主流时序数据库分析及选型-创新互联
- 一、当前主流的时序数据库
- 二、主流时序数据库分析
- 1、[Influxdb](https://docs.influxdata.com/influxdb)
- 2、[Timescale](https://docs.timescale.com/)
- 3、[Apache Druid](https://druid.apache.org/docs/latest/design/index.html)
- 4、[Kdb+](https://code.kx.com/home/)
- 5、[Graphite](https://graphite.readthedocs.io/en/stable/)
- 6、[RRDtool](https://oss.oetiker.ch/rrdtool/doc/)
- 7、[OpenTSDB](http://opentsdb.net/docs/build/html/index.html)
- 8、[Prometheus](https://prometheus.io/docs/introduction/overview/)
- 9、[DolphinDB](http://opentsdb.net/docs/build/html/index.html)
- 10、[IoTDB](https://iotdb.apache.org/zh/UserGuide/Master/QuickStart/QuickStart.html)
- 11、[TDengine](https://docs.tdengine.com/)
- 12、云厂商
- 三、优缺点对比
因为个人用的go,所以调研及对比主要针对适配了go语言的数据库。
目前创新互联已为超过千家的企业提供了网站建设、域名、网站空间、网站托管运营、企业网站设计、邵阳网站维护等服务,公司将坚持客户导向、应用为本的策略,正道将秉承"和谐、参与、激情"的文化,与客户和合作伙伴齐心协力一起成长,共同发展。一、当前主流的时序数据库排名参考于https://db-engines.com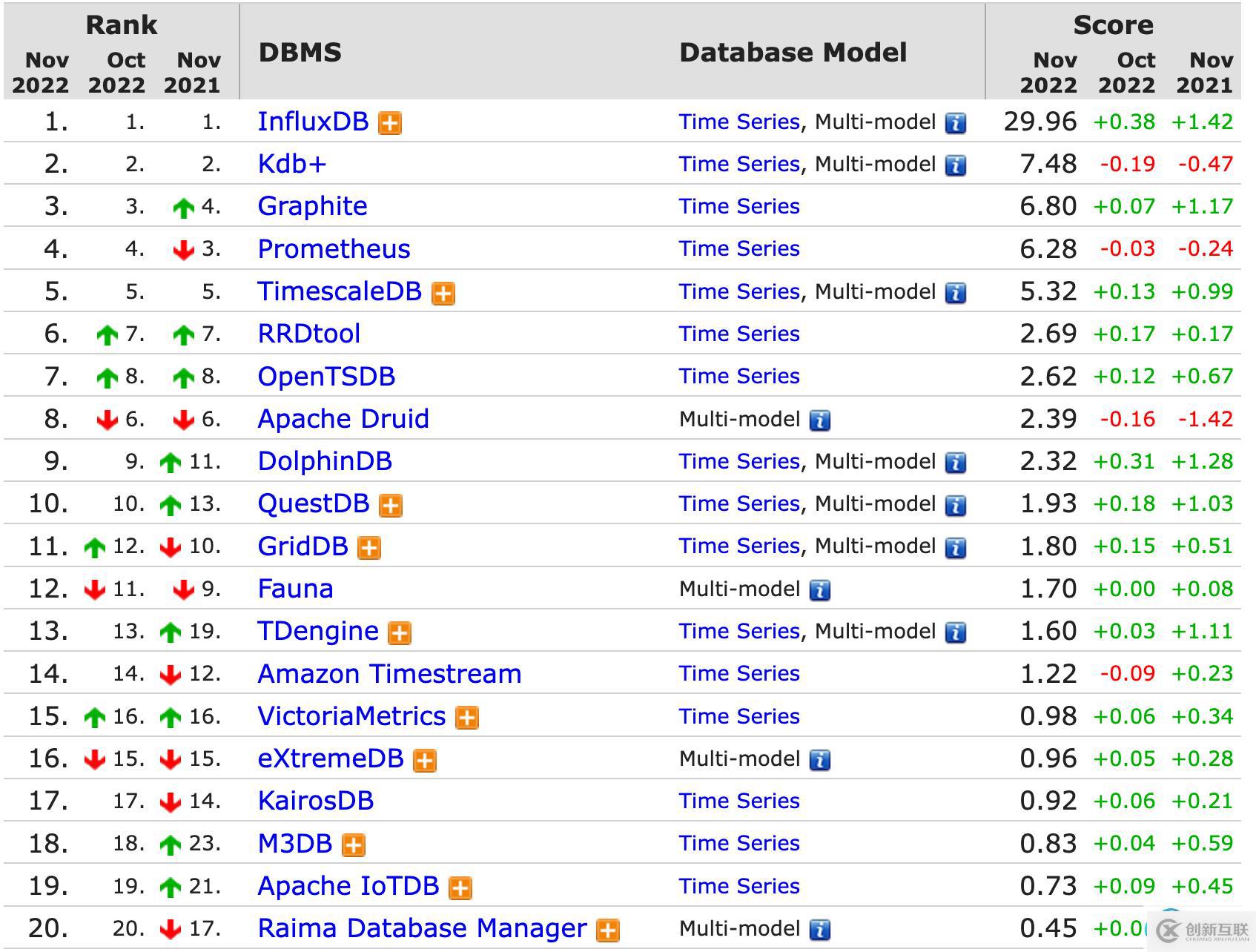
流行度很高,支持Go语言,社区活跃度高
特性:
- 高效的时间序列数据写入性能。自定义TSM引擎,快速数据写入和高效数据压缩;
- 无额外存储依赖;
- 简单,高性能的HTTP查询和写入API;
- 以插件方式支持许多不同协议的数据摄入,如:graphite,collectd,和openTSDB;
- SQL-like查询语言,简化查询和聚合操作;
- 索引Tags,支持快速有效的查询时间序列;
- 保留策略有效去除过期数据;
- 连续查询自动计算聚合数据,使频繁查询更有效。
缺点:
- 分布式未开源。
一个基于传统关系型数据库postgresql改造的时间序列数据库。
优点:
PostgreSQL原生支持的所有SQL,包含完整SQL接口(包括辅助索引,非时间聚合,子查询,JOIN,窗口函数);
用PostgreSQL的客户端或工具,可以直接应用到该数据库,不需要更改;
时间为导向的特性,API功能和相应的优化;
透明时间/空间分区,用于放大(单个节点)和扩展;
高数据写入速率(包括批量提交,内存中索引,事务支持,数据备份支持);
单个节点上的大小合适的块(二维数据分区),以确保即使在大数据量时即可快速读取;
块之间和服务器之间的并行操作。
劣势:
