hadoop~大数据-创新互联
hadoop是一个分布式文件系统(Hadoop Distributed File System)HDFS。Hadoop是一个能够对大量数据进行分布式处理的软件框架。 Hadoop 以一种可靠、高效、可伸缩的方式进行数据处理。Hadoop 是可靠的,因为它假设计算元素和存储会失败,因此它维护多个工作数据副本,确保能够针对失败的节点重新分布处理。Hadoop带有用Java语言编写的框架。
成都创新互联主要从事网站设计、网站制作、网页设计、企业做网站、公司建网站等业务。立足成都服务广西,10年网站建设经验,价格优惠、服务专业,欢迎来电咨询建站服务:18980820575Hadoop的master节点包括名称节点、从属名称节点和 jobtracker 守护进程以及管理集群所用的实用程序和浏览器。slave节点包括 tasktracker 和数据节点.主节点包括提供 Hadoop 集群管理和协调的守护进程,而从节点包括实现Hadoop 文件系统(HDFS)存储功能和 MapReduce 功能(数据处理功能)的守护进程。
Namenode 是 Hadoop 中的主服务器,通常在 HDFS 实例中的单独机器上运行的软件,它管理文件系统名称空间和对集群中存储的文件的访问。每个 Hadoop 集群中可以找到一个 namenode和一个secondary namenode。。当外部客户机发送请求要求创建文件时,NameNode 会以块标识和该块的第一个副本的 DataNode IP 地址作为响应。这个 NameNode 还会通知其他将要接收该块的副本的 DataNode。
Datanode,hadoop 集群包含一个 NameNode 和大量 DataNode。DataNode 通常以机架的形式组织,机架通过一个交 换机将所有系统连接起来。DataNode 响应来自 HDFS 客户机的读写请求。它们还响应来自 NameNode 的创建、删除和复制块的命令。
JobTracker是一个master服务,软件启动之后JobTracker接收Job,负责调度Job的每一个子任务task运行于TaskTracker上,并监控它们,如果发现有失败的task就重新运行它。
TaskTracker是运行在多个节点上的slaver服务。TaskTracker主动与JobTracker通信,接收作业,并负责直接执行每一个任务。TaskTracker都需要运行在HDFS的DataNode上.
NameNode、Secondary ,NameNode、JobTracker运行在Master节点上,而在每个Slave节点上,部署一个DataNode和TaskTracker,以便 这个Slave服务器运行的数据处理程序能尽可能直接处理本机的数据。
server2.example.com 172.25.45.2 (master)
server3.example.com 172.25.45.3 (slave)
server4.example.com 172.25.45.4 (slave)
server5.example.com 172.25.45.5 (slave)
hadoop传统版的配置:
server2,server3,server4和server5添加hadoop用户:
useradd -u 900 hadoop
echo westos | passwd --stdin hadoop
server2:
sh jdk-6u32-linux-x64.bin ##安装JDK
mv jdk1.6.0_32/ /home/hadoop/java
mv hadoop-1.2.1.tar.gz /home/hadoop/
su - hadoop
vim .bash_profile
export JAVA_HOME=/home/hadoop/java export CLASSPATH=.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib export PATH=$PATH:$HOME/bin:$JAVA_HOME/bin
source .bash_profile
tar zxf hadoop-1.1.2.tar.gz ##配置hadoop单节点
ln -s hadoop-1.1.2 hadoop
cd /home/hadoop/hadoop/conf
vim hadoop-env.sh
export JAVA_HOME=/home/hadoop/java
cd ..
mkdir input
cp conf/*.xml input/
bin/hadoop jar hadoop-examples-1.1.2.jar
bin/hadoop jar hadoop-examples-1.1.2.jar grep input output 'dfs[a-z.]+'
cd output/
cat *
1 dfsadmin
设置master到slave端无密码登陆:
server2:
su - hadoop
ssh-keygen
ssh-copy-id localhost
ssh-copy-id 172.25.45.3
ssh-copy-id 172.25.45.4
cd /home/hadoop/hadoop/conf
vim core-site.xml ##指定 namenode
<property> <name>fs.default.name</name> <value>hdfs://172.25.45.2:9000</value> </property>
vim mapred-site.xml ##指定 jobtracker
<configuration> <property> <name>mapred.job.tracker</name> <value>172.25.45.2:9001</value> </property> <configuration>
vim hdfs-site.xml ##指定文件保存的副本数
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <configuration>
cd ..
