型提示类型检查
除了之前文章提到 mypy 模块继续类型检查以外,还可以使用 enforce 模块进行检查,通过 pip 安装即可,使用示例如下:
import enforce
@enforce.runtime_validation
def foo(text: str) -> None:
print(text)
foo('Hi') # ok
foo(5) # fails输出
Hi Traceback (most recent call last): File "/Users/chennan/pythonproject/dataanalysis/e.py", line 10, in <module> foo(5) # fails File "/Users/chennan/Desktop/2019/env/lib/python3.6/site-packages/enforce/decorators.py", line 104, in universal _args, _kwargs, _ = enforcer.validate_inputs(parameters) File "/Users/chennan/Desktop/2019/env/lib/python3.6/site-packages/enforce/enforcers.py", line 86, in validate_inputs raise RuntimeTypeError(exception_text) enforce.exceptions.RuntimeTypeError: The following runtime type errors were encountered: Argument 'text' was not of type <class 'str'>. Actual type was int.
使用@表示矩阵的乘法
下面我们实现一个最简单的ML模型——l2正则化线性回归(又称岭回归)
# l2-regularized linear regression: || AX - y ||^2 + alpha * ||x||^2 -> min # Python 2 X = np.linalg.inv(np.dot(A.T, A) + alpha * np.eye(A.shape[1])).dot(A.T.dot(y)) # Python 3 X = np.linalg.inv(A.T @ A + alpha * np.eye(A.shape[1])) @ (A.T @ y)
使用@符号,整个代码变得更可读和方便移植到其他科学计算相关的库,如numpy, cupy, pytorch, tensorflow等。
**通配符的使用
在 Python2 中,递归查找文件不是件容易的事情,即使是使用glob库,但是从 Python3.5 开始,可以通过**通配符简单的实现。
import glob
# Python 2
found_images = (
glob.glob('/path/*.jpg')
+ glob.glob('/path/*/*.jpg')
+ glob.glob('/path/*/*/*.jpg')
+ glob.glob('/path/*/*/*/*.jpg')
+ glob.glob('/path/*/*/*/*/*.jpg'))
# Python 3
found_images = glob.glob('/path/**/*.jpg', recursive=True)更好的路径写法是上面提到的 pathlib ,我们可以把代码进一步改写成如下形式。
# Python 3
import pathlib
import glob
found_images = pathlib.Path('/path/').glob('**/*.jpg')Print函数
虽然 Python3 的 print 加了一对括号,但是这并不影响它的优点。
使用文件描述符的形式将文件写入
print >>sys.stderr, "critical error" # Python 2
print("critical error", file=sys.stderr) # Python 3不使用 str.join 拼接字符串
# Python 3 print(*array, sep=' ') print(batch, epoch, loss, accuracy, time, sep=' ')
重新定义 print 方法的行为
既然 Python3 中的 print 是一个函数,我们就可以对其进行改写。
# Python 3 _print = print # store the original print function def print(*args, **kargs): pass # do something useful, e.g. store output to some file
注意:在 Jupyter 中,最好将每个输出记录到一个单独的文件中(跟踪断开连接后发生的情况),这样就可以覆盖 print 了。
@contextlib.contextmanager
def replace_print():
import builtins
_print = print # saving old print function
# or use some other function here
builtins.print = lambda *args, **kwargs: _print('new printing', *args, **kwargs)
yield
builtins.print = _print
with replace_print():
<code here will invoke other print function>虽然上面这段代码也能达到重写 print 函数的目的,但是不推荐使用。
print 可以参与列表理解和其他语言构造
# Python 3
result = process(x) if is_valid(x) else print('invalid item: ', x)数字文字中的下划线(千位分隔符)
在 PEP-515 中引入了在数字中加入下划线。在 Python3 中,下划线可用于整数,浮点和复数,这个下划线起到一个分组的作用
# grouping decimal numbers by thousands
one_million = 1_000_000
