hadoop分布式部署
Hadoop Cluster中的角色:
香格里拉ssl适用于网站、小程序/APP、API接口等需要进行数据传输应用场景,ssl证书未来市场广阔!成为创新互联的ssl证书销售渠道,可以享受市场价格4-6折优惠!如果有意向欢迎电话联系或者加微信:028-86922220(备注:SSL证书合作)期待与您的合作!
HDFS:
NameNode,NN
SecondaryNameNode,SNN
DataNode,DN
YARN:
ResourceManager
NodeManager
生产环境中hadoop分布式部署注意事项:
HDFS集群:
NameNode和Secondary应该分开部署,避免NameNode和SecondaryNode同时出现故障,而无法恢复
DataNode数量至少为3个,因为数据至少要保存3份
YARN集群:
ResourceManager部署在独立的节点上
NodeManager运行在DataNode上
Hadoop集群架构如下图所示:
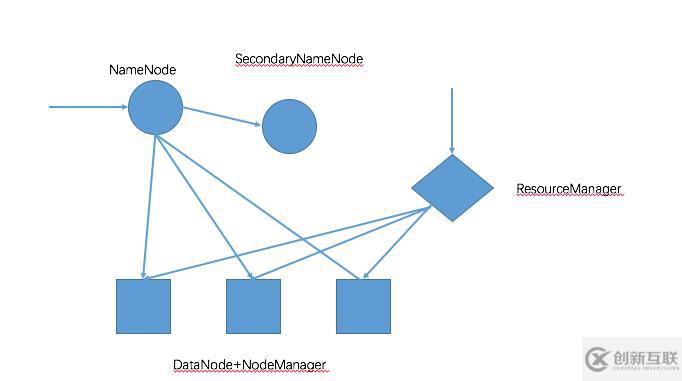
我在测试环境中进行分布式部署时,将NameNode、SecondaryNameNode和ResourceManager三个角色部署在同一服务器Master节点上,
三个从节点部署DataNode和NodeManager
1、配置hosts文件
node1、node2、node3、node4上的/etc/hosts文件中追加以下内容
172.16.2.3 node1.hadooptest.com node1 master 172.16.2.14 node2.hadooptest.com node2 172.16.2.60 node3.hadooptest.com node3 172.16.2.61 node4.hadooptest.com node4
2、创建hadoop用户和组
如果需要通过master节点启动或者停止整个集群,还需要在master节点上配置用于运行服务的用户(如hdfs和yarn)能以密钥的方式通过ssh远程连接到各个从节点
node1、node2、node3、node4上分别执行
useradd hadoop echo 'p@ssw0rd' | passwd --stdin hadoop
登录node1,创建密钥
su - hadoop ssh-keygen -t rsa
将公钥从node1分别上传到node2、node3、node4
ssh-copy-id -i .ssh/id_rsa.pub hadoop@node2 ssh-copy-id -i .ssh/id_rsa.pub hadoop@node3 ssh-copy-id -i .ssh/id_rsa.pub hadoop@node4
注意:master节点也要将公钥传到自己的hadoop账户下,否则启动secondarynamenode时,要输入密码
[hadoop@node1 hadoop]$ node1ssh-copy-id -i .ssh/id_rsa.pub hadoop@0.0.0.0
测试从node1登录到node2、node3、node4
[hadoop@OPS01-LINTEST01 ~]$ ssh node2 'date' Tue Mar 27 14:26:10 CST 2018 [hadoop@OPS01-LINTEST01 ~]$ ssh node3 'date' Tue Mar 27 14:26:13 CST 2018 [hadoop@OPS01-LINTEST01 ~]$ ssh node4 'date' Tue Mar 27 14:26:17 CST 2018
3、配置hadoop环境
