使用python爬取百度贴吧的案例-创新互联
使用python爬取百度贴吧的案例?这个问题可能是我们日常学习或工作经常见到的。希望通过这个问题能让你收获颇深。下面是小编给大家带来的参考内容,让我们一起来看看吧!

写在最前面:
我们用 urllib 爬取页面,再用BeautifulSoup提取有用信息,最后用 xlsxwriter 把获取的信息 写入到excel表。
一、技术列表
python 基础
xlsxwriter 用来写入excel文件的
urllib——python内置爬虫工具
BeautifulSoup解析提取数据
二、找到目标页面
https://tieba.baidu.com/f?kw=%E6%97%85%E6%B8%B8&ie=utf-8&pn=0

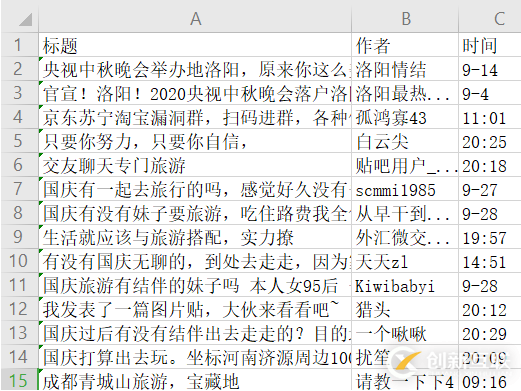
三、输出结果
四、安装必要的库
win+R 打开运行
输出cmd 进入控制台
分别安装beautifulsoup4,lxml,xlsxwriter
pip install lxml
pip install beautifulsoup4
pip install xlsxwriter
五、分析页面
1. 页面规律
我们单击分页按钮,拿到页面最后一个参数的规律
第二页:https://tieba.baidu.com/f?kw=旅游&ie=utf-8&pn= 50
第三页:https://tieba.baidu.com/f?kw=旅游&ie=utf-8&pn= 100
第四页:https://tieba.baidu.com/f?kw=旅游&ie=utf-8&pn= 150


2. 页面信息
旅游信息列表打开网页https://tieba.baidu.com/f?kw=旅游&ie=utf-8&pn= 50按键盘F12键或者 鼠标右键"检查元素"(我用的谷歌chrome浏览器)
发现所有旅游列表都有个共同的class类名j_thread_list

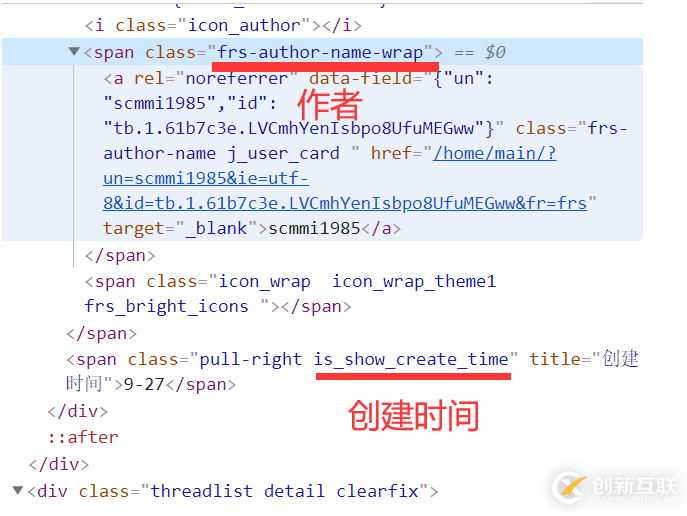
作者与创建时间
作者的class为frs-author-name
创建时间的class为is_show_create_time
标题
标题的class为j_th_tit

