spark2.2.0高可用搭建-创新互联
一、概述
让客户满意是我们工作的目标,不断超越客户的期望值来自于我们对这个行业的热爱。我们立志把好的技术通过有效、简单的方式提供给客户,将通过不懈努力成为客户在信息化领域值得信任、有价值的长期合作伙伴,公司提供的服务项目有:申请域名、网络空间、营销软件、网站建设、黄石网站维护、网站推广。1.实验环境基于以前搭建的haoop HA;
2.spark HA所需要的zookeeper环境前文已经配置过,此处不再重复。
3.所需软件包为:scala-2.12.3.tgz、spark-2.2.0-bin-hadoop2.7.tar
4.主机规划
bd1 bd2 bd3 | Worker |
bd4 bd5 | Master、Worker |
二、配置Scala
1.解压并拷贝
[root@bd1 ~]# tar -zxf scala-2.12.3.tgz [root@bd1 ~]# cp -r scala-2.12.3 /usr/local/
2.配置环境变量
[root@bd1 ~]# vim /etc/profile export SCALA_HOME=/usr/local/scala export PATH=:$SCALA_HOME/bin:$PATH [root@bd1 ~]# source /etc/profile
3.验证
[root@bd1 ~]# scala -version Scala code runner version 2.12.3 -- Copyright 2002-2017, LAMP/EPFL and Lightbend, Inc.
三、配置Spark
1.解压并拷贝
[root@bd1 ~]# tar -zxf spark-2.2.0-bin-hadoop2.7.tgz [root@bd1 ~]# cp spark-2.2.0-bin-hadoop2.7 /usr/local/spark
2.配置环境变量
[root@bd1 ~]# vim /etc/profile export SCALA_HOME=/usr/local/scala export PATH=:$SCALA_HOME/bin:$PATH [root@bd1 ~]# source /etc/profile
3.修改spark-env.sh #文件不存在需要拷贝模板
[root@bd1 conf]# vim spark-env.sh export JAVA_HOME=/usr/local/jdk export HADOOP_HOME=/usr/local/hadoop export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop export SCALA_HOME=/usr/local/scala export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=bd4:2181,bd5:2181 -Dspark.deploy.zookeeper.dir=/spark" export SPARK_WORKER_MEMORY=1g export SPARK_WORKER_CORES=2 export SPARK_WORKER_INSTANCES=1
4.修改spark-defaults.conf #文件不存在需要拷贝模板
[root@bd1 conf]# vim spark-defaults.conf spark.master spark://master:7077 spark.eventLog.enabled true spark.eventLog.dir hdfs://master:/user/spark/history spark.serializer org.apache.spark.serializer.KryoSerializer
5.在HDFS文件系统中新建日志文件目录
hdfs dfs -mkdir -p /user/spark/history hdfs dfs -chmod 777 /user/spark/history
6.修改slaves
[root@bd1 conf]# vim slaves bd1 bd2 bd3 bd4 bd5
四、同步到其他主机
1.使用scp同步Scala到bd2-bd5
scp -r /usr/local/scala root@bd2:/usr/local/ scp -r /usr/local/scala root@bd3:/usr/local/ scp -r /usr/local/scala root@bd4:/usr/local/ scp -r /usr/local/scala root@bd5:/usr/local/
2.同步Spark到bd2-bd5
scp -r /usr/local/spark root@bd2:/usr/local/ scp -r /usr/local/spark root@bd3:/usr/local/ scp -r /usr/local/spark root@bd4:/usr/local/ scp -r /usr/local/spark root@bd5:/usr/local/