node1、node2、node3、node4上都需要执行
vim /etc/profile.d/hadoop.sh
export HADOOP_PREFIX=/bdapps/hadoop
export PATH=$PATH:${HADOOP_PREFIX}/bin:${HADOOP_PREFIX}/sbin
export HADOOP_COMMON_HOME=${HADOOP_PREFIX}
export HADOOP_YARN_HOME=${HADOOP_PREFIX}
export HADOOP_HDFS_HOME=${HADOOP_PREFIX}
export HADOOP_MAPRED_HOME=${HADOOP_PREFIX}node1配置
创建目录
[root@OPS01-LINTEST01 ~]# mkdir -pv /bdapps /data//hadoop/hdfs/{nn,snn,dn}
mkdir: created directory `/bdapps'
mkdir: created directory `/data//hadoop'
mkdir: created directory `/data//hadoop/hdfs'
mkdir: created directory `/data//hadoop/hdfs/nn'
mkdir: created directory `/data//hadoop/hdfs/snn'
mkdir: created directory `/data//hadoop/hdfs/dn'配置权限
chown -R hadoop:hadoop /data/hadoop/hdfs/ cd /bdapps/ [root@OPS01-LINTEST01 bdapps]# ls hadoop-2.7.5 [root@OPS01-LINTEST01 bdapps]# ln -sv hadoop-2.7.5 hadoop [root@OPS01-LINTEST01 bdapps]# cd hadoop [root@OPS01-LINTEST01 hadoop]# mkdir logs
修改hadoop目录下所有文件的属主属组为hadoop,并给logs目录添加写入权限
[root@OPS01-LINTEST01 hadoop]# chown -R hadoop:hadoop ./* [root@OPS01-LINTEST01 hadoop]# ll total 140 drwxr-xr-x 2 hadoop hadoop 4096 Dec 16 09:12 bin drwxr-xr-x 3 hadoop hadoop 4096 Dec 16 09:12 etc drwxr-xr-x 2 hadoop hadoop 4096 Dec 16 09:12 include drwxr-xr-x 3 hadoop hadoop 4096 Dec 16 09:12 lib drwxr-xr-x 2 hadoop hadoop 4096 Dec 16 09:12 libexec -rw-r--r-- 1 hadoop hadoop 86424 Dec 16 09:12 LICENSE.txt drwxr-xr-x 2 hadoop hadoop 4096 Mar 27 14:51 logs -rw-r--r-- 1 hadoop hadoop 14978 Dec 16 09:12 NOTICE.txt -rw-r--r-- 1 hadoop hadoop 1366 Dec 16 09:12 README.txt drwxr-xr-x 2 hadoop hadoop 4096 Dec 16 09:12 sbin drwxr-xr-x 4 hadoop hadoop 4096 Dec 16 09:12 share [root@OPS01-LINTEST01 hadoop]# chmod g+w logs
