IDEA中怎么运行MapReduce程序
IDEA 中怎么运行MapReduce 程序,针对这个问题,这篇文章详细介绍了相对应的分析和解答,希望可以帮助更多想解决这个问题的小伙伴找到更简单易行的方法。
成都创新互联是一家专业从事网站设计、网站建设的网络公司。作为专业网站建设公司,成都创新互联依托的技术实力、以及多年的网站运营经验,为您提供专业的成都网站建设、全网整合营销推广及网站设计开发服务!
1、Idea 本地独立模式运行 MapReduce
1.1、解压 Hadoop 和设置环境变量
将 Hadoop 解压本地目录,例如 C:\Hadoop
设置环境变量:
HADOOP_HOME 指向 Hadoop 解压目录
HADOOP_USER_NAME : 用户名,Hadoop 运行的用户名(下一节 远程提交需要,跟 HDFS 集群所用的一样)
PATH:添加指向 HADOOP_HOME\bin 和 HADOOP_HOME\sbin 的值
重要:Windows 系统:Windows 运行 Hadoop 需要 winutils.exe 和 hadoop.dll 这两个文件:
https://github.com/cdarlint/winutils 下载对应 Hadoop 版本的
hadoop.dll 复制到 C:\Windows\System32
winutils.exe 复制到 HADOOP_HOME\bin
1.2、新建项目
示例项目在 src/hadoop
选择 Gradle 或者 Maven 等构建工具,添加如下依赖:version 对应 Hadoop 的版本。
// https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-common compile group: 'org.apache.hadoop', name: 'hadoop-common', version: '3.2.1' // https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-client compile group: 'org.apache.hadoop', name: 'hadoop-client', version: '3.2.1'
日志输出配置:项目/src/main/resource/log4j.properties
log4j.appender.A1.Encoding=UTF-8