bin/hadoop namenode -format ##格式化成一个新的文件系统
ls /tmp
hadoop-hadoop hsperfdata_hadoop hsperfdata_root yum.log
bin/start-dfs.sh ##启动hadoop进程
jps

bin/start-mapred.sh
jps

在浏览器中打开:172.25.45.2:50030
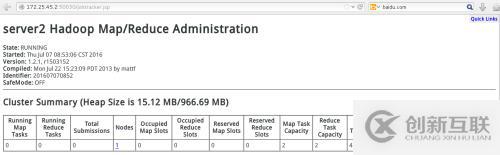
打开172.25.45.2:50070
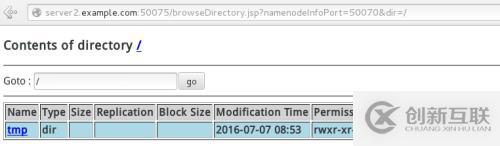
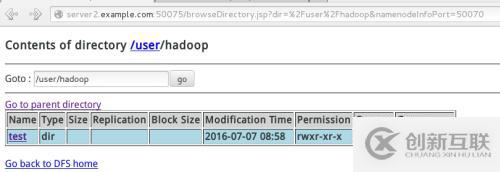
bin/hadoop fs -put input test ##给分布式文件系统考入新建的文件
bin/hadoop jar hadoop-examples-1.2.1.jar wordcount output
同时在网页中

查看网页中上传的文件:
bin/hadoop fs -get output test
cat test/*
rm -fr test/ ##删除下载的文件
2. server2:
共享文件系统:
su - root
yum install nfs-utils -y
/etc/init.d/rpcbind start
/etc/init.d/nfs start
vim /etc/exports
/home/hadoop *(rw,anonuid=900,anongid=900)
exportfs -rv
exportfs -v
server3和server4:
yum install nfs-utils -y
/etc/init.d/rpcbind start
showmount -e 172.25.45.2 ##
Export list for 172.25.45.2:
/home/hadoop *
mount 172.25.45.2:/home/hadoop /home/hadoop/
df


server2:
su - hadoop
cd hadoop/conf
vim hdfs-site.xml
<configuration> <property> <name>dfs.replication</name> <value>2</value> </property> </configuration>
vim slaves ##slave端的ip
172.25.45.3 172.25.45.4
vim masters ##master端的ip
172.25.45.2
提示:##如果还有之前的进程开着,必须先关闭,才能再进行格式化,保证jps没有什么进程运行
关闭进程的步骤
bin/stop-all.sh ##执行完之后,有时tasktracker,datanode会开着,所以要关闭它们
bin/hadoop-daemon.sh stop tasktracker
bin/hadoop-daemon.sh stop datanode
以hadoop用户的身份删除/tmp里的文件,没有权限的文件就留着
su - hadoop
bin/hadoop namenode -format
bin/start-dfs.sh
bin/start-mapred.s
bin/hadoop fs -put input test ##
bin/hadoop jar hadoop-examples-1.2.1.jar grep test output 'dfs[a-z.]+' ##
一边上传一边在浏览器中打开172.25.45.2:50030中观察会发现有正在上传的文件
su - hadoop
bin/hadoop dfsadmin -report
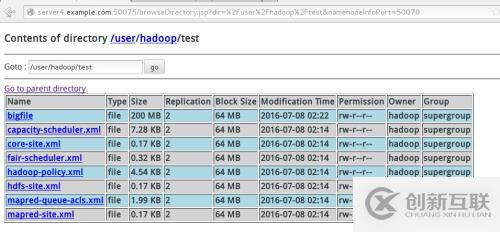
dd if=/dev/zero of=bigfile bs=1M count=200
bin/hadoop fs -put bigfile test
在浏览器中打开172.25.45.2:50070
3.新加server5.example.com 172.25.45.5 作为新的slave端:
su - hadoop
yum install nfs-utils -y
/etc/init.d/rpcbind start
useradd -u 900 hadoop
echo westos | passwd --stdin hadoop
mount 172.25.45.2:/home/hadoop/ /home/hadoop/
su - hadoop
vim hadoop/conf/slaves
172.25.45.3 172.25.45.4 172.25.45.5
cd /home/hadoop/hadoop
bin/hadoop-daemon.sh start datanode
bin/hadoop-daemon.sh start tasktracker
jps
删除一个slave端:
server2:
su - hadoop
cd /home/hadoop/hadoop/conf
vim mapred-site.xml
<property> <name>dfs.hosts.exclude</name> <value>/home/hadoop/hadoop/conf/datanode-excludes</value> </property>
vim /home/hadoop/hadoop/conf/datanode-excludes
172.25.45.3 ##删除172.25.45.3不作为slave端
