Python的爬虫与反爬虫-创新互联
这篇文章主要讲解了Python的爬虫与反爬虫,内容清晰明了,对此有兴趣的小伙伴可以学习一下,相信大家阅读完之后会有帮助。

爬虫与发爬虫的厮杀,一方为了拿到数据,一方为了防止爬虫拿到数据,谁是最后的赢家?
重新理解爬虫中的一些概念
- 爬虫:自动获取网站数据的程序
- 反爬虫:使用技术手段防止爬虫程序爬取数据
- 误伤:反爬虫技术将普通用户识别为爬虫,这种情况多出现在封ip中,例如学校网络、小区网络再或者网络网络都是共享一个公共ip,这个时候如果是封ip就会导致很多正常访问的用户也无法获取到数据。所以相对来说封ip的策略不是特别好,通常都是禁止某ip一段时间访问。
- 成本:反爬虫也是需要人力和机器成本
- 拦截:成功拦截爬虫,一般拦截率越高,误伤率也就越高
反爬虫的目的
- 初学者写的爬虫:简单粗暴,不管对端服务器的压力,甚至会把网站爬挂掉了
- 数据保护:很多的数据对某些公司网站来说是比较重要的不希望被别人爬取
- 商业竞争问题:这里举个例子是关于京东和天猫,假如京东内部通过程序爬取天猫所有的商品信息,从而做对应策略这样对天猫来说就造成了非常大的竞争
爬虫与反爬虫大战
上有政策下有对策,下面整理了常见的爬虫大战策略
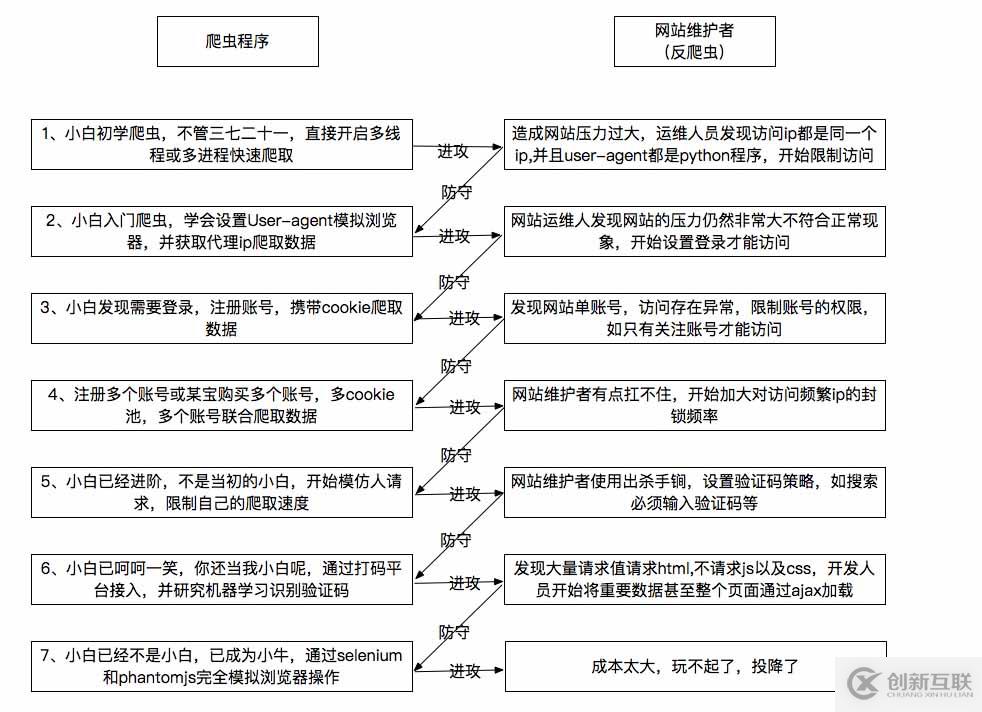
看完上述内容,是不是对Python的爬虫与反爬虫有进一步的了解,如果还想学习更多内容,欢迎关注创新互联-成都网站建设公司行业资讯频道。
网页标题:Python的爬虫与反爬虫-创新互联
本文网址:https://www.cdcxhl.com/article12/dcdjgc.html
成都网站建设公司_创新互联,为您提供电子商务、网站改版、Google、网站维护、定制开发、移动网站建设
声明:本网站发布的内容(图片、视频和文字)以用户投稿、用户转载内容为主,如果涉及侵权请尽快告知,我们将会在第一时间删除。文章观点不代表本网站立场,如需处理请联系客服。电话:028-86922220;邮箱:631063699@qq.com。内容未经允许不得转载,或转载时需注明来源: 创新互联

- 构建网站时这样做可以提升用户体验 2021-12-16
- 网站做好用户体验的6大必备准则 2021-09-15
- 网站制作中如何增进用户体验度 2021-11-09
- 企业建网站加强用户体验感 2021-12-20
- 用户体验的要素如何体现在网站设计中 2022-08-28
- 哪些因素会对网站的用户体验造成影响 2016-08-18
- 网站用户体验应该如何提高 2022-06-21
- 如何利用“卡片式设计”提升用户体验 2022-06-03
- 浅谈良好用户体验的要素 2021-08-19
- 高级用户体验设计师有哪些习惯 2020-07-22
- 深圳网站建设有哪些特点能改善用户体验 2021-08-14
- 营销型网站需注重用户体验 2013-07-06