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d{ABSOLUTE} | %-5.5p | %-16.16t | %-32.32c{1} | %-32.32C %4L | %m%n新建:org.xiao.hadoop.chapter01.WordCount.class :
public class WordCount {
public static class WordCountMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable ONE = new IntWritable(1);
private final Text word = new Text();
@Override
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
// 按照空格切割字符串,一行一行输入的
// Context 将输出内容写入 《Hadoop 权威指南》P25
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, ONE);
}
}
}
public static class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private final IntWritable result = new IntWritable();
@Override
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
// 读取配置文件
Configuration conf = new Configuration();
// 设置任务名称
Job job = Job.getInstance(conf, "WordCount");
// 设置运行的 jar 包,通过 class 的形式 TODO:验证直接设置 jar 包
job.setJarByClass(WordCount.class);
// Map 的类,
job.setMapperClass(WordCountMapper.class);
// Reducer 类的设置
// Combiner 是非必须的,属于优化方案,用于找出每个 Map 的结果,然后再通过 Reducer 再次聚合
// 作用是减少每个 map 输出结果量,有他没他最终结果是一样的 ,《Hadoop 权威指南》中文第三版 P35
job.setCombinerClass(WordCountReducer.class);
job.setReducerClass(WordCountReducer.class);
// 设置输出的 key--value 的类型,Hadoop 的 org.apache.hadoop.io 包提供了一套可优化的网络序列化传输基本类型。
// 并不直接使用 Java 的内嵌类型
// Text 相当于 String
job.setOutputKeyClass(Text.class);
// IntWritable 相当于 Integer
job.setOutputValueClass(IntWritable.class);
// 设置输入文件的路径,可以直接指定或者通过传入参数
FileInputFormat.addInputPath(job, new Path("input/chapter01/WordCount"));
// 设置输出文件的存放路径
FileOutputFormat.setOutputPath(job, new Path("output/chapter01/WordCount"));
// true 表示打印 job 和 Task 的运行日志,如果正常运行结束则返回零
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
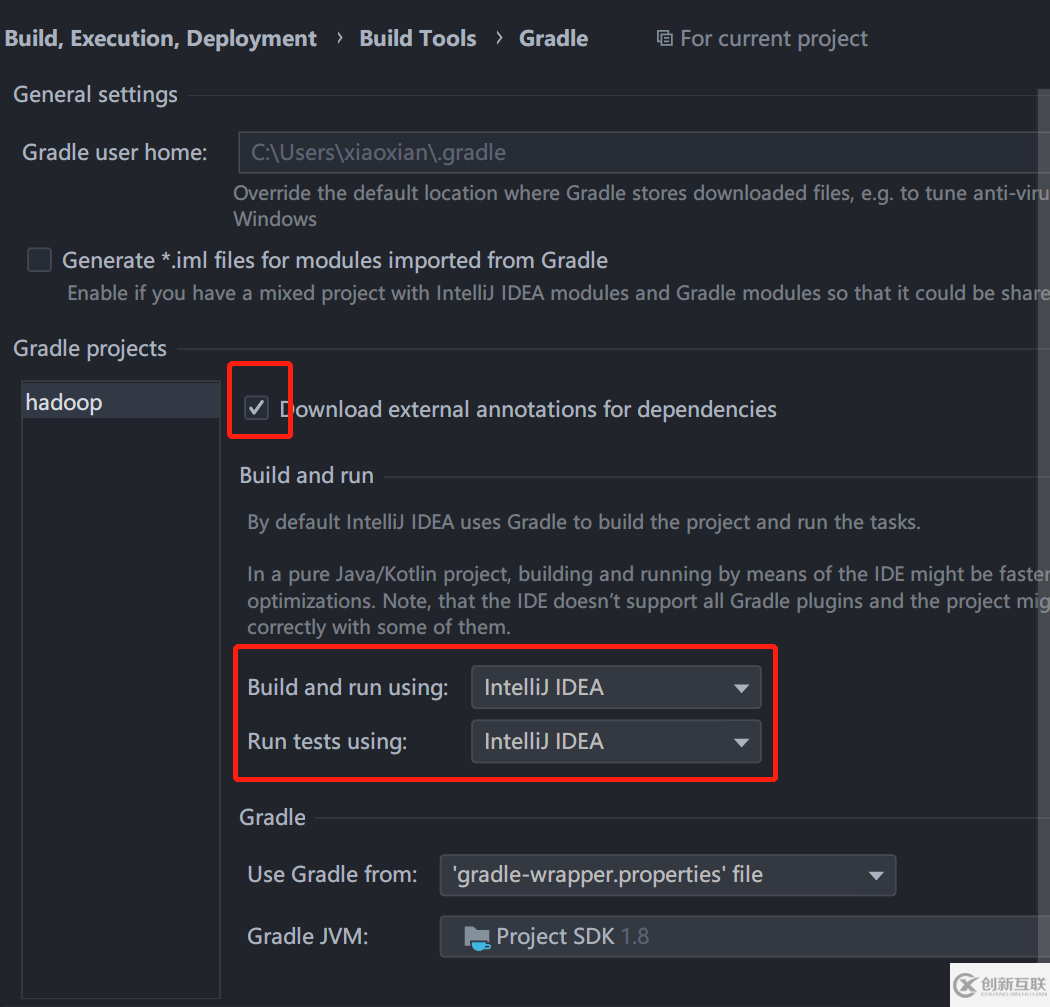
}如果是 Windows 系统和 Gradle 项目,需要打开 Idea 设置,将 Gradle 的设置如下,不然日志会乱码
Hadoop 输入文件:input/chapter01/WordCount/word.txt
hello world hello hadoop hello bigdata hello hadoop and bigdata
Hadoop 输出文件夹,output/chapter01/WordCount 运行程序前需要删除。
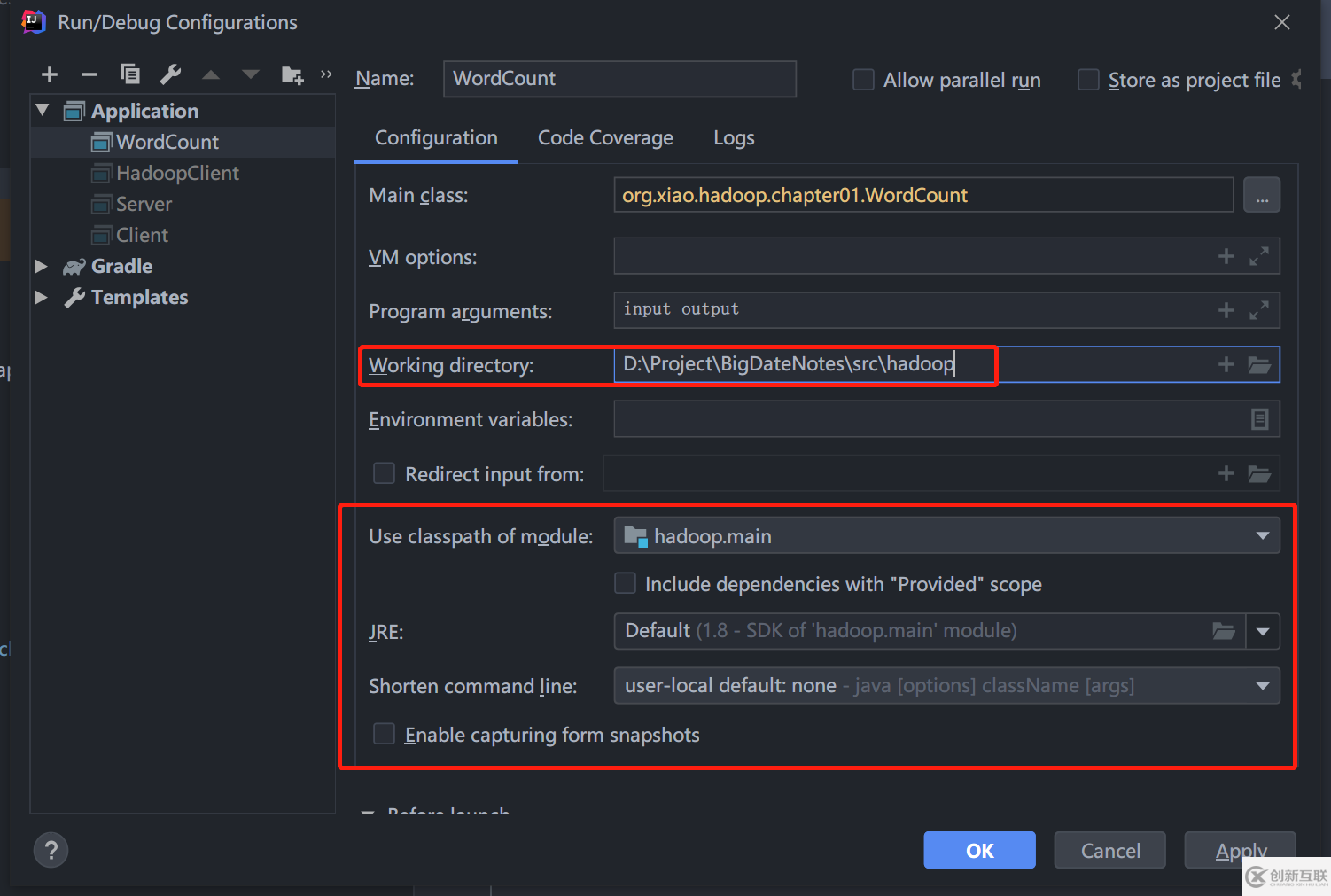
在 WordCount.class 按 Ctrl + Shift + F10 直接运行程序即可。项目运行配置:
输出示例:src/hadoop/output/chapter01/WordCount/part-r-00000,没有错误。
and 1 bigdata 2 hadoop 2 hello 4 world 1
2、Idea 远程提交 MapReduce
前提已经完成:Hadoop 安装和配置
2020.05.07 更新:追踪源码发现,这只是使用集群中的文件,并没有提交到集群。见 2.5 真远程提交。
2.1、在上一节的基础上,增加如下配置:
文件: resource/core-site.xml