- 因为TimescaleDB没有使用列存技术,它对时序数据的压缩效果不太好,压缩比最高在4X左右,长远考虑,专业的TSDB必须是从底层存储面向时序数据的特征进行针对性设计和优化的;
- 目前暂时不完全支持分布式的扩展(正在开发相关功能),所以会对服务器单机性能要求较高。
【不支持GO】
Druid是一个实时在线分析系统(LOAP)。其架构融合了实时在线数据分析,全文检索系统和时间序列系统的特点,使其可以满足不同使用场景的数据存储需求,在极致性能和数据schema的灵活性方面有一定的平衡。
优点:
- 采用列式存储:支持高效扫描和聚合,易于压缩数据;
- 可伸缩的分布式系统:Druid自身实现可伸缩,可容错的分布式集群架构。部署简单;
- 强大的并行能力:Druid各集群节点可以并行地提供查询服务;
- 实时和批量数据摄入:Druid可以实时摄入数据,如通过Kafka。也可以批量摄入数据,如通过Hadoop导入数据;
- 自恢复,自平衡,易于运维:Druid自身架构即实现了容错和高可用。不同的服务节点可以根据响应需求添加或减少节点;
- 容错架构,保证数据不丢失:Druid数据可以保留多副本。另外可以采用HDFS作为深度存储,来保证数据不丢失;
- 索引:Druid对String列实现反向编码和Bitmap索引,所以支持高效的filter和groupby;
- 基于时间分区:Druid对原始数据基于时间做分区存储,所以Druid对基于时间的范围查询将更高效;
- 自动预聚合:Druid支持在数据摄入期就对数据进行预聚合处理。
缺点:
- 不支持多时间维度,所有维度为String类型;
- 只支持流式写入,不支持实时数据更新,更新可以使用批处理作业完成;
- 不支持精准去重。
kdb+ 号称最快的内存数据库之一。列式存储的特性,使得对于某个列的统计分析操作异常方便。
优点:
- 单体架构,轻松支持 billion以上数据;
- 分布式扩展,无性能损耗;
- 超低延迟+高并发支持;
- 列式存储+内存数据库;
- 灵活的Q语言,内置非常多的统计计算方法。
缺点:
- 搭配的Q 语言,学习难度较高。
【不支持GO】
Graphite通常用于监控基础设施级别的度量,比如CPU、内存、I/O利用率、网络吞吐量和延迟,当然Graphite在应用程序级的度量和业务级的度量方面也很不错。
6、RRDtool【不支持GO】
RRDtool 代表 “Round Robin Database tool” , 所谓的“Round Robin” 其实是一种存储数据的方式,使用固定大小的空间来存储数据,并有一个指针指向新的数据的位置。
优点:
- 使用RRD(Round Robin Database)存储格式,数据等于放在数据库中,可以方便地调用。比如,将一个RRD文件中的数据与另一个RRD文件中的数据相加;
- 可以定义任意时间段画图,可以用半年数据画一张图,也可以用半小时内的数据画一张图;
- 能画任意个DS,多种图形显示方式;
- 数据存储与绘图分开,减轻系统负载;
- 能任意处理RRD文件中的数据,比如,在浏览监测中我们需要将数据由Bytes转化为bits,可以将原始数据乘8。
缺点:
- RRDTool的作用只是存储数据和画图,它没有MRTG中集成的数据采集功能;
- 在命令行下的使用非常复杂,参数极多;
- 无用户、图像管理功能。