# grouping hexadecimal addresses by words
addr = 0xCAFE_F00D
# grouping bits into nibbles in a binary literal
flags = 0b_0011_1111_0100_1110
# same, for string conversions
flags = int('0b_1111_0000', 2)也就是说10000,你可以写成10_000这种形式。
简单可看的字符串格式化f-string
Python2提供的字符串格式化系统还是不够好,太冗长麻烦,通常我们会写这样一段代码来输出日志信息:
# Python 2
print '{batch:3} {epoch:3} / {total_epochs:3} accuracy: {acc_mean:0.4f}±{acc_std:0.4f} time: {avg_time:3.2f}'.format(
batch=batch, epoch=epoch, total_epochs=total_epochs,
acc_mean=numpy.mean(accuracies), acc_std=numpy.std(accuracies),
avg_time=time / len(data_batch)
)
# Python 2 (too error-prone during fast modifications, please avoid):
print '{:3} {:3} / {:3} accuracy: {:0.4f}±{:0.4f} time: {:3.2f}'.format(
batch, epoch, total_epochs, numpy.mean(accuracies), numpy.std(accuracies),
time / len(data_batch)
)输出结果为
120 12 / 300 accuracy: 0.8180±0.4649 time: 56.60
在 Python3.6 中引入了 f-string (格式化字符串)
print(f'{batch:3} {epoch:3} / {total_epochs:3}
accuracy: {numpy.mean(accuracies):0.4f}±{numpy.std(accuracies):0.4f} time: {time / len(data_batch):3.2f}')关于 f-string 的用法可以看我在b站的视频[https://www.bilibili.com/video/av31608754]
'/'和'//'在数学运算中有着明显的区别
对于数据科学来说,这无疑是一个方便的改变
data = pandas.read_csv('timing.csv')
velocity = data['distance'] / data['time']Python2 中的结果取决于“时间”和“距离”(例如,以米和秒为单位)是否存储为整数。在python3中,这两种情况下的结果都是正确的,因为除法的结果是浮点数。
另一个例子是 floor 除法,它现在是一个显式操作
n_gifts = money // gift_price # correct for int and float arguments
nutshell
>>> from operator import truediv, floordiv
>>> truediv.__doc__, floordiv.__doc__
('truediv(a, b) -- Same as a / b.', 'floordiv(a, b) -- Same as a // b.')
>>> (3 / 2), (3 // 2), (3.0 // 2.0)
(1.5, 1, 1.0)值得注意的是,这种规则既适用于内置类型,也适用于数据包提供的自定义类型(例如 numpy 或pandas)。
严格的顺序
下面的这些比较方式在 Python3 中都属于合法的。
3 < '3' 2 < None (3, 4) < (3, None) (4, 5) < [4, 5]
对于下面这种不管是2还是3都是不合法的
(4, 5) == [4, 5]
如果对不同的类型进行排序
sorted([2, '1', 3])
虽然上面的写法在 Python2 中会得到结果 [2, 3, '1'],但是在 Python3 中上面的写法是不被允许的。
检查对象为 None 的合理方案
if a is not None: pass if a: # WRONG check for None pass
NLP Unicode问题
s = '您好' print(len(s)) print(s[:2])
输出内容
Python 2: 6 �� Python 3: 2 您好.
还有下面的运算
x = u'со' x += 'co' # ok x += 'со' # fail
Python2 失败了,Python3 正常工作(因为我在字符串中使用了俄文字母)。
在 Python3 中,字符串都是 unicode 编码,所以对于非英语文本处理起来更方便。
一些其他操作
'a' < type < u'a' # Python 2: True 'a' < u'a' # Python 2: False
再比如
from collections import Counter
Counter('Möbelstück')在 Python2 中
Counter({'Ã': 2, 'b': 1, 'e': 1, 'c': 1, 'k': 1, 'M': 1, 'l': 1, 's': 1, 't': 1, '¶': 1, '¼': 1})在 Python3 中
Counter({'M': 1, 'ö': 1, 'b': 1, 'e': 1, 'l': 1, 's': 1, 't': 1, 'ü': 1, 'c': 1, 'k': 1})虽然可以在 Python2 中正确地处理这些结果,但是在 Python3 中看起来结果更加友好。
保留了字典和**kwargs的顺序
在CPython3.6+ 中,默认情况下,dict 的行为类似于 OrderedDict ,都会自动排序(这在Python3.7+ 中得到保证)。同时在字典生成式(以及其他操作,例如在 json 序列化/反序列化期间)都保留了顺序。