cd /home/hadoop/hadoop
bin/hadoop dfsadmin -refreshNodes ##刷新节点
bin/hadoop dfsadmin -report ##查看节点状态,会发现server3上的数据转移到serve5上
在server3上:
su - hadoop
bin/stop-all.sh
cd /home/hadoop/hadoop
bin/hadoop-daemon.sh stop tasktracker
bin/hadoop-daemon.sh stop datanode
server2:
vim /home/hadoop/hadoop/conf/slaves
172.25.45.4
172.25.45.5
4. 配置新版的hadoop:
server2:
su - hadoop
cd /home/hadoop
tar zxf jdk-7u79-linux-x64.tar.gz
ln -s jdk1.7.0_79/ java
tar zxf hadoop-2.6.4.tar.gz
ln -s hadoop-2.6.4 hadoop
cd /home/hadoop/hadoop/etc/hadoop
vim hadoop-env.sh
export JAVA_HOME=/home/hadoop/java export HADOOP PREFIX=/home/hadoop/hadoop
cd /home/hadoop/hadoop
mkdir inp
cp etc/hadoop/*.xml input
tar -tf hadoop-native-64-2.6.0.tar
tar -xf hadoop-native-64-2.6.0.tar -C hadoop/lib/native/
cd /home/hadoop/hadoop
rm -fr output/
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.4.jar grep input output 'dfs[a-z.]+'
cd /hone/hadoop/hadoop/etc/hadoop/
vim slaves
172.25.45.3 172.25.45.4
vim core-site.xm
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://172.25.45.2:9000</value> </property> </configuration>
vim mapred-site.xml
<configuration> <property> <name>mapred.job.tracker</name> <value>172.25.45.2:9001</value> </property> <configuration>
vim hdfs-site.xml
<configuration> <property> <name>dfs.replication</name> <value>2</value> </property> </configuration>
cd /home/hadoop/hadoop
bin/hdfs namenode -format
sbin/start-dfs.sh
jps
bin/hdfs dfs -mkdir /user/hadoop ##要上传的文件,必须在上传之前新建出其目录
bin/hdfs dfs -put input/ test
rm -fr input/
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.4.jar grep test output 'dfs[a-z.]+'
bin/hdfs dfs -cat output/*
1dfsadmin
在浏览器中打开172.25.45.2:50070
另外有需要云服务器可以了解下创新互联scvps.cn,海内外云服务器15元起步,三天无理由+7*72小时售后在线,公司持有idc许可证,提供“云服务器、裸金属服务器、高防服务器、香港服务器、美国服务器、虚拟主机、免备案服务器”等云主机租用服务以及企业上云的综合解决方案,具有“安全稳定、简单易用、服务可用性高、性价比高”等特点与优势,专为企业上云打造定制,能够满足用户丰富、多元化的应用场景需求。
分享标题:hadoop~大数据-创新互联
地址分享:https://www.cdcxhl.com/article18/coccgp.html
成都网站建设公司_创新互联,为您提供网站建设、软件开发、外贸网站建设、网站营销、用户体验、服务器托管
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 服务器托管可以选择双线机房吗? 2022-10-06
- 为何服务器托管成为企业的首选? 2022-10-05
- 服务器托管网站延迟怎么办? 2022-10-09
- 关于服务器托管四大秘诀,你知道吗? 2022-10-03
- 香港服务器托管费用贵吗?香港服务器托管有哪些优势? 2022-10-12
- 服务器中毒处理 2022-05-25
- 服务器托管的好处和优势 2022-10-13
- 企业选择服务器托管的5个优势 2022-08-08
- 提供济南服务器托管,创新互联靠什么来实现? 2021-03-10
- 服务器托管时怎么判断是否死机 2022-10-03
- 服务器托管与虚拟主机租用有什么区别? 2022-06-19
- 服务器托管首要选对机房 2022-10-06