怎么用Python来分析红楼梦里的人物关系-创新互联
这篇文章主要介绍了怎么用Python来分析红楼梦里的人物关系,具有一定借鉴价值,感兴趣的朋友可以参考下,希望大家阅读完这篇文章之后大有收获,下面让小编带着大家一起了解一下。
创新互联服务项目包括兴庆网站建设、兴庆网站制作、兴庆网页制作以及兴庆网络营销策划等。多年来,我们专注于互联网行业,利用自身积累的技术优势、行业经验、深度合作伙伴关系等,向广大中小型企业、政府机构等提供互联网行业的解决方案,兴庆网站推广取得了明显的社会效益与经济效益。目前,我们服务的客户以成都为中心已经辐射到兴庆省份的部分城市,未来相信会继续扩大服务区域并继续获得客户的支持与信任!数据准备
红楼梦 TXT 文件一份
金陵十二钗 + 贾宝玉 人物名称列表
人物列表内容如下:
宝玉 nr 黛玉 nr 宝钗 nr 湘云 nr 凤姐 nr 李纨 nr 元春 nr 迎春 nr 探春 nr 惜春 nr 妙玉 nr 巧姐 nr 秦氏 nr
这份列表,同时也是为了做分词时使用,后面的 nr 就是人名的意思。
数据处理
读取数据并加载词典
with open("红楼梦.txt", encoding='gb18030') as f:
honglou = f.readlines()
jieba.load_userdict("renwu_forcut")
renwu_data = pd.read_csv("renwu_forcut", header=-1)
mylist = [k[0].split(" ")[0] for k in renwu_data.values.tolist()]这样,我们就把红楼梦读取到了 honglou 这个变量当中,同时也通过 load_userdict 将我们自定义的词典加载到了 jieba 库中。
对文本进行分词处理并提取
tmpNames = []
names = {}
relationships = {}
for h in honglou:
h.replace("贾妃", "元春")
h.replace("李宫裁", "李纨")
poss = pseg.cut(h)
tmpNames.append([])
for w in poss:
if w.flag != 'nr' or len(w.word) != 2 or w.word not in mylist:
continue
tmpNames[-1].append(w.word)
if names.get(w.word) is None:
names[w.word] = 0
relationships[w.word] = {}
names[w.word] += 1首先,因为文中"贾妃", "元春","李宫裁", "李纨" 混用严重,所以这里直接做替换处理。
然后使用 jieba 库提供的 pseg 工具来做分词处理,会返回每个分词的词性。
之后做判断,只有符合要求且在我们提供的字典列表里的分词,才会保留。
一个人每出现一次,就会增加一,方便后面画关系图时,人物 node 大小的确定。
对于存在于我们自定义词典的人名,保存到一个临时变量当中 tmpNames。
处理人物关系
for name in tmpNames: for name1 in name: for name2 in name: if name1 == name2: continue if relationships[name1].get(name2) is None: relationships[name1][name2] = 1 else: relationships[name1][name2] += 1
对于出现在同一个段落中的人物,我们认为他们是关系紧密的,每同时出现一次,关系增加1.