OpenTSDB 是一个开源框架,使用 HBase 作为核心平台来存储和检索所收集的指标数据,可以灵活地增加指标,也可以支持采集上万台机器和上亿个数据点,具有高可扩展性。
优点:
- 在数据压缩上,时间戳采用 delta 编码进行压缩,数据值采用 XOR 进行压缩;
- 存储与计算解耦,为 IoT 场景海量数据、动态热点的数据特征量身打造,方便按照并发度和存储量按需独立扩容。采用分布式架构,支持横向水平扩展;
- 较强的时序数据计算能力,主要体现为:插值,缺失的数据点,支持线性插值数据补全;
- 降精度,支持预降精度和实时降精度计算,满足高效查询需求;
- 空间聚合,支持按照不同的 tag 进行空间聚合和分组计算。
缺点:
- 数据查询和分析的能力不足,不是所有的查询场景都能适用,在GroupBy和Downsampling的查询上,也未提供Pre-aggregation和Auto-rollup的支持,查询效率不如其他数据库;
- 基于HBase构建,依赖Hadoop生态太重。
Prometheus 是一个开源的服务监控系统和时间序列数据库。
优点:
- 具有丰富的查询语言;
- 可视化数据展示;
- 集成监控和报警功能;
- 维护简单。
缺点:
- 没有集群解决方案;
- 聚合分析能力较弱;
- 为运行时正确的监控数据准备的,不能解决大容量存储问题,无法做到100%精准,存在由内核故障、刮擦故障等因素造成的微小误差。
DolphinDB是一款高性能分布式时序数据库。DolphinDB集成了功能强大的编程语言和高容量高速度的流数据分析系统,为海量数据(特别是时间序列数据)的快速存储、检索、分析及计算提供一站式解决方案。
优点:
- 列式混合引擎(基于内存和磁盘),支持单表百万级别的分区数,大大缩减对海量数据的检索响应时间;
- 内嵌的分布式文件系统自动管理分区数据及其副本,为分布式计算提供负载均衡和容错能力;
- 支持命令式编程、函数式编程、向量编程、SQL编程和RPC(远程函数调用)编程;
- 内置Web服务器,用于集群管理、性能监控和数据访问。
缺点:
- 安装复杂;
- 知乎反馈
IoTDB 是一个用于管理大量时间序列数据的数据库,它采用了列式存储、数据编码、预计算和索引技术,具有类 SQL 的接口,可支持每秒每节点写入数百万数据点,可以秒级获得超过数万亿个数据点的查询结果。主要面向工业界的IoT场景。
优点:
- 压缩比高(优于1:10无损压缩),可大大节省服务器硬件成本;
- 开箱即用,跨平台部署,仅依靠 JDK/JRE;
- 类sql查询,学习成本低。
缺点:
- 暂时不支持集群;
- TSFile(一种列存储文件格式,用于访问,压缩和存储时序数据)结构版本单一。
TDengine 是一款开源、高性能、分布式、支持 SQL 的时序数据库,其时序数据库核心代码包括集群功能全部开源,同时 TDengine 还带有内建的缓存、流式计算、数据订阅等系统功能,能大幅减少研发和运维的复杂度
优点:
- 支持水平扩展,有开源的分布式集群解决方案;
- 性能测试中读写性能远高于InfluxDB,压缩率高;
- 采用标准 SQL 做查询语言(不完全兼容),并且采用关系数据库模型,学习成本低;
缺点:
- 单条插入性能很低,必须成批写入,增加了系统开发和维护的复杂度与运营成本
- 高质量的服务需要付费
阿里云
TSDB for InfluxDB,自研的TSDB引擎,将单个数据点的平均使用存储空间降为1~2个字节,可以降低90%存储使用空间,同时加快数据写入的速度,相较于开源的 OpenTSDB 和 InfluxDB,读写效率提升了数倍,同时兼容 OpenTSDB 数据访问协议。