五、启动集群并测试HA
1.启动顺序为:zookeeper-->hadoop-->spark
2.启动spark
bd4:
[root@bd4 sbin]# cd /usr/local/spark/sbin/ [root@bd4 sbin]# ./start-all.sh starting org.apache.spark.deploy.master.Master, logging to /usr/local/spark/logs/spark-root-org.apache.spark.deploy.master.Master-1-bd4.out bd4: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-bd4.out bd2: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-bd2.out bd3: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-bd3.out bd5: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-bd5.out bd1: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-bd1.out [root@bd4 sbin]# jps 3153 DataNode 7235 Jps 3046 JournalNode 7017 Master 3290 NodeManager 7116 Worker 2958 QuorumPeerMain
bd5:
[root@bd5 sbin]# ./start-master.sh starting org.apache.spark.deploy.master.Master, logging to /usr/local/spark/logs/spark-root-org.apache.spark.deploy.master.Master-1-bd5.out [root@bd5 sbin]# jps 3584 NodeManager 5602 RunJar 3251 QuorumPeerMain 8564 Master 3447 DataNode 8649 Jps 8474 Worker 3340 JournalNode
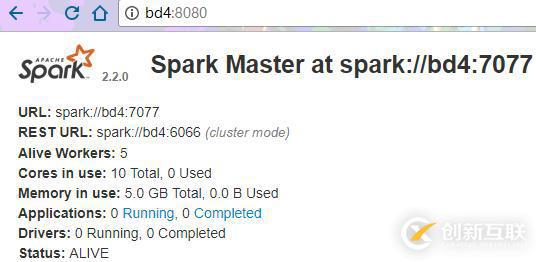
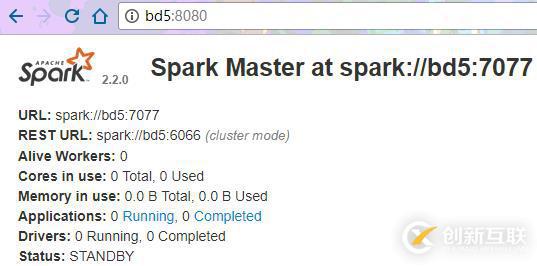
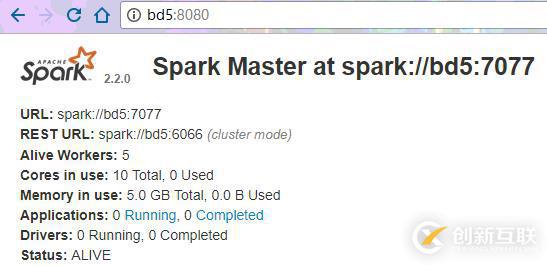
3.停掉bd4的Master进程
[root@bd4 sbin]# kill -9 7017 [root@bd4 sbin]# jps 3153 DataNode 7282 Jps 3046 JournalNode 3290 NodeManager 7116 Worker 2958 QuorumPeerMain

五、总结
一开始时想把Master放到bd1和bd2上,但是启动Spark后发现两个节点上都是Standby。然后修改配置文件转移到bd4和bd5上,才顺利运行。换言之Spark HA的Master必须位于Zookeeper集群上才能正常运行,即该节点上要有JournalNode这个进程。
另外有需要云服务器可以了解下创新互联scvps.cn,海内外云服务器15元起步,三天无理由+7*72小时售后在线,公司持有idc许可证,提供“云服务器、裸金属服务器、高防服务器、香港服务器、美国服务器、虚拟主机、免备案服务器”等云主机租用服务以及企业上云的综合解决方案,具有“安全稳定、简单易用、服务可用性高、性价比高”等特点与优势,专为企业上云打造定制,能够满足用户丰富、多元化的应用场景需求。
当前名称:spark2.2.0高可用搭建-创新互联
网站链接:https://www.cdcxhl.com/article18/csgidp.html
成都网站建设公司_创新互联,为您提供企业建站、小程序开发、网站导航、移动网站建设、搜索引擎优化、微信小程序
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 微信公众号代运营需要做哪些工作? 2022-08-24
- 教您怎样创建微信公众号 2021-12-06
- 『微信公众号运营用户体验』微信公众号如何与粉丝互动? 2022-06-21
- 微信公众号的隐藏功能你都知道吗 2021-06-02
- 解析:微信公众号营销优势 2016-01-21
- 微信公众号开发的申请流程-大连微信开发 2022-07-15
- 微信公众号添加不了超链接的原因是什么? 2014-05-23
- 利用函数解释微信公众号文章打开率 2022-05-27
- 如何做好微信公众号的内容规划 2022-07-28
- 微信公众号开发消息推送功能流程,微信小程序开发消息发送与恢复功能说明 2021-05-20
- 如何设计开发APP,微信公众号和小程序 2023-03-17
- 微信公众号,推出的视频报警功能,赶紧进来围观 2013-10-29