哪种情况下需要使用robots.txt
在优化网站过程中,有一些场景中,我们是不想让蜘蛛来抓取网站内容的,比如:网站中重要及私密的内容、后台的数据、测试阶段的网站,这些都是我们不想展示给用户看的,所以就没必要让这些内容收录,就需要禁止蜘蛛抓取。网站建设★网站设计★网站制作★网页设计-800元全包;企业网络推广☆网站优化☆seo☆关键词排名☆百度快照-2200元全年展示;做网站优化排名-网站建设公司
创新互联公司是一家集网站建设,云安企业网站建设,云安品牌网站建设,网站定制,云安网站建设报价,网络营销,网络优化,云安网站推广为一体的创新建站企业,帮助传统企业提升企业形象加强企业竞争力。可充分满足这一群体相比中小企业更为丰富、高端、多元的互联网需求。同时我们时刻保持专业、时尚、前沿,时刻以成就客户成长自我,坚持不断学习、思考、沉淀、净化自己,让我们为更多的企业打造出实用型网站。
另外还有一种情况,很多电子商务的网站,有很多通过条件去筛选、过滤的页面,这些页面通常没有什么意义,我们也不希望浪费蜘蛛的抓取份额,所以也要禁止蜘蛛的抓取。
如何禁止蜘蛛抓取特定的页面呢?
robots(蜘蛛协议)是其中一种方式,也是最常用的一种。
robots是一个纯文本文件,用于声明该网站中不想被蜘蛛访问的部分,或者指定蜘蛛抓取的部分。
当蜘蛛访问一个站点时,它会首先检查该站点是否存在robots.txt 文件,如果找到,蜘蛛就会按照该文件中的内容来确定抓取的范围;如果该文件不存在,那么蜘蛛就会沿着链接直接抓取。
即,只有在需要禁止抓取某些内容时,写robots.txt才有意义。
robots.txt 文件放置在一个站点的根目录下,而且文件名必须全部小写,正确的写法是robots.txt。
要查看某网站的robots.txt文件,在浏览器中输入的网址:
http:/www.xxx.com/robots.txt
其中www.xxx.com是要查询网站的域名。
一、robots.txt的语法
robots.txt文件的常用语法有3种,分别是User-agent、Allow、Disallow,下面讲解3种语法的具体用法。
(1) User-agent
指定robots.txt 中的规则针对哪个搜索引擎蜘蛛(每种搜索引擎的蜘蛛都不一样)。
针对所有搜索引擎蜘蛛的写法是User-agent:*,通配符*代表所有搜索引擎。只适用于百度蜘蛛的正确写法是User-agent:Baiduspider。不同的搜索引擎,其蜘蛛名称也不相同。
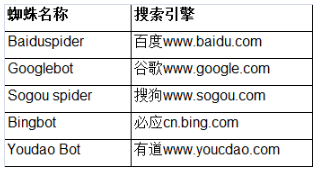
不同搜索引擎的蜘蛛名
(2 )Allow
允许搜索引擎蜘蛛抓取某些文件。例如允许蜘蛛访问网站中的/a/目录,正确写法是Allow: /a/。
$: 表示匹配URL结尾的字符。例如允许搜索引擎抓蜘蛛取以.htm为后缀的URL,写法是Allow:.htm$。
(3) Disallow
告诉搜索引擎不要抓取某些文件或目录。例如禁止蜘蛛抓取/admin/目录的写法是 Disallow:/admin/。
禁止的目录或文件必须分开写,每个一行,例如禁止所有的搜索引擎蜘蛛抓取/a/、/b/、/c/目录,正确的写法是:
User-agent:
Disallow:/a/
Disallow:/b/
Disallow:/c/
在网站优化中,SEOer需要熟练掌握robots.txt的基本语法。下面分享一些常见的robots.txt语法使用案例,如图所示。
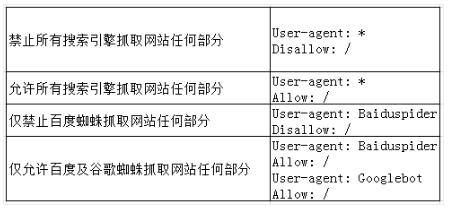
二、robots.txt应用
robots.txt 文件的一个用法是在robots.txt 文件中指定 sitemap 的位置。具体的用法是 sitemap:http://www.matuzi.cn/sitemap.xml,这样就告诉搜索引擎蜘蛛这个页面是网站地图。
robots.txt 文件是搜索引擎蜘蛛进入网站后访问的第一个文件,在编写时确实有很多需要注意的地方,如果日常使用中不注意语法的正确使用,有些语句可能就发挥不了应有的作用,会影响搜索引擎蜘蛛对网站的访问,因此要正确编写。
对于SEOer来讲,在优化网站过程中,当发现网站中有隐私文件需要屏蔽搜索引擎蜘蛛抓取时,可以设置robots.txt 屏蔽搜索引擎蜘蛛抓取这些隐私文件。如果网站只是一般的企业展示网站,可以不添加robots.txt。