<configuration> <property> <!-- URI 定义主机名称和 namenode 的 RPC 服务器工作的端口号 --> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> <!-- <property> 这个可以设置为本地路径,但没有什么用,这个路径是 Hadoop 集群用的 Hadoop 临时目录,默认是系统的临时目录下,/tmp/hadoop-${username} 下 <name>hadoop.tmp.dir</name> <value>/home/xian/hadoop/cluster</value> </property> --> </configuration>
文件 resource/mapred-site.xml
<configuration> <!-- 远程提交到 Linux 的平台上 --> <property> <name>mapred.remote.os</name> <value>Linux</value> <description>Remote MapReduce framework's OS, can be either Linux or Windows</description> </property> <!--允许跨平台提交 解决 /bin/bash: line 0: fg: no job control --> <property> <name>mapreduce.app-submission.cross-platform</name> <value>true</value> </property> </configuration>
hdfs-site.xml 和 yarn-site.xml 可以直接复制集群上的配置文件。
2.2、安装 BigDataTools 插件
安装 Idea 官方的 BigDataTools插件,配置连接到 HDFS 集群。可以方便的上传、下载、删除文件。
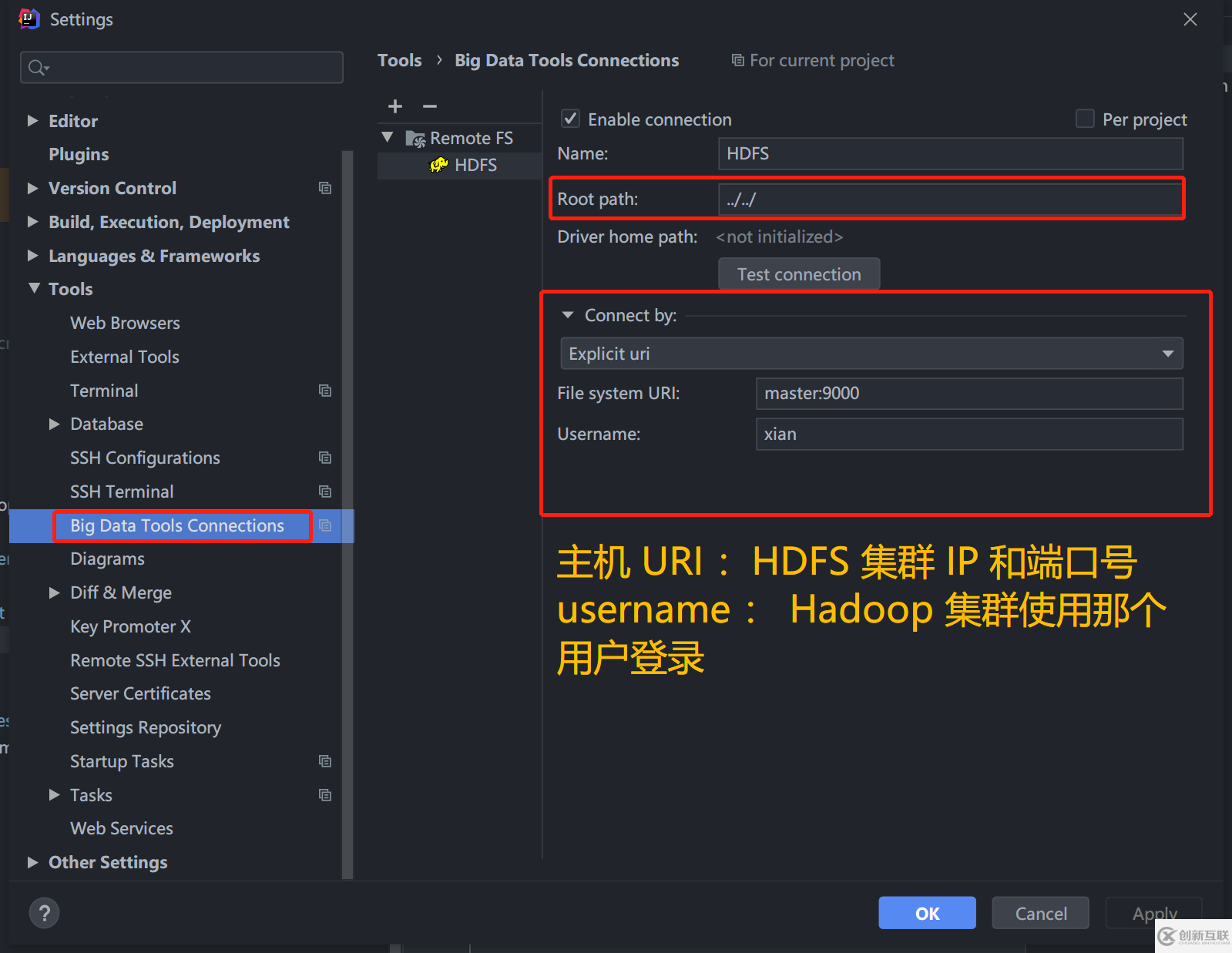
2.3、修改一下代码
Map 输入文件路径可以是绝对路径,也可以是相对路径。
// 读取配置文件,自动读取 resource 的那几个 xml
Configuration conf = new Configuration();
// 省略其他
// 设置输入文件的路径,可以直接指定或者通过传入参数
// new Path(arg[0]) 通过 Programmer argument 传入
