如何使用Python网络爬虫实现起点小说下载
如何使用Python网络爬虫实现起点小说下载,针对这个问题,这篇文章详细介绍了相对应的分析和解答,希望可以帮助更多想解决这个问题的小伙伴找到更简单易行的方法。
创新互联是一家专注于网站设计、网站制作与策划设计,天柱网站建设哪家好?创新互联做网站,专注于网站建设10余年,网设计领域的专业建站公司;建站业务涵盖:天柱等地区。天柱做网站价格咨询:028-86922220
今天要跟大家分享一个小说爬取案例--------起点小说的小说下载。
在做这个案例之前,我们需要对其进行分析,
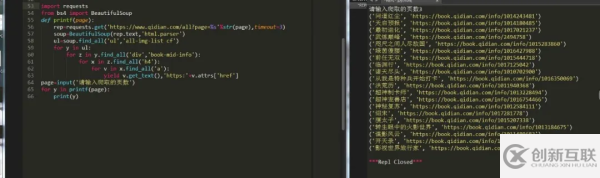
1.界面分析,如图:

通过分析很容易就找到了我们的get请求参数,然后获取相应页面的小说名和链接:
获取到数据之后,我们就随机挑选一篇小说来进行下载,我们选第一篇,

然后打开它的文章目录,可以看到是这样的,如图:

基本上这篇小说很长,可以看到它卷一和卷二是免费的,后面的收费,那么今天我们就只爬免费的章节。
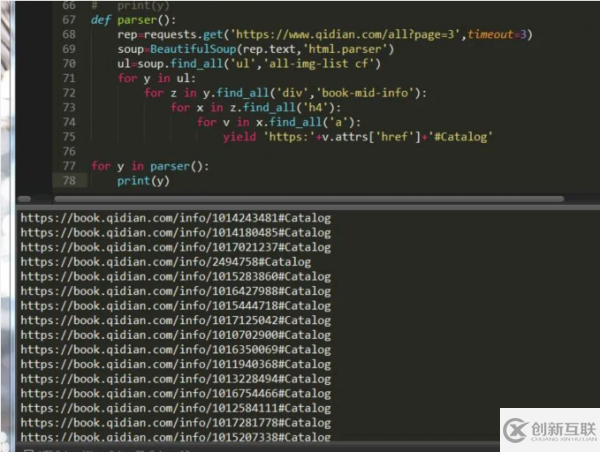
那么我们现在开始分析网页结构,如图:

那么,我们可以先把卷一的名字和章节数以及章节下的每个章节的名字都打印出来。
首先我们可以分析下这个网页地址,如图:

https://book.qidian.com/info/1014243481#Catalog
发觉前面的没变,基本就是后面的变了,增加了一个info/1014243481#Catalog,下面开始分析:
info:信息的意思,
1014243481:小说对应的ID,

#Catalog:数据补全,无太大意义
因为刚刚已经将文章链接的内容爬取出来,所以现在只需要拼接一个#Catalog 即可:
下面我们就可以对它发起请求然后在分析它的页面了,首先发起get请求,按照前面的网页分析结构来看,我们应该这样写:
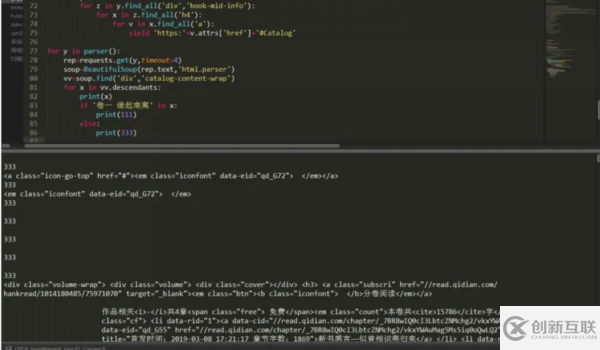
可以看出,因为这里有异步加载,所以我们的请求不会一下子全部显示出来,需要不断的请求,当然最好加个延迟。
这样我们就获取到了这个页面所有的小说,也可以这样,因为我们没找接口,所以强行解析只能解析部分内容,但是也很全面了。如图:
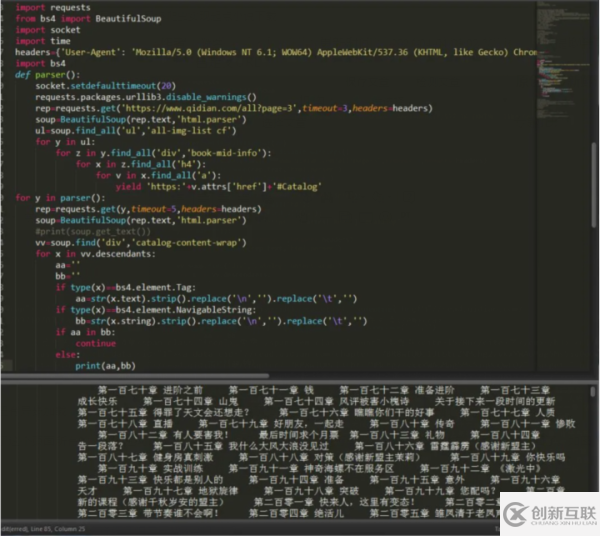
找的还算挺详细,只不过没有找接口时所拿到的数据那么规范好看了。
关于如何使用Python网络爬虫实现起点小说下载问题的解答就分享到这里了,希望以上内容可以对大家有一定的帮助,如果你还有很多疑惑没有解开,可以关注创新互联行业资讯频道了解更多相关知识。
当前题目:如何使用Python网络爬虫实现起点小说下载
分享链接:https://www.cdcxhl.com/article18/jsiggp.html
成都网站建设公司_创新互联,为您提供网页设计公司、定制网站、品牌网站建设、微信小程序、品牌网站设计、定制开发
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 成都网站建设中提升网站排名需避免哪些 2016-08-25
- 济南SEO公道的要害词机关要领可以加快网站排名首页的速度 2023-01-16
- 网站优化的过程中,网站排名大幅度变化应该怎么办? 2016-11-13
- 什么原因造成了网站排名急剧下降 2022-08-12
- 造成网站排名下降的原因 2014-11-19
- seo网站优化让排名稳定让网站排名更靠前 2021-05-10
- seo优化中外链会对网站排名有什么影响? 2015-02-01
- 济宁网站排名如何合理布局关键词?首先做关键词研究 2023-01-15
- 提高网站排名的方法是什么? 2015-10-01
- 网站排名优化如何上百度首页前十的位置? 2020-10-25
- 德州网站排名通过思维导图软件的发散性思维开导seo优化数据诊断阐明 2023-01-04
- 成都SEO浅谈网站排名基础的7大SEO优化技巧 2022-05-25