三、robots meta标签(更精准的禁止蜘蛛抓取)
如果搜索引擎已经收录网页,而这个网页是我们不想让搜索引擎收录的,robots.txt 文件解决不了这个问题,而robots meta标签却可以解决。
robots.txt 文件主要是限制整个站点或者目录的蜘蛛访问情况,而robots meta标签则主要是针对某个具体的页面。robots meta标签放在页面中,专门用来告诉搜索引擎蜘蛛如何抓取该页的内容。
robots meta标签的基本写法是:
<meta name="robots" content="index.folow>
其中有几项需要特别注意的内容。
(1)在robots meta 标签中,name="robots"表示所有的搜索引擎,也可以针对某个具体的搜索引擎,如针对百度搜索引擎可以写为name="Baiduspider"。
(2)content部分有4个指令选项,以英文逗号“,”隔开,分别是:index、follow、noindex、nofollow。
● index指令告诉搜索引擎蜘蛛可以抓取该页面。
● noindex指令与index指令相反,表示搜索引擎蜘蛛不可以抓取该页面。
● follow 指令表示搜索引擎蜘蛛可以爬行该页面上的链接。
● nofolow指令与follow指令相反,表示搜索引擎蜘蛛不可以爬行该页面上的其他链接。
综上所述,robots meta标签有以下4种组合:
<meta name="robots" content="index,follow">
<meta name="robots" content="noindex,follow">
<meta name="robots" content="index,nofollow">
<meta name="robots" content="noindex,nofollow">
当robots meta 标签的content值为"index,follow"时,表示该页面可以被抓取,该页面上的链接也可以被继续爬行下去,robots meta标签可以简写为:
meta name="robots" content="all"
当robots meta标签的content值为”noindex,nofolow"时,表示该页面不可以被抓取,该页面上的链接也不可以被继续爬行,robots meta标签可以简写为:
meta name="robots" content="none"
robots meta标签是限制某个具体页面的蜘蛛访问情况,因此当发现网站中某个页面需要屏蔽蜘蛛抓取时,可以在该页面的源代码中添加robots meta标签,robots meta标签添加在页面的<head></head>之间。
当然,有时候即使设置了禁止抓取的协议也是没用的,有些搜索引擎就是死皮赖脸要来抓取你,不遵循这些协议,这种情况比较少,遇到的概率也很低,所以现在不必要考虑这种情况。
新闻标题:哪种情况下需要使用robots.txt
文章起源:https://www.cdcxhl.com/article16/dghspdg.html
成都网站建设公司_创新互联,为您提供关键词优化、标签优化、搜索引擎优化、App设计、网站营销、网页设计公司
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 毁掉APP设计的5个致命错误 2022-05-14
- 网站APP设计师如何规避字体版权 2021-06-05
- app设计技巧:国外大师教你四步设计框架 2022-05-29
- app设计技巧:三招解除用户等待焦虑 2022-06-26
- App设计者需要注意的21条禁忌 2016-09-04
- 专业的APP设计师告诉你,怎么做可以让APP更“快”! 2016-11-11
- APP设计易用性的七个要素 2022-06-20
- 手机APP设计制作定律(二) 2016-11-04
- 关于儿童产品的网站APP设计原则 2021-05-11
- APP设计|登录注册模块详解 2022-05-25
- APP设计开发中产品经理岗位有什么重要作用 2020-12-09
- 网站logo和APP设计的图标归类 2021-06-13