python-xpath如何获取html文档的部分内容-创新互联
小编给大家分享一下python-xpath如何获取html文档的部分内容,相信大部分人都还不怎么了解,因此分享这篇文章给大家参考一下,希望大家阅读完这篇文章后大有收获,下面让我们一起去了解一下吧!

python常用的库:1.requesuts;2.scrapy;3.pillow;4.twisted;5.numpy;6.matplotlib;7.pygama;8.ipyhton等。
有些时候我在们需要的用正则提取出html中某一个部分的文字内容,如图:
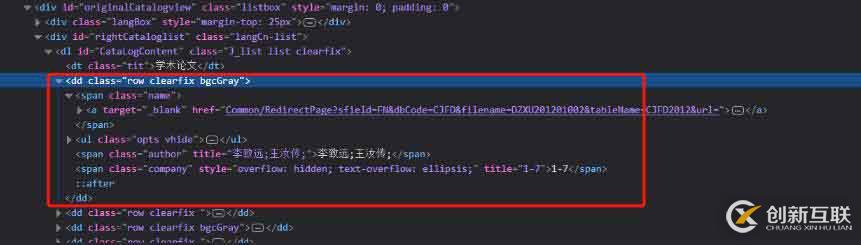
获取dd部分的html文档,我们要通过它的一个属性去确定他的位置才可以拿到他这个部分我们可以看到他的这个属性class='row clearfix ',然后用xpath去获取到这部分:
name = tree.xpath("//dd[@class='row clearfix ']")
from lxml import html
import requests
url = 'http://navi.cnki.net/knavi/JournalDetail/GetArticleList?year=2018&issue=04&pykm=DZXU&pageIdx=0&pcode=CJFD'
res = requests.get(url)
tree = html.fromstring(res.text)
name = tree.xpath("//dd[@class='row clearfix ']")
print(name)如果直接打印他是不能够出来的,

我们需要对Element进行处理,用到name1 = html.tostring(name[0]),代码如下:
from lxml import html
import requests
url = 'http://navi.cnki.net/knavi/JournalDetail/GetArticleList?year=2018&issue=04&pykm=DZXU&pageIdx=0&pcode=CJFD'
res = requests.get(url)
tree = html.fromstring(res.text)
name = tree.xpath("//dd[@class='row clearfix ']")
name1 = html.tostring(name[0])
print(name1)打印截图:

但是大家可以看到里面的等内容并不是中文,原因是我们使用tostring方法输出的是修正后的HTML代码,但是结果是bytes类型,在python中bytes类型是不可以进行编码的,需要转换成字符串,使用代码name1.decode(),此时我们将bytes类型转换为str(字符串)类型。
那么此时我们关键是如何将$#26080;此类的符号转换成汉字!!!那么首先要搞清楚这是什么编码?这类符号是HTML、XML 等 SGML 类语言的转义序列。它们不是”编码“,也就是说我们不能使用utf-8、gbk等编码进行处理,需要使用HTMLParse进行处理,完整代码如下:
from lxml import html
import requests
from html.parser import HTMLParser #导入html解析库
url = 'http://navi.cnki.net/knavi/JournalDetail/GetArticleList?year=2018&issue=04&pykm=DZXU&pageIdx=0&pcode=CJFD'
res = requests.get(url)
tree = html.fromstring(res.text)
name = tree.xpath("//dd[@class='row clearfix ']")
name1 = html.tostring(name[0])
name2 = HTMLParser().unescape(name1.decode())
print(name2)此时运行结果如下:

以上是“python-xpath如何获取html文档的部分内容”这篇文章的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注创新互联行业资讯频道!
当前标题:python-xpath如何获取html文档的部分内容-创新互联
分享地址:https://www.cdcxhl.com/article2/dcssoc.html
成都网站建设公司_创新互联,为您提供网站维护、品牌网站设计、网站内链、软件开发、网站设计、关键词优化
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 商城网站定制开发有哪些功能模块-大连微信开发 2022-07-15
- 母婴商城成都网站建设站定制开发 2016-11-14
- app定制开发的具体流程是什么? 2020-12-06
- 网站定制开发都有哪些特点? 2016-10-29
- 现在的网站开发中为什么选择定制开发主要原因在哪里呢 2016-10-27
- 企业软件定制开发有哪些优势 2023-03-27
- 上海如何快速微信小程序定制开发 2020-12-17
- 上海直播类APP定制开发需要多少钱? 2023-03-22
- 网站定制开发要素及价格为何差距大 2021-05-28
- 上海网站定制开发时网页排版布局有哪些原则 2020-12-02
- 提高定制开发网站的核心竞争力 2017-11-25
- 企业进行网站定制开发之前有哪些准备要做 2016-11-09