六、全部代码
import xlsxwriter
# 用来写入excel文件的
import urllib.parse
# URL编码格式转换的
import urllib.request
# 发起http请求的
from bs4 import BeautifulSoup
# css方法解析提取信息
url='https://tieba.baidu.com/f?kw='+urllib.parse.quote('旅游')+'&ie=utf-8&pn='
# 百度贴吧旅游信息
# parse.quote("旅游") # 结果为%E6%97%85%E6%B8%B8
herders={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36', 'Referer':'https://tieba.baidu.com/','Connection':'keep-alive'}
# 请求头信息
data = []
# 所有爬虫的数据都存放到 这个data列表里面
"""
getList 获取分页中的列表信息
url 分页地址
"""
def getList(url):
req = urllib.request.Request(url,headers=herders)
# 设置请求头
response=urllib.request.urlopen(req)
# 发起请求得到 响应结果response
htmlText = response.read().decode("utf-8").replace("<!--","").replace("-->","")
# htmlText = 响应结果read读取.decode 转换为utf文本.replace 替换掉html中的注释
# 我们需要的结果在注释中,所以要先替换掉注释标签 <!-- -->
html = BeautifulSoup(htmlText,"lxml")
# 创建beautifulSoup对象
thread_list=html.select(".j_thread_list")
# 获取到所有的旅游类别
# 遍历旅游列表
for thread in thread_list:
title = thread.select(".j_th_tit")[0].get_text()
author = thread.select(".frs-author-name")[0].get_text()
time= thread.select(".is_show_create_time")[0].get_text()
# 提取标题,作者,事件
print(title) # 打印标签
data.append([title,author,time])
# 追加到总数据中
"""
获取到所有的分页地址,大5页
url 页面地址
p=5 最多5页
"""
def getPage(url,p=5):
for i in range(5):
link = url+str(i*50)
# 再一次拼接 第1页0 第2页50 第3页100 第4页150
getList(link)
# 执行获取页面函数getList
"""
写入excel文件
data 被写入的数据
"""
def writeExecl(data):
lens = len(data)
# 获取页面的长度
workbook = xlsxwriter.Workbook('travel.xlsx')
# 创建一个excel文件
sheet = workbook.add_worksheet()
# 添加一张工作表
sheet.write_row("A1",["标题","作者","时间"])
# 写入一行标题
for i in range(2, lens + 2):
sheet.write_row("A"+str(i),data[i - 2])
# 遍历data 写入行数据到excel
workbook.close()
# 关闭excel文件
print("xlsx格式表格写入数据成功!")
"""
定义主函数
"""
def main():
getPage(url,5) #获取分页
writeExecl(data) #写入数据到excel
# 如果到模块的名字是__main__ 执行main主函数
if __name__ == '__main__':
main()
七、单词表
main 主要的
def (define) 定义
getPage 获取页面
writeExcel 写入excel
workbook 工作簿
sheet 表
write_row 写入行
add 添加
close 关闭
len length长度
data 数据
range 范围
str (string)字符串
append 追加
author 作者
select 选择
Beautiful 美丽
Soup 糖
herders 头信息
response 响应
read 读
decode 编码
Request 请求
parse 解析
quote 引用
感谢各位的阅读!看完上述内容,你们对使用python爬取百度贴吧的案例大概了解了吗?希望文章内容对大家有所帮助。如果想了解更多相关文章内容,欢迎关注创新互联-成都网站建设公司行业资讯频道。
当前标题:使用python爬取百度贴吧的案例-创新互联
标题路径:https://www.cdcxhl.com/article14/djeede.html
成都网站建设公司_创新互联,为您提供手机网站建设、品牌网站设计、做网站、定制网站、网站导航、营销型网站建设
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 虹口网页设计公司关于CSS布局 2021-07-03
- 怎么选择一家合适的网页设计公司 2021-09-05
- 专业成都网页设计公司来帮助制作企业网站 2023-03-22
- 如何选择北京网页设计公司 2020-12-09
- 企业网页设计价格方案,不同网页设计公司的价格时间工期 2021-05-25
- 企业网页设计公司设计网页的四大效益 2016-10-25
- 网站建设、网页设计公司建站报价之间为何差距这么大? 2022-06-20
- 海外顶级网页设计公司 2019-11-27
- 成都网页设计公司需从哪些方面开展工作? 2016-10-14
- 佛山网页设计公司:设计网页这些问题你都注意了吗? 2021-08-23
- 高端网页设计公司4个简单的网页技巧 2015-09-14
- 网页设计公司究竟设计的是什么呢? 2016-11-13