华为云
GaussDB for Influx,基于InfluxDB进行深度优化改造,在架构、性能和数据压缩等方面进行了技术创新
MRS,基于IoTDB进行优化,千万级数据点秒级写入,TB级数据毫秒级查询;优化后的数据压缩比可达百倍,进一步节省存储空间和成本。
腾讯云
TencentDB for CTSDB,一款分布式、可扩展、支持近实时数据搜索与分析的时序数据库,借鉴了ElasticSearch内核深度优化经验,兼容 Elasticsearch 常用的 API 接口和生态,性能方面可以做到每秒千万级数据点写入,亿级数据秒级分析。
| InfluxDB | OpenTSDB | DolphinDB | TDengine | |
|---|---|---|---|---|
| 成熟度 | 成熟 | 一般 | 一般 | 一般 |
| 集群 | 付费支持 | 支持(HBase) | 支持 | 支持 |
| 读写速度 | 慢 | 较快 | 较快 | 快 |
| 使用复杂性 | 一般(类sql) | 较高 | 一般(类sql) | 低(标准sql) |
| 部署复杂性 | 简单 | 复杂 | 较复杂 | 较简单 |
参考链接:
https://db-engines.com/en/system/DolphinDB%3BInfluxDB%3BOpenTSDB%3BTDengine
http://jianfei.blog.csdn.net/article/details/127386117
https://bbs.huaweicloud.com/blogs/300156
https://blog.csdn.net/xuruilll/article/details/125808992
如有不对,烦请指出,感谢~
你是否还在寻找稳定的海外服务器提供商?创新互联www.cdcxhl.cn海外机房具备T级流量清洗系统配攻击溯源,准确流量调度确保服务器高可用性,企业级服务器适合批量采购,新人活动首月15元起,快前往官网查看详情吧
名称栏目:主流时序数据库分析及选型-创新互联
URL地址:https://www.cdcxhl.com/article14/csssge.html
成都网站建设公司_创新互联,为您提供做网站、小程序开发、网站收录、用户体验、品牌网站设计、网站导航
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 公司涉足互联网技术第一件要做的事便是企业建站 2015-01-18
- 【西昌网站建设】中小企业建站应该怎么做 2014-11-29
- 响应式企业建站应该注意什么事项 2021-04-26
- 企业建站前的网站规划图 2021-03-05
- 企业建站初期应该如何做网站优化? 2016-08-31
- 网站建设公司谈企业建站的基本原则 2022-05-18
- 信阳制作企业网站:企业建站时这些细节必须要注意! 2021-08-12
- 东莞建网站:企业建站流程怎么走? 2022-10-19
- 汕头企业建站:做一个完整的网站都是要走哪些流程? 2021-09-10
- 企业建站一定要体现出特色 2016-11-01
- 企业建站需要提供什么资料 2015-09-03
- 贵阳企业建站:关于网站制作的一些建设性总结! 2021-12-19