import json
x = {str(i):i for i in range(5)}
json.loads(json.dumps(x))
# Python 2
{u'1': 1, u'0': 0, u'3': 3, u'2': 2, u'4': 4}
# Python 3
{'0': 0, '1': 1, '2': 2, '3': 3, '4': 4}这同样适用于**kwargs(在Python 3.6+中),它们的顺序与参数中出现的顺序相同。当涉及到数据管道时,顺序是至关重要的,以前我们必须以一种繁琐的方式编写它
from torch import nn
# Python 2
model = nn.Sequential(OrderedDict([
('conv1', nn.Conv2d(1,20,5)),
('relu1', nn.ReLU()),
('conv2', nn.Conv2d(20,64,5)),
('relu2', nn.ReLU())
]))而在 Python3.6 以后你可以这么操作
# Python 3.6+, how it *can* be done, not supported right now in pytorch model = nn.Sequential( conv1=nn.Conv2d(1,20,5), relu1=nn.ReLU(), conv2=nn.Conv2d(20,64,5), relu2=nn.ReLU()) )
可迭代对象拆包
类似于元组和列表的拆包,具体看下面的代码例子。
# handy when amount of additional stored info may vary between experiments, but the same code can be used in all cases model_paramteres, optimizer_parameters, *other_params = load(checkpoint_name) # picking two last values from a sequence *prev, next_to_last, last = values_history # This also works with any iterables, so if you have a function that yields e.g. qualities, # below is a simple way to take only last two values from a list *prev, next_to_last, last = iter_train(args)
提供了更高性能的pickle
Python2
import cPickle as pickle import numpy print len(pickle.dumps(numpy.random.normal(size=[1000, 1000]))) # result: 23691675
Python3
import pickle import numpy len(pickle.dumps(numpy.random.normal(size=[1000, 1000]))) # result: 8000162
空间少了三倍。而且要快得多。实际上,使用 protocol=2 参数可以实现类似的压缩(但不是速度),但是开发人员通常忽略这个选项(或者根本不知道)。
注意:pickle 不安全(并且不能完全转移),所以不要 unpickle 从不受信任或未经身份验证的来源收到的数据。
更安全的列表推导
labels = <initial_value> predictions = [model.predict(data) for data, labels in dataset] # labels are overwritten in Python 2 # labels are not affected by comprehension in Python 3
更简易的super()
在python2中 super 相关的代码是经常容易写错的。
# Python 2 class MySubClass(MySuperClass): def __init__(self, name, **options): super(MySubClass, self).__init__(name='subclass', **options) # Python 3 class MySubClass(MySuperClass): def __init__(self, name, **options): super().__init__(name='subclass', **options)
这一点Python3得到了很大的优化,新的 super() 可以不再传递参数。
同时在调用顺序上也不一样。
IDE能够给出更好的提示
使用Java、c#等语言进行编程最有趣的地方是IDE可以提供很好的建议,因为在执行程序之前,每个标识符的类型都是已知的。
在python中这很难实现,但是注释会帮助你
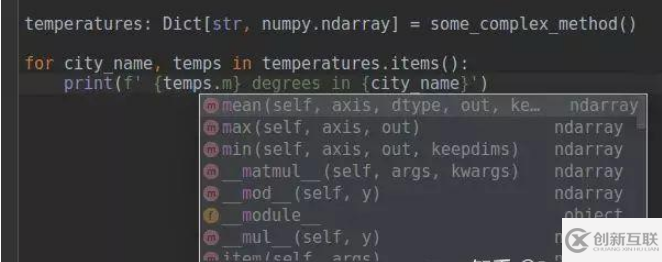
这是一个带有变量注释的 PyCharm 提示示例。即使在使用的函数没有注释的情况下(例如,由于向后兼容性),也可以使用这种方法。
Multiple unpacking
如何合并两个字典
x = dict(a=1, b=2)
y = dict(b=3, d=4)
# Python 3.5+
z = {**x, **y}
# z = {'a': 1, 'b': 3, 'd': 4}, note that value for `b` is taken from the latter dict.我在b站同样发布了相关的视频[https://www.bilibili.com/video/av50376841]
同样的方法也适用于列表、元组和集合(a、b、c是任何迭代器)
[*a, *b, *c] # list, concatenating
(*a, *b, *c) # tuple, concatenating
{*a, *b, *c} # set, union函数还支持*arg和**kwarg的多重解包