core-site.xml文件配置
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://master:8020</value> <final>true</final> </property> </configuration>
yarm-site.xml文件配置
注意:yarn-site.xml是ResourceManager角色相关配置。生产环境下该角色和NameNode是应该分开部署的,所以该文件中的master和core-site.xml中的master不是同一台机器。由于我这里是在测试环境中模拟分布式部署,
将NameNode和ResourceManager部署在一台机器上了,所以才会需要在NameNode服务器上配置该文件。
<configuration> <property> <name>yarn.resourcemanager.address</name> <value>master:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>master:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>master:8031</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>master:8033</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>master:8088</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.auxservices.mapreduce_shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <name>yarn.resourcemanager.scheduler.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value> </property> </configuration>
hdfs-site.xml文件配置
修改 dfs.replication 副本保留数量
<configuration> <property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:///data/hadoop/hdfs/nn</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:///data/hadoop/hdfs/dn</value> </property> <property> <name>fs.checkpoint.dir</name> <value>file:///data/hadoop/hdfs/snn</value> </property> <property> <name>fs.checkpoint.edits.dir</name> <value>file:///data/hadoop/hdfs/snn</value> </property> </configuration>
mapred-site.xml文件配置
cp mapred-site.xml.template mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
slaves文件配置
node2 node3 node4
hadoop-env.sh文件配置
export JAVA_HOME=/usr/java/jdk1.8.0_151
配置node2、node3、node4节点
###创建hadoop安装目录,和数据目录以及logs目录,并修改权限
mkdir -pv /bdapps /data/hadoop/hdfs/{nn,snn,dn}
chown -R hadoop.hadoop /data/hadoop/hdfs/
tar zxf hadoop-2.7.5.tar.gz -C /bdapps/
cd /bdapps
ln -sv hadoop-2.7.5 hadoop
cd hadoop
mkdir logs
chmod g+w logs
chown -R hadoop:hadoop ./*配置文件修改
由于我们前面在master节点(node1)已经修改了hadoop相关配置文件,所以可以直接从master节点同步到node2、node3、node4节点上
scp /bdapps/hadoop/etc/hadoop/* node2:/bdapps/hadoop/etc/hadoop/ scp /bdapps/hadoop/etc/hadoop/* node3:/bdapps/hadoop/etc/hadoop/ scp /bdapps/hadoop/etc/hadoop/* node4:/bdapps/hadoop/etc/hadoop/
启动hadoop相关服务
master节点
与伪分布式模式相同,在HDFS集群的NN启动之前需要先初始化其用于处处数据的目录,如果hdfs-site.xml中 dfs.namenode.name.dir属性指定的目录不存在,
格式化命令会自动创建之,如果事先存在,请确保其权限设置正确,此时格式操作会清除其内部的所有数据并重新建立一个新的文件系统。需要以hdfs用户的身份在master节点执行如下命令
hdfs namenode -format
启动集群节点有两种方式:
1、登录到各个节点手动启动服务
2、在master节点控制启动整个集群
集群规模较大时,分别启动各个节点的各个服务会比较繁琐,所以hadoop提供了start-dfs.sh和stop-dfs.sh来启动及停止整个hdfs集群,以及start-yarn.sh和stop-yarn.sh来启动和停止整个yarn集群
[hadoop@node1 hadoop]$start-dfs.sh Starting namenodes on [master] hadoop@master's password: master: starting namenode, logging to /bdapps/hadoop/logs/hadoop-hadoop-namenode-node1.out node4: starting datanode, logging to /bdapps/hadoop/logs/hadoop-hadoop-datanode-node4.out node2: starting datanode, logging to /bdapps/hadoop/logs/hadoop-hadoop-datanode-node2.out node3: starting datanode, logging to /bdapps/hadoop/logs/hadoop-hadoop-datanode-node3.out Starting secondary namenodes [0.0.0.0] hadoop@0.0.0.0's password: 0.0.0.0: starting secondarynamenode, logging to /bdapps/hadoop/logs/hadoop-hadoop-secondarynamenode-node1.out [hadoop@node1 hadoop]$ jps 69127 NameNode 69691 Jps 69566 SecondaryNameNode
