如何利用python爬虫调用百度翻译
这篇文章主要为大家展示了“如何利用python爬虫调用百度翻译”,内容简而易懂,条理清晰,希望能够帮助大家解决疑惑,下面让小编带领大家一起研究并学习一下“如何利用python爬虫调用百度翻译”这篇文章吧。
公司主营业务:网站制作、成都网站设计、移动网站开发等业务。帮助企业客户真正实现互联网宣传,提高企业的竞争能力。创新互联建站是一支青春激扬、勤奋敬业、活力青春激扬、勤奋敬业、活力澎湃、和谐高效的团队。公司秉承以“开放、自由、严谨、自律”为核心的企业文化,感谢他们对我们的高要求,感谢他们从不同领域给我们带来的挑战,让我们激情的团队有机会用头脑与智慧不断的给客户带来惊喜。创新互联建站推出西盟免费做网站回馈大家。
首先我们打开百度翻译:
然后按F12,打开调试,然后点击network
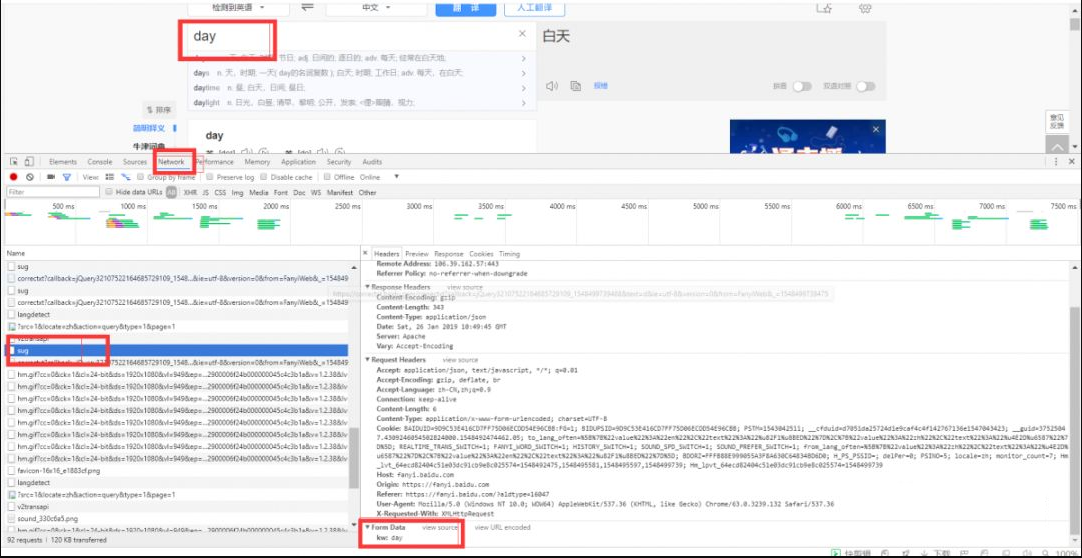
经过我们的分析,我们可以分析到百度翻译的真实post提交页面是Request URL:https://fanyi.baidu.com/sug 并且我们可以发现form data 里面有一个键值对kw:day
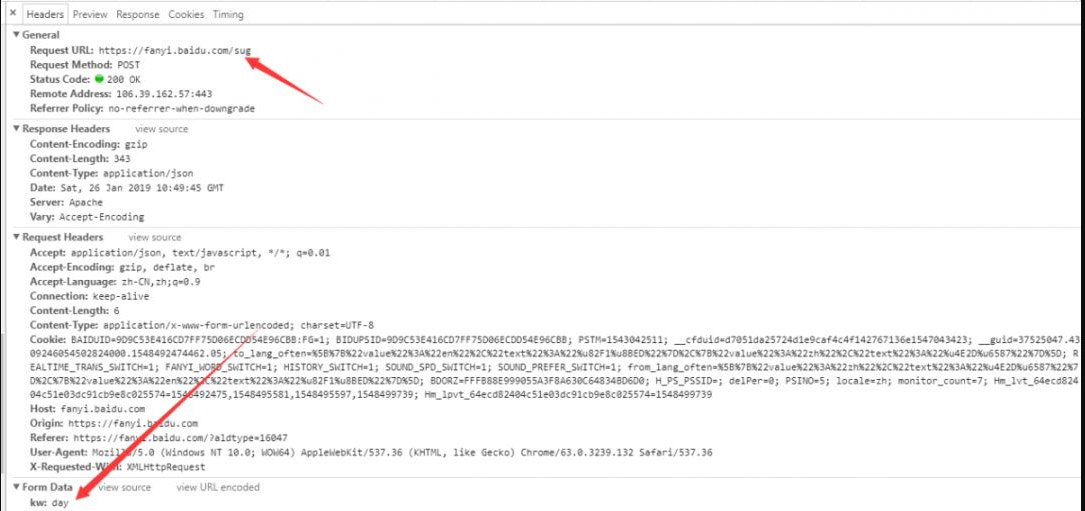
经过初步分析,我们应该有个大概的思路了,无非就是通过这个网址,我们post提交一些数据给他,然后他会返回一个值给我们(其实到后面我们知道这个数据它是通过json格式返回给我们的)
1.首先我们都要导入我们需要的库以及定义一下我们的网址和要翻译的单词(这里我们是用户输入)
from urllib import request, parse
import json
baseurl = "https://fanyi.baidu.com/sug"
word = input("请输入您想输入的单词:")2.因为我们通过上面的分析,知道了我们传给它的值(也就是我们要翻译的单词)是通过键值对的形式来传递的,所以我们就可以使用python里面的字典格式进行定义
# 我们需要传送过去的数据
datas = {
'kw': word
}3.然后我们会通过parse来对这个datas进行编码,因为此时的字典类型是字符串类型,我们传送过去的应该是一个bytes类型,如果不进行编码,后面会报错滴!