// Path("input") 等于 hdfs://master:9000/user/{HADOOP_USER_NAME}/input
FileInputFormat.addInputPath(job, new Path("input"));
// 设置输出文件的存放路径
FileOutputFormat.setOutputPath(job, new Path("output"));将 input/chapter01/WordCount/word.txt 上传到 hdfs://master:9000/user/{HADOOP_USER_NAME}/input,(上文:解压 Hadoop 和设置环境变量)
2.4、运行项目
如果已经存在 output 文件夹,需要先删除了。
同样,按 Ctrl + Shift + F10 运行项目,结果存储在 hdfs://master:9000/user/{HADOOP_USER_NAME}/output/part-r-00000 中。
2.5、真远程提交方式
首先,使用 Gradle 将代码打包成 jar 文件,修改文件 src/hadoop/build.gradle,添加
dependencies {
// 省略依赖
}
// 支持中文编码和注释
tasks.withType(JavaCompile) {options.encoding = "UTF-8"}使用 Gradle 打包成 jar ,点击右边 框起来的 jar 命令,左边是生产的 jar 文件。
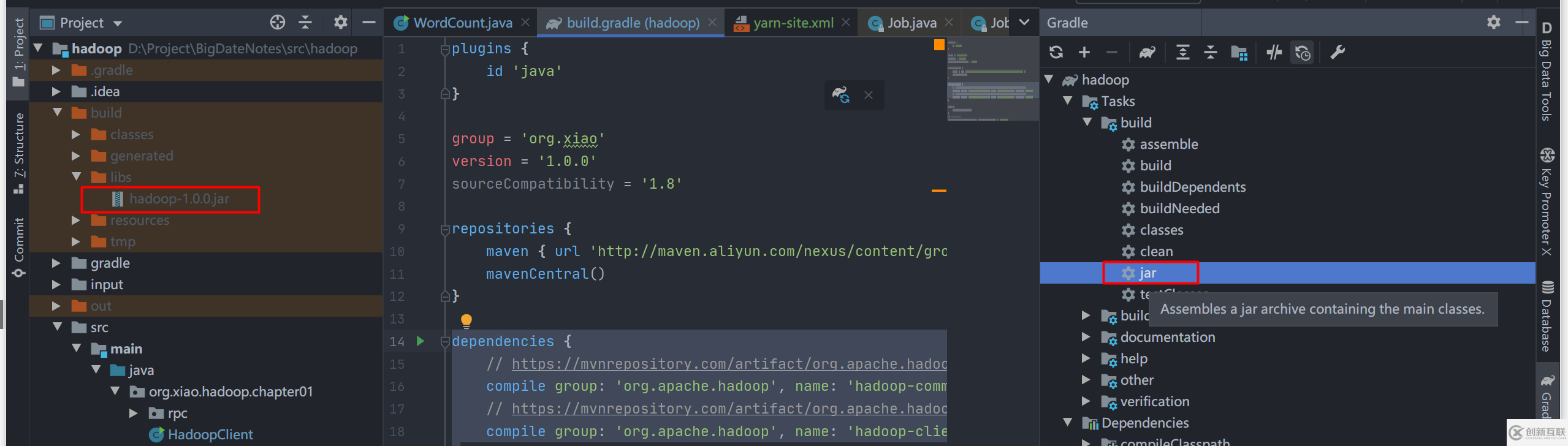
将 jar 提交到远程,以下两种方式:
方式一:文件 src/hadoop/src/main/java/org/xiao/hadoop/chapter01/WordCount.java 读取配置文件的地方
// 读取配置文件
Configuration conf = new Configuration();
conf.set("mapreduce.job.jar","D:/Project/BigDateNotes/src/hadoop/build/libs/hadoop-1.0.0.jar");或者 mapred-site.xml 文件添加,注意不管方式一还是方式二,都必须指定 :mapreduce.framework.name 为 yarn。