登录到datanode节点查看进程
[root@node2 ~]# jps 66968 DataNode 67436 Jps [root@node3 ~]# jps 109281 DataNode 109991 Jps [root@node4 ~]# jps 108753 DataNode 109674 Jps
停止整个集群的服务
[hadoop@node1 hadoop]$ stop-dfs.sh Stopping namenodes on [master] master: stopping namenode node4: stopping datanode node2: stopping datanode node3: stopping datanode Stopping secondary namenodes [0.0.0.0] 0.0.0.0: stopping secondarynamenode
测试
在master节点上,上传一个文件
[hadoop@node1 ~]$ hdfs dfs -mkdir /test [hadoop@node1 ~]$ hdfs dfs -put /etc/fstab /test/fstab [hadoop@node1 ~]$ hdfs dfs -ls -R /test -rw-r--r-- 2 hadoop supergroup 223 2018-03-27 16:48 /test/fstab
登录node2
[hadoop@node2 ~]$ ls /data/hadoop/hdfs/dn/current/BP-1194588190-172.16.2.3-1522138946011/current/finalized/ [hadoop@node2 ~]$
没有fstab文件
登录node3,可以看到fstab文件
[hadoop@node3 ~]$ cat /data/hadoop/hdfs/dn/current/BP-1194588190-172.16.2.3-1522138946011/current/finalized/subdir0/subdir0/blk_1073741825 UUID=dbcbab6c-2836-4ecd-8d1b-2da8fd160694 / ext4 defaults 1 1 tmpfs /dev/shm tmpfs defaults 0 0 devpts /dev/pts devpts gid=5,mode=620 0 0 sysfs /sys sysfs defaults 0 0 proc /proc proc defaults 0 0 dev/vdb1 none swap sw 0 0
登录node4,也可以看到fstab文件
[hadoop@node4 root]$ cat /data/hadoop/hdfs/dn/current/BP-1194588190-172.16.2.3-1522138946011/current/finalized/subdir0/subdir0/blk_1073741825 UUID=dbcbab6c-2836-4ecd-8d1b-2da8fd160694 / ext4 defaults 1 1 tmpfs /dev/shm tmpfs defaults 0 0 devpts /dev/pts devpts gid=5,mode=620 0 0 sysfs /sys sysfs defaults 0 0 proc /proc proc defaults 0 0 dev/vdb1 none swap sw 0 0