# Python 3.5+
do_something(**{**default_settings, **custom_settings})
# Also possible, this code also checks there is no intersection between keys of dictionaries
do_something(**first_args, **second_args)Data classes
Python 3.7引入了Dataclass类,它适合存储数据对象。数据对象是什么?下面列出这种对象类型的几项特征,虽然不全面:
它们存储数据并表示某种数据类型,例如:数字。对于熟悉ORM的朋友来说),数据模型实例就是一个数据对象。它代表了一种特定的实体。它所具有的属性定义或表示了该实体。它们可以与同一类型的其他对象进行比较。例如:大于、小于或等于。
当然还有更多的特性,下面的这个例子可以很好的替代namedtuple的功能。
@dataclass class Person: name: str age: int @dataclass class Coder(Person): preferred_language: str = 'Python 3'
dataclass装饰器实现了几个魔法函数方法的功能(__init__,__repr__,__le__,__eq__)
关于数据类有以下几个特性:
数据类可以是可变的,也可以是不可变的支持字段的默认值可被其他类继承数据类可以定义新的方法并覆盖现有的方法初始化后处理(例如验证一致性)
更多内容可以参考官方文档。
自定义对模块属性的访问
在Python中,可以用getattr和dir控制任何对象的属性访问和提示。因为python3.7,你也可以对模块这样做。
一个自然的例子是实现张量库的随机子模块,这通常是跳过初始化和传递随机状态对象的快捷方式。numpy的实现如下:
# nprandom.py import numpy __random_state = numpy.random.RandomState() def __getattr__(name): return getattr(__random_state, name) def __dir__(): return dir(__random_state) def seed(seed): __random_state = numpy.random.RandomState(seed=seed)
也可以这样混合不同对象/子模块的功能。与pytorch和cupy中的技巧相比。
除此之外,还可以做以下事情:
使用它来延迟加载子模块。例如,导入tensorflow时会导入所有子模块(和依赖项)。需要大约150兆内存。
在应用编程接口中使用此选项进行折旧
在子模块之间引入运行时路由
内置的断点
在python3.7中可以直接使用breakpoint给代码打断点
# Python 3.7+, not all IDEs support this at the moment foo() breakpoint() bar()
在python3.7以前我们可以通过import pdb的pdb.set_trace()实现相同的功能。
对于远程调试,可尝试将breakpoint()与web-pdb结合使用.
Math模块中的常数
# Python 3 math.inf # Infinite float math.nan # not a number max_quality = -math.inf # no more magic initial values! for model in trained_models: max_quality = max(max_quality, compute_quality(model, data))
整数类型只有int
Python 2提供了两种基本的整数类型,一种是int(64位有符号整数)一种是long,使用起来非常容易混乱,而在python3中只提供了int类型这一种。
isinstance(x, numbers.Integral) # Python 2, the canonical way isinstance(x, (long, int)) # Python 2 isinstance(x, int) # Python 3, easier to remember
在python3中同样的也可以应用于其他整数类型,如numpy.int32、numpy.int64,但其他类型不适用。
结论
虽然Python 2和Python 3共存了近10年,但是我们应该转向Python 3。
使用Python3之后,不管是研究还是生产上,代码都会变得更短,更易读,更安全。
感谢各位的阅读,以上就是“怎么使用Python3中的pathlib”的内容了,经过本文的学习后,相信大家对怎么使用Python3中的pathlib这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是创新互联,小编将为大家推送更多相关知识点的文章,欢迎关注!
文章标题:怎么使用Python3中的pathlib
本文地址:https://www.cdcxhl.com/article2/gjhoic.html
成都网站建设公司_创新互联,为您提供网站设计公司、面包屑导航、外贸网站建设、外贸建站、商城网站、全网营销推广
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 如何判断免费自助建站软件开发商是否值得选择 2017-06-20
- 「成都物流软件开发」开发一个物流软件需要多少钱 2022-05-30
- 分销电商APP软件开发的流程步骤有哪些 2022-05-26
- 创新互联:App软件开发需要注意什么 2022-11-19
- 影响APP软件开发质量的关键是什么 2022-06-08
- 选择软件开发公司制作APP优势更明显 2022-06-29
- 手机app软件开发公司浅谈APP开发 2023-03-04
- 深圳花店APP软件开发运用哪些功能? 2023-03-24
- 成都app软件开发公司需要做的准备工作 2022-08-04
- 初学Java软件开发,须熟练掌握的核心技术 2016-08-17
- App软件开发必须解决的“疑难杂症”和解决方法 2022-05-07
- 软件开发和网站开发哪种好?两者有什么区别? 2022-05-29