<configuration> <property> <!-- 使用 Yarn Windows 下远程提交去掉这个 https://www.oschina.net/question/2478160_2231358 会导致找不 Map Reduce 类,原因是远程提交,job.setJarByClass 失效 --> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <!-- 设置提交的 jar 文件路径 方式二 --> <name>mapreduce.job.jar</name> <value>D:/Project/BigDateNotes/src/hadoop/build/libs/hadoop-1.0.0.jar</value> </property> </configuration>
提交运行就行了
小结:
Window 下运行 Hadoop 需要 winutils.exe 和 hadoop.dll
推荐使用构建工具如 Maven、Gradle 管理 Hadoop 依赖
Windows 下 需要设置 Gradle 的 build and run using、tests run using 为 IDEA(因为中文注释和终端输出乱码问题)
Idea 远程提交需要设置 mapred.remote.os,mapreduce.app-submission.cross-platform,mapreduce.job.jar 这三个配置。
关于IDEA 中怎么运行MapReduce 程序问题的解答就分享到这里了,希望以上内容可以对大家有一定的帮助,如果你还有很多疑惑没有解开,可以关注创新互联行业资讯频道了解更多相关知识。
分享标题:IDEA中怎么运行MapReduce程序
转载来源:https://www.cdcxhl.com/article18/jdhjgp.html
成都网站建设公司_创新互联,为您提供网站排名、静态网站、网站导航、外贸建站、用户体验、企业建站
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 佛山网站制作中域名注册的问题 2022-11-30
- 域名注册中的常见问题 2022-11-16
- 网站域名注册-域名注册应该注意哪些事项? 2016-11-09
- 价格不是关键因素 网站建设前域名注册绝非小事 2022-05-20
- 网站开发有哪些流程步骤?先注册域名吗 2015-01-23
- 网站域名注册5个问题 2021-09-09
- 注册域名,网站域名注册 2023-03-28
- 成都网站制作中域名注册的问题 2016-11-16
- 国际域名注册要实名认证了? 2014-02-21
- 域名注册哪家靠谱 2022-07-13
- 关于选择便宜域名注册商的技巧 2021-11-11
- 域名选择技巧:地方网站域名注册的一点建议 2022-06-03