# 对数据进行编码
data = parse.urlencode(datas).encode()4.其次,我们要写出访问百度翻译网站的headers,这个headers可以模拟浏览器进行访问,当然我们这种访问只需要写出我们传输的值得长度就够了,其他的参数没有必要去写。
# 写http头部,至少需要Content-Length
headers = {
# 此处为编码后的长度
'Content-Length': len(data),
}5.我们把要传输的数据(单词)和访问该网站的headers写好了之后,就进行最关键的一步,就是把我们写好的这些东西传输到百度翻译的网站上
# 将数据传送
req = request.Request(url=baseurl, data=data, headers=headers)
res = request.urlopen(req)我们首先使用request里面的Request对象将 url网址,data数据, headers头文件传入到req对象。然后再将req这个对象写入request的urlopen。
6. 此时,post数据部分我们已经完成了,res就是返回给我们的数据对象。我们再通过read方法,把这个返回的数据对象读取出来,然后通过decode方法进行编码(此时编码后就成了一个json格式的数据),最后我们将它进行json格式解析。
json_data = res.read()
json_data = json_data.decode()
json_data = json.loads(json_data)我们打印一下json_data

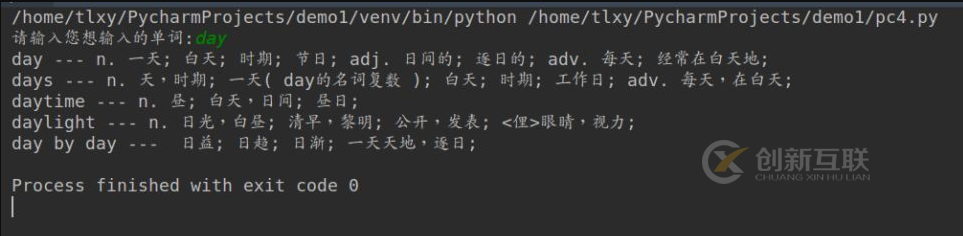
7.最后一步就是将我们用户想看到的东西提取出来,我们分析这个json里面的data所对应的值是一个list对象,所以我们提取data的值之后就可以像list一样去处理数据了!
data_list = json_data.get('data')
for item in data_list:
print(item['k'], '---', item['v'])最后结果:
'''
利用爬虫调用百度翻译----power:IT资源君
'''
from urllib import request, parse
import json
if __name__ == '__main__':
baseurl = "https://fanyi.baidu.com/sug"
word = input("请输入您想输入的单词:")
# 我们需要传送过去的数据
datas = {
'kw': word
}
# 对数据进行编码
data = parse.urlencode(datas).encode()
# 写http头部,至少需要Content-Length
headers = {
# 此处为编码后的长度
'Content-Length': len(data),
}
# 将数据传送
req = request.Request(url=baseurl, data=data, headers=headers)
res = request.urlopen(req)
json_data = res.read()
json_data = json_data.decode()
json_data = json.loads(json_data)
# data里面是一个list
data_list = json_data.get('data')
for item in data_list:
print(item['k'], '---', item['v'])以上是“如何利用python爬虫调用百度翻译”这篇文章的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注创新互联行业资讯频道!
分享名称:如何利用python爬虫调用百度翻译
当前URL:https://www.cdcxhl.com/article12/ihgedc.html
成都网站建设公司_创新互联,为您提供标签优化、营销型网站建设、品牌网站设计、App设计、网站设计公司、动态网站
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 怎样利用chatGPT快速赚钱? 2023-05-05
- 马云回国,首谈ChatGPT。又是新一个风口? 2023-05-28
- ChatGPT是什么 2023-02-20
- ChatGPT的应用ChatGPT对社会的利弊影响 2023-02-20
- ChatGPT是什么?ChatGPT是聊天机器人吗? 2023-05-05
- 爆红的ChatGPT,谁会丢掉饭碗? 2023-02-20
- ChatGPT的发展历程 2023-02-20
- 火爆的ChatGPT,来聊聊它的热门话题 2023-02-20