结论:由于我们数据保存2份,所以只在node3,node4上有文件副本,node2上没有
启动yarn集群
登录node1(master),执行start-yarn.sh
[hadoop@node1 ~]$ start-yarn.sh starting yarn daemons starting resourcemanager, logging to /bdapps/hadoop/logs/yarn-hadoop-resourcemanager-node1.out node4: starting nodemanager, logging to /bdapps/hadoop/logs/yarn-hadoop-nodemanager-node4.out node2: starting nodemanager, logging to /bdapps/hadoop/logs/yarn-hadoop-nodemanager-node2.out node3: starting nodemanager, logging to /bdapps/hadoop/logs/yarn-hadoop-nodemanager-node3.out [hadoop@node1 ~]$ jps 78115 ResourceManager 71574 NameNode 71820 SecondaryNameNode 78382 Jps
登录node2,执行jps命令,可以看到NodeManager服务已经启动了
[ansible@node2 ~]$ sudo su - hadoop [hadoop@node2 ~]$ jps 68800 DataNode 75400 Jps 74856 NodeManager
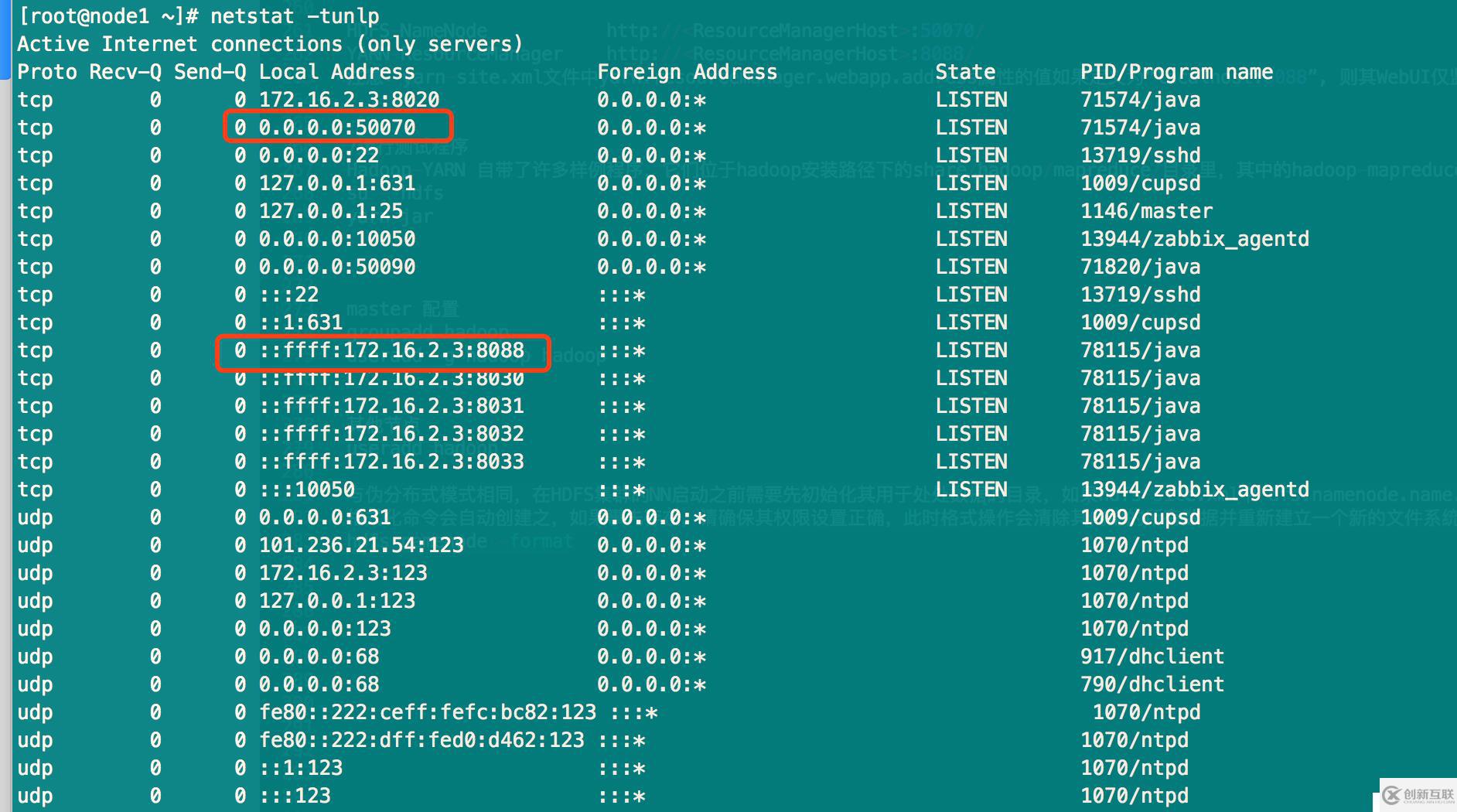
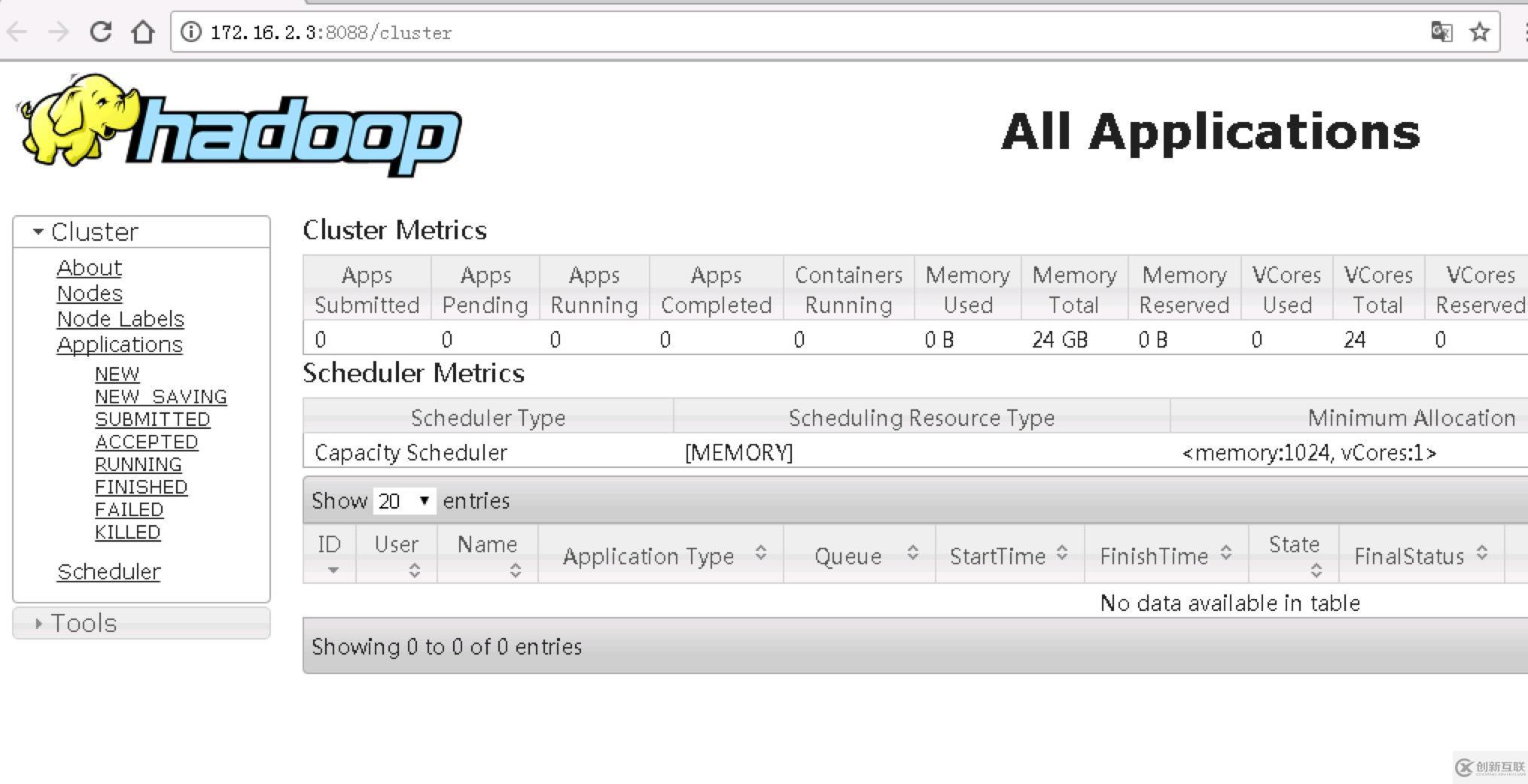
查看Web UI控制台

其他参考文档:
http://www.codeceo.com/understand-hadoop-hbase-hive-spark-distributed-system-architecture.html
当前文章:hadoop分布式部署
标题网址:https://www.cdcxhl.com/article12/jijpdc.html
成都网站建设公司_创新互联,为您提供动态网站、网站导航、企业网站制作、网站内链、App设计、
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 网站被黑百度快照出现垃圾信息怎么办? 2022-09-24
- 网站没排名怎么进行优化 2013-12-31
- 三个方面谈谈自己做成都网站建设时要注意的事项 2023-08-26
- 外链四原则你知道吗 2016-11-01
- 一个网站PHP程序员的成长之路 2021-10-17
- 网站如何提高用户黏性? 2022-05-02
- 网站SEO优化要怎样去突出核心内容 2023-04-13
- 企业网站建设—SSL加密Web开发的主要优点有哪些? 2023-02-06
- 如何选择网站关键词才会让网站成功率更高? 2016-11-09
- 美观大气的网站建设和追求客户体验的网站哪个重要? 2016-10-17
- 蒙大神,我该如何应对政府网站服务器出现的各种故障? 2022-08-17
- 租用美国服务器搭建网站,保证网站安全的手段有哪些? 2023-07-15