保存到文件
with open("relationship.csv", "w", encoding='utf-8') as f:
f.write("Source,Target,Weight\n")
for name, edges in relationships.items():
for v, w in edges.items():
f.write(name + "," + v + "," + str(w) + "\n")
with open("NameNode.csv", "w", encoding='utf-8') as f:
f.write("ID,Label,Weight\n")
for name, times in names.items():
f.write(name + "," + name + "," + str(times) + "\n")文件1:人物关系表,包含首先出现的人物、之后出现的人物和一同出现次数
文件2:人物比重表,包含该人物总体出现次数,出现次数越多,认为所占比重越大。
制作关系图表
使用 pyecharts 作图
def deal_graph():
relationship_data = pd.read_csv('relationship.csv')
namenode_data = pd.read_csv('NameNode.csv')
relationship_data_list = relationship_data.values.tolist()
namenode_data_list = namenode_data.values.tolist()
nodes = []
for node in namenode_data_list:
if node[0] == "宝玉":
node[2] = node[2]/3
nodes.append({"name": node[0], "symbolSize": node[2]/30})
links = []
for link in relationship_data_list:
links.append({"source": link[0], "target": link[1], "value": link[2]})
g = (
Graph()
.add("", nodes, links, repulsion=8000)
.set_global_opts(title_opts=opts.TitleOpts(title="红楼人物关系"))
)
return g首先把两个文件读取成列表形式
对于“宝玉”,由于其占比过大,如果统一进行缩放,会导致其他人物的 node 过小,展示不美观,所以这里先做了一次缩放
最后得出的关系图
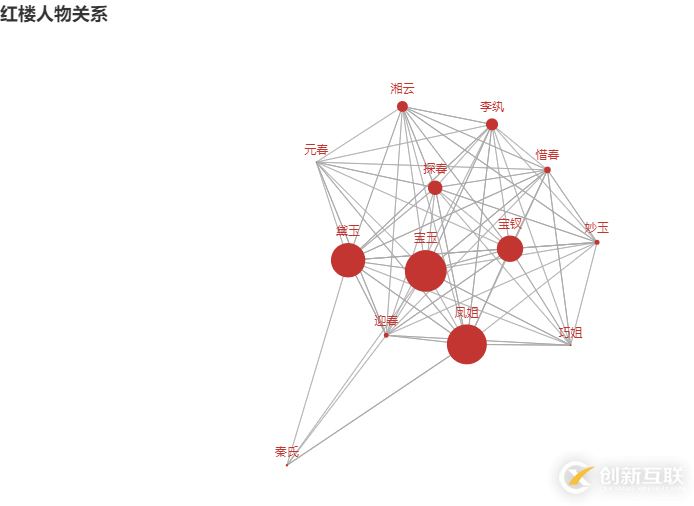
所有代码已经上传至 Github
最后,我还准备了一份更加全面的红楼人物字典,可以在代码仓库中找到-“renwu_total”,感兴趣的小伙伴也可以尝试下,制作一个全人物的关系图。
感谢你能够认真阅读完这篇文章,希望小编分享的“怎么用Python来分析红楼梦里的人物关系”这篇文章对大家有帮助,同时也希望大家多多支持创新互联成都网站设计公司,关注创新互联成都网站设计公司行业资讯频道,更多相关知识等着你来学习!
另外有需要云服务器可以了解下创新互联scvps.cn,海内外云服务器15元起步,三天无理由+7*72小时售后在线,公司持有idc许可证,提供“云服务器、裸金属服务器、网站设计器、香港服务器、美国服务器、虚拟主机、免备案服务器”等云主机租用服务以及企业上云的综合解决方案,具有“安全稳定、简单易用、服务可用性高、性价比高”等特点与优势,专为企业上云打造定制,能够满足用户丰富、多元化的应用场景需求。
分享文章:怎么用Python来分析红楼梦里的人物关系-创新互联
新闻来源:https://www.cdcxhl.com/article16/cescdg.html
成都网站建设公司_创新互联,为您提供关键词优化、微信小程序、App设计、企业网站制作、网站排名、小程序开发
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 面对客户提出的一些不合理的要求 专业的建站公司会这样去做 2022-05-22
- 深圳建站公司创新互联:一文看懂营销型网站建设 2021-04-30
- 怎样辨别成都建站公司好坏? 2022-06-03
- 专业的成都建站公司设计出各种网站 2013-11-19
- 怎样找到一家靠谱的建站公司? 2016-09-16
- 为什么需要创新互联建站公司为你做网站。 2019-07-21
- 为什么要选择成都建站公司? 2023-02-09
- 不同的建站公司为何给出的网站制作价格不一样呢? 2022-07-16
- 企业建站应该如何挑选网站建站公司 2021-02-14
- 网站建设制作高端定制网站大概多少钱为什么有些建站公司报价这么便宜 2021-12-07
- 不同的营销型网站建站公司报价为何不一样? 2022-08-05
- 深圳建站公司谈交换链接中的小